 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable and Efficient Large-Scale Log Analysis with LLMs: An IT Software Support Case Study
Nov 17, 2025IT environments typically have logging mechanisms to monitor system health and detect issues. However, the huge volume of generated logs makes manual inspection impractical, highlighting the importance of automated log analysis in IT Software Support. In this paper, we propose a log analytics tool that leverages Large Language Models (LLMs) for log data processing and issue diagnosis, enabling the generation of automated insights and summaries. We further present a novel approach for efficiently running LLMs on CPUs to process massive log volumes in minimal time without compromising output quality. We share the insights and lessons learned from deployment of the tool - in production since March 2024 - scaled across 70 software products, processing over 2000 tickets for issue diagnosis, achieving a time savings of 300+ man hours and an estimated $15,444 per month in manpower costs compared to the traditional log analysis practices.
MathBuddy: A Multimodal System for Affective Math Tutoring
Aug 27, 2025The rapid adoption of LLM-based conversational systems is already transforming the landscape of educational technology. However, the current state-of-the-art learning models do not take into account the student's affective states. Multiple studies in educational psychology support the claim that positive or negative emotional states can impact a student's learning capabilities. To bridge this gap, we present MathBuddy, an emotionally aware LLM-powered Math Tutor, which dynamically models the student's emotions and maps them to relevant pedagogical strategies, making the tutor-student conversation a more empathetic one. The student's emotions are captured from the conversational text as well as from their facial expressions. The student's emotions are aggregated from both modalities to confidently prompt our LLM Tutor for an emotionally-aware response. We have effectively evaluated our model using automatic evaluation metrics across eight pedagogical dimensions and user studies. We report a massive 23 point performance gain using the win rate and a 3 point gain at an overall level using DAMR scores which strongly supports our hypothesis of improving LLM-based tutor's pedagogical abilities by modeling students' emotions.
ITBench: Evaluating AI Agents across Diverse Real-World IT Automation Tasks
Feb 07, 2025



Realizing the vision of using AI agents to automate critical IT tasks depends on the ability to measure and understand effectiveness of proposed solutions. We introduce ITBench, a framework that offers a systematic methodology for benchmarking AI agents to address real-world IT automation tasks. Our initial release targets three key areas: Site Reliability Engineering (SRE), Compliance and Security Operations (CISO), and Financial Operations (FinOps). The design enables AI researchers to understand the challenges and opportunities of AI agents for IT automation with push-button workflows and interpretable metrics. ITBench includes an initial set of 94 real-world scenarios, which can be easily extended by community contributions. Our results show that agents powered by state-of-the-art models resolve only 13.8% of SRE scenarios, 25.2% of CISO scenarios, and 0% of FinOps scenarios. We expect ITBench to be a key enabler of AI-driven IT automation that is correct, safe, and fast.
Learning Representations on Logs for AIOps
Aug 18, 2023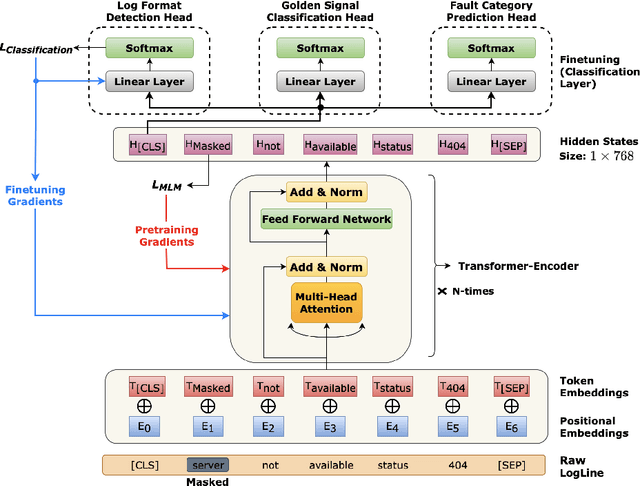



