 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArgFuse: A Weakly-Supervised Framework for Document-Level Event Argument Aggregation
Paper and Code

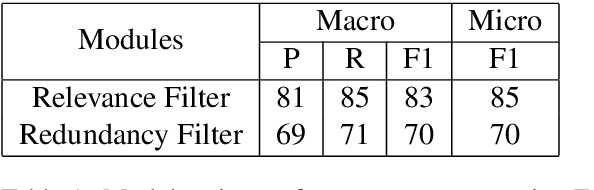

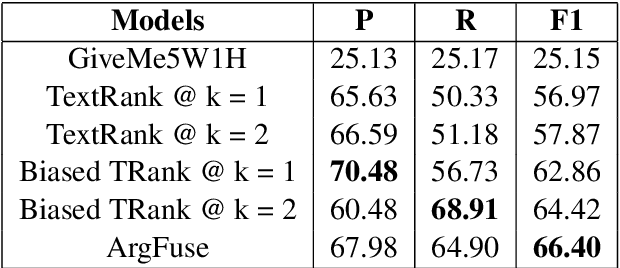
Most of the existing information extraction frameworks (Wadden et al., 2019; Veysehet al., 2020) focus on sentence-level tasks and are hardly able to capture the consolidated information from a given document. In our endeavour to generate precise document-level information frames from lengthy textual records, we introduce the task of Information Aggregation or Argument Aggregation. More specifically, our aim is to filter irrelevant and redundant argument mentions that were extracted at a sentence level and render a document level information frame. Majority of the existing works have been observed to resolve related tasks of document-level event argument extraction (Yang et al., 2018a; Zheng et al., 2019a) and salient entity identification (Jain et al.,2020) using supervised techniques. To remove dependency from large amounts of labelled data, we explore the task of information aggregation using weakly-supervised techniques. In particular, we present an extractive algorithm with multiple sieves which adopts active learning strategies to work efficiently in low-resource settings. For this task, we have annotated our own test dataset comprising of 131 document information frames and have released the code and dataset to further research prospects in this new domain. To the best of our knowledge, we are the first to establish baseline results for this task in English. Our data and code are publicly available at https://github.com/DebanjanaKar/ArgFuse.