 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Deep Federated Defenses Against Malware in Cloud Ecosystems
Dec 27, 2019
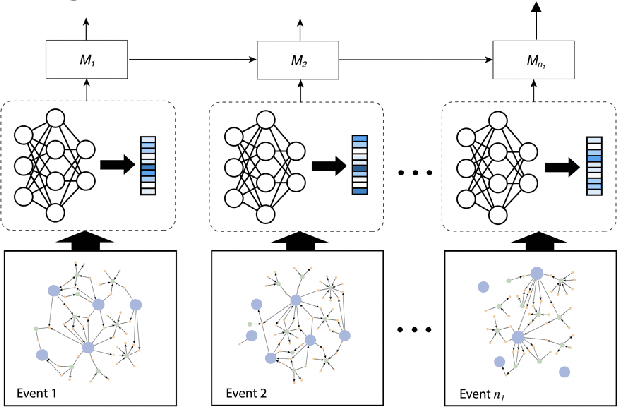
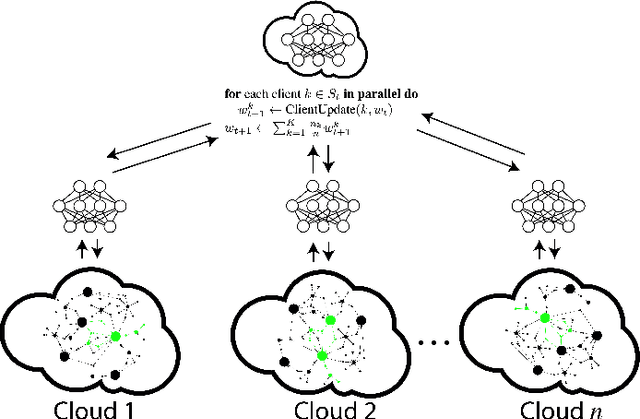
In cloud computing environments with many virtual machines, containers, and other systems, an epidemic of malware can be highly threatening to business processes. In this vision paper, we introduce a hierarchical approach to performing malware detection and analysis using several recent advances in machine learning on graphs, hypergraphs, and natural language. We analyze individual systems and their logs, inspecting and understanding their behavior with attentional sequence models. Given a feature representation of each system's logs using this procedure, we construct an attributed network of the cloud with systems and other components as vertices and propose an analysis of malware with inductive graph and hypergraph learning models. With this foundation, we consider the multicloud case, in which multiple clouds with differing privacy requirements cooperate against the spread of malware, proposing the use of federated learning to perform inference and training while preserving privacy. Finally, we discuss several open problems that remain in defending cloud computing environments against malware related to designing robust ecosystems, identifying cloud-specific optimization problems for response strategy, action spaces for malware containment and eradication, and developing priors and transfer learning tasks for machine learning models in this area.
Deep Hyperedges: a Framework for Transductive and Inductive Learning on Hypergraphs
Oct 07, 2019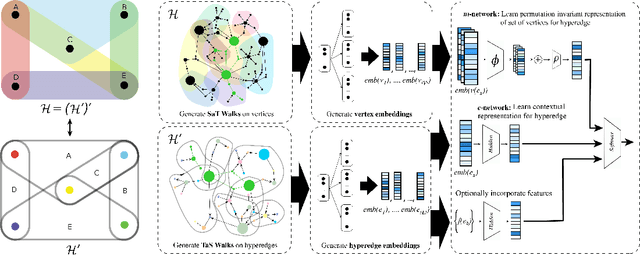
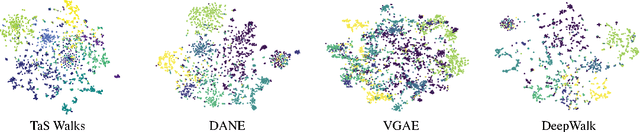
From social networks to protein complexes to disease genomes to visual data, hypergraphs are everywhere. However, the scope of research studying deep learning on hypergraphs is still quite sparse and nascent, as there has not yet existed an effective, unified framework for using hyperedge and vertex embeddings jointly in the hypergraph context, despite a large body of prior work that has shown the utility of deep learning over graphs and sets. Building upon these recent advances, we propose \textit{Deep Hyperedges} (DHE), a modular framework that jointly uses contextual and permutation-invariant vertex membership properties of hyperedges in hypergraphs to perform classification and regression in transductive and inductive learning settings. In our experiments, we use a novel random walk procedure and show that our model achieves and, in most cases, surpasses state-of-the-art performance on benchmark datasets. Additionally, we study our framework's performance on a variety of diverse, non-standard hypergraph datasets and propose several avenues of future work to further enhance DHE.
Uncheatable Machine Learning Inference
Aug 08, 2019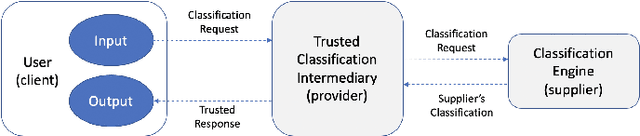
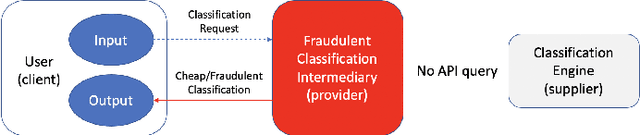
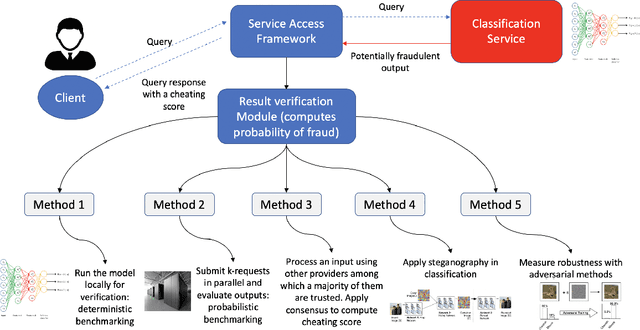
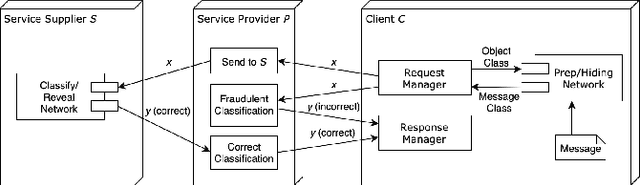
Classification-as-a-Service (CaaS) is widely deployed today in machine intelligence stacks for a vastly diverse set of applications including anything from medical prognosis to computer vision tasks to natural language processing to identity fraud detection. The computing power required for training complex models on large datasets to perform inference to solve these problems can be very resource-intensive. A CaaS provider may cheat a customer by fraudulently bypassing expensive training procedures in favor of weaker, less computationally-intensive algorithms which yield results of reduced quality. Given a classification service supplier $S$, intermediary CaaS provider $P$ claiming to use $S$ as a classification backend, and customer $C$, our work addresses the following questions: (i) how can $P$'s claim to be using $S$ be verified by $C$? (ii) how might $S$ make performance guarantees that may be verified by $C$? and (iii) how might one design a decentralized system that incentivizes service proofing and accountability? To this end, we propose a variety of methods for $C$ to evaluate the service claims made by $P$ using probabilistic performance metrics, instance seeding, and steganography. We also propose a method of measuring the robustness of a model using a blackbox adversarial procedure, which may then be used as a benchmark or comparison to a claim made by $S$. Finally, we propose the design of a smart contract-based decentralized system that incentivizes service accountability to serve as a trusted Quality of Service (QoS) auditor.