AI for IT Operations (AIOps) is a powerful platform that Site Reliability Engineers (SREs) use to automate and streamline operational workflows with minimal human intervention. Automated log analysis is a critical task in AIOps as it provides key insights for SREs to identify and address ongoing faults. Tasks such as log format detection, log classification, and log parsing are key components of automated log analysis. Most of these tasks require supervised learning; however, there are multiple challenges due to limited labelled log data and the diverse nature of log data. Large Language Models (LLMs) such as BERT and GPT3 are trained using self-supervision on a vast amount of unlabeled data. These models provide generalized representations that can be effectively used for various downstream tasks with limited labelled data. Motivated by the success of LLMs in specific domains like science and biology, this paper introduces a LLM for log data which is trained on public and proprietary log data. The results of our experiments demonstrate that the proposed LLM outperforms existing models on multiple downstream tasks. In summary, AIOps powered by LLMs offers an efficient and effective solution for automating log analysis tasks and enabling SREs to focus on higher-level tasks. Our proposed LLM, trained on public and proprietary log data, offers superior performance on multiple downstream tasks, making it a valuable addition to the AIOps platform.
ArgFuse: A Weakly-Supervised Framework for Document-Level Event Argument Aggregation
Jun 21, 2021
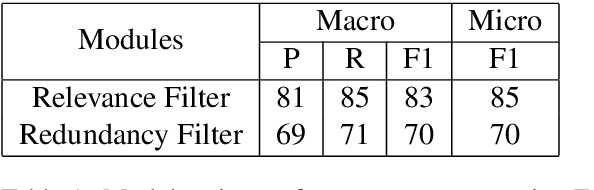

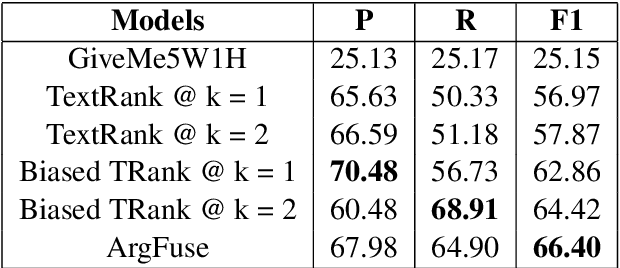
Most of the existing information extraction frameworks (Wadden et al., 2019; Veysehet al., 2020) focus on sentence-level tasks and are hardly able to capture the consolidated information from a given document. In our endeavour to generate precise document-level information frames from lengthy textual records, we introduce the task of Information Aggregation or Argument Aggregation. More specifically, our aim is to filter irrelevant and redundant argument mentions that were extracted at a sentence level and render a document level information frame. Majority of the existing works have been observed to resolve related tasks of document-level event argument extraction (Yang et al., 2018a; Zheng et al., 2019a) and salient entity identification (Jain et al.,2020) using supervised techniques. To remove dependency from large amounts of labelled data, we explore the task of information aggregation using weakly-supervised techniques. In particular, we present an extractive algorithm with multiple sieves which adopts active learning strategies to work efficiently in low-resource settings. For this task, we have annotated our own test dataset comprising of 131 document information frames and have released the code and dataset to further research prospects in this new domain. To the best of our knowledge, we are the first to establish baseline results for this task in English. Our data and code are publicly available at https://github.com/DebanjanaKar/ArgFuse.
Event Argument Extraction using Causal Knowledge Structures
May 02, 2021
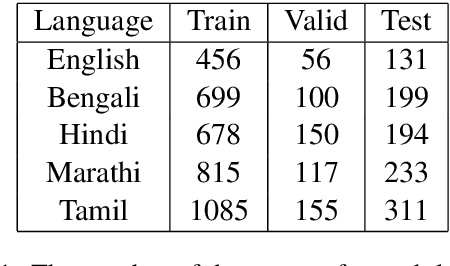
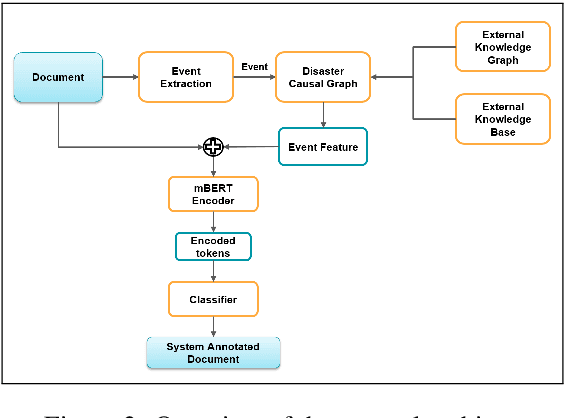
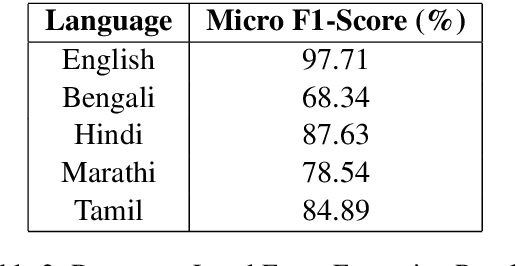
Event Argument extraction refers to the task of extracting structured information from unstructured text for a particular event of interest. The existing works exhibit poor capabilities to extract causal event arguments like Reason and After Effects. Furthermore, most of the existing works model this task at a sentence level, restricting the context to a local scope. While it may be effective for short spans of text, for longer bodies of text such as news articles, it has often been observed that the arguments for an event do not necessarily occur in the same sentence as that containing an event trigger. To tackle the issue of argument scattering across sentences, the use of global context becomes imperative in this task. In our work, we propose an external knowledge aided approach to infuse document-level event information to aid the extraction of complex event arguments. We develop a causal network for our event-annotated dataset by extracting relevant event causal structures from ConceptNet and phrases from Wikipedia. We use the extracted event causal features in a bi-directional transformer encoder to effectively capture long-range inter-sentence dependencies. We report the effectiveness of our proposed approach through both qualitative and quantitative analysis. In this task, we establish our findings on an event annotated dataset in 5 Indian languages. This dataset adds further complexity to the task by labelling arguments of entity type (like Time, Place) as well as more complex argument types (like Reason, After-Effect). Our approach achieves state-of-the-art performance across all the five languages. Since our work does not rely on any language-specific features, it can be easily extended to other languages.
No Rumours Please! A Multi-Indic-Lingual Approach for COVID Fake-Tweet Detection
Oct 14, 2020



The sudden widespread menace created by the present global pandemic COVID-19 has had an unprecedented effect on our lives. Man-kind is going through humongous fear and dependence on social media like never before. Fear inevitably leads to panic, speculations, and the spread of misinformation. Many governments have taken measures to curb the spread of such misinformation for public well being. Besides global measures, to have effective outreach, systems for demographically local languages have an important role to play in this effort. Towards this, we propose an approach to detect fake news about COVID-19 early on from social media, such as tweets, for multiple Indic-Languages besides English. In addition, we also create an annotated dataset of Hindi and Bengali tweet for fake news detection. We propose a BERT based model augmented with additional relevant features extracted from Twitter to identify fake tweets. To expand our approach to multiple Indic languages, we resort to mBERT based model which is fine-tuned over created dataset in Hindi and Bengali. We also propose a zero-shot learning approach to alleviate the data scarcity issue for such low resource languages. Through rigorous experiments, we show that our approach reaches around 89% F-Score in fake tweet detection which supercedes the state-of-the-art (SOTA) results. Moreover, we establish the first benchmark for two Indic-Languages, Hindi and Bengali. Using our annotated data, our model achieves about 79% F-Score in Hindi and 81% F-Score for Bengali Tweets. Our zero-shot model achieves about 81% F-Score in Hindi and 78% F-Score for Bengali Tweets without any annotated data, which clearly indicates the efficacy of our approach.
Meta-Context Transformers for Domain-Specific Response Generation
Oct 12, 2020


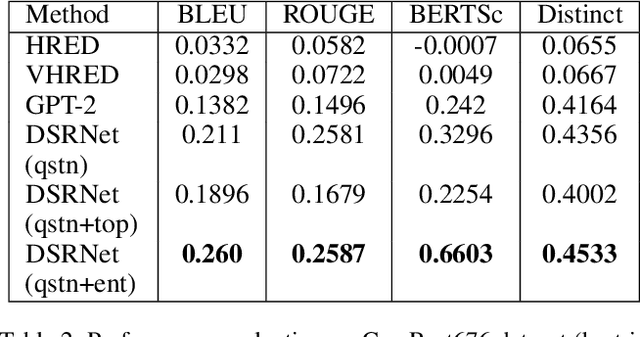
Despite the tremendous success of neural dialogue models in recent years, it suffers a lack of relevance, diversity, and some times coherence in generated responses. Lately, transformer-based models, such as GPT-2, have revolutionized the landscape of dialogue generation by capturing the long-range structures through language modeling. Though these models have exhibited excellent language coherence, they often lack relevance and terms when used for domain-specific response generation. In this paper, we present DSRNet (Domain Specific Response Network), a transformer-based model for dialogue response generation by reinforcing domain-specific attributes. In particular, we extract meta attributes from context and infuse them with the context utterances for better attention over domain-specific key terms and relevance. We study the use of DSRNet in a multi-turn multi-interlocutor environment for domain-specific response generation. In our experiments, we evaluate DSRNet on Ubuntu dialogue datasets, which are mainly composed of various technical domain related dialogues for IT domain issue resolutions and also on CamRest676 dataset, which contains restaurant domain conversations. Trained with maximum likelihood objective, our model shows significant improvement over the state-of-the-art for multi-turn dialogue systems supported by better BLEU and semantic similarity (BertScore) scores. Besides, we also observe that the responses produced by our model carry higher relevance due to the presence of domain-specific key attributes that exhibit better overlap with the attributes of the context. Our analysis shows that the performance improvement is mostly due to the infusion of key terms along with dialogues which result in better attention over domain-relevant terms. Other contributing factors include joint modeling of dialogue context with the domain-specific meta attributes and topics.