 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputationally sufficient statistics for Ising models
Feb 12, 2026Learning Gibbs distributions using only sufficient statistics has long been recognized as a computationally hard problem. On the other hand, computationally efficient algorithms for learning Gibbs distributions rely on access to full sample configurations generated from the model. For many systems of interest that arise in physical contexts, expecting a full sample to be observed is not practical, and hence it is important to look for computationally efficient methods that solve the learning problem with access to only a limited set of statistics. We examine the trade-offs between the power of computation and observation within this scenario, employing the Ising model as a paradigmatic example. We demonstrate that it is feasible to reconstruct the model parameters for a model with $\ell_1$ width $γ$ by observing statistics up to an order of $O(γ)$. This approach allows us to infer the model's structure and also learn its couplings and magnetic fields. We also discuss a setting where prior information about structure of the model is available and show that the learning problem can be solved efficiently with even more limited observational power.
Efficient Learning of Lattice Gauge Theories with Fermions
Dec 22, 2025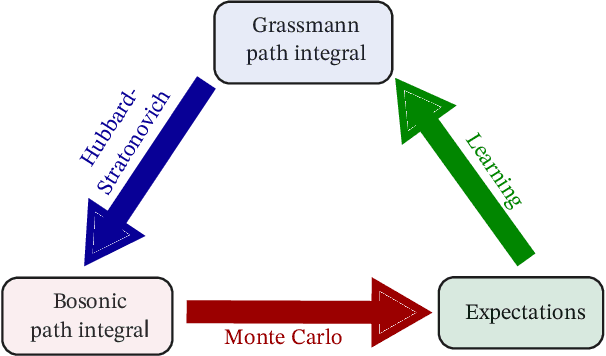
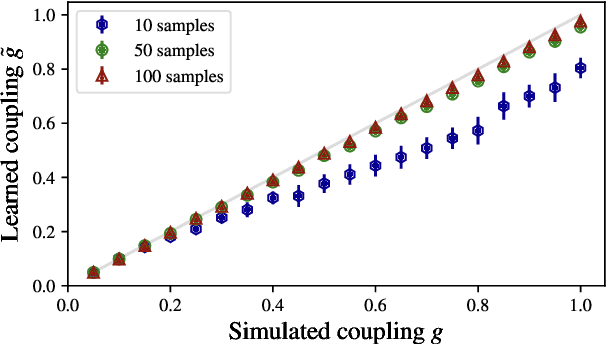
We introduce a learning method for recovering action parameters in lattice field theories. Our method is based on the minimization of a convex loss function constructed using the Schwinger-Dyson relations. We show that score matching, a popular learning method, is a special case of our construction of an infinite family of valid loss functions. Importantly, our general Schwinger-Dyson-based construction applies to gauge theories and models with Grassmann-valued fields used to represent dynamical fermions. In particular, we extend our method to realistic lattice field theories including quantum chromodynamics.
qa-FLoRA: Data-free query-adaptive Fusion of LoRAs for LLMs
Dec 12, 2025


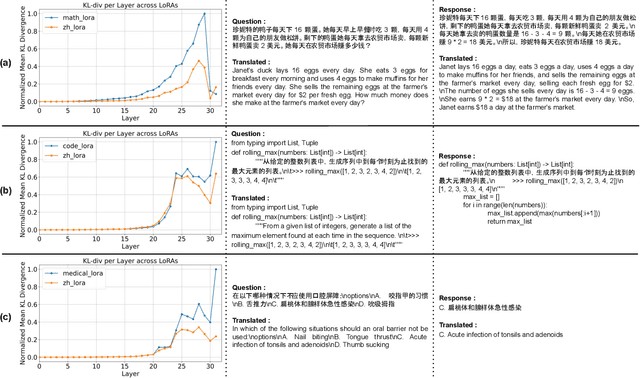
The deployment of large language models for specialized tasks often requires domain-specific parameter-efficient finetuning through Low-Rank Adaptation (LoRA) modules. However, effectively fusing these adapters to handle complex, multi-domain composite queries remains a critical challenge. Existing LoRA fusion approaches either use static weights, which assign equal relevance to each participating LoRA, or require data-intensive supervised training for every possible LoRA combination to obtain respective optimal fusion weights. We propose qa-FLoRA, a novel query-adaptive data-and-training-free method for LoRA fusion that dynamically computes layer-level fusion weights by measuring distributional divergence between the base model and respective adapters. Our approach eliminates the need for composite training data or domain-representative samples, making it readily applicable to existing adapter collections. Extensive experiments across nine multilingual composite tasks spanning mathematics, coding, and medical domains, show that qa-FLoRA outperforms static fusion by ~5% with LLaMA-2 and ~6% with LLaMA-3, and the training-free baselines by ~7% with LLaMA-2 and ~10% with LLaMA-3, while significantly closing the gap with supervised baselines. Further, layer-level analysis of our fusion weights reveals interpretable fusion patterns, demonstrating the effectiveness of our approach for robust multi-domain adaptation.
A Survey on Bridging EEG Signals and Generative AI: From Image and Text to Beyond
Feb 18, 2025Integration of Brain-Computer Interfaces (BCIs) and Generative Artificial Intelligence (GenAI) has opened new frontiers in brain signal decoding, enabling assistive communication, neural representation learning, and multimodal integration. BCIs, particularly those leveraging Electroencephalography (EEG), provide a non-invasive means of translating neural activity into meaningful outputs. Recent advances in deep learning, including Generative Adversarial Networks (GANs) and Transformer-based Large Language Models (LLMs), have significantly improved EEG-based generation of images, text, and speech. This paper provides a literature review of the state-of-the-art in EEG-based multimodal generation, focusing on (i) EEG-to-image generation through GANs, Variational Autoencoders (VAEs), and Diffusion Models, and (ii) EEG-to-text generation leveraging Transformer based language models and contrastive learning methods. Additionally, we discuss the emerging domain of EEG-to-speech synthesis, an evolving multimodal frontier. We highlight key datasets, use cases, challenges, and EEG feature encoding methods that underpin generative approaches. By providing a structured overview of EEG-based generative AI, this survey aims to equip researchers and practitioners with insights to advance neural decoding, enhance assistive technologies, and expand the frontiers of brain-computer interaction.
Towards Making Flowchart Images Machine Interpretable
Jan 29, 2025Computer programming textbooks and software documentations often contain flowcharts to illustrate the flow of an algorithm or procedure. Modern OCR engines often tag these flowcharts as graphics and ignore them in further processing. In this paper, we work towards making flowchart images machine-interpretable by converting them to executable Python codes. To this end, inspired by the recent success in natural language to code generation literature, we present a novel transformer-based framework, namely FloCo-T5. Our model is well-suited for this task,as it can effectively learn semantics, structure, and patterns of programming languages, which it leverages to generate syntactically correct code. We also used a task-specific pre-training objective to pre-train FloCo-T5 using a large number of logic-preserving augmented code samples. Further, to perform a rigorous study of this problem, we introduce theFloCo dataset that contains 11,884 flowchart images and their corresponding Python codes. Our experiments show promising results, and FloCo-T5 clearly outperforms related competitive baselines on code generation metrics. We make our dataset and implementation publicly available.
PatentLMM: Large Multimodal Model for Generating Descriptions for Patent Figures
Jan 25, 2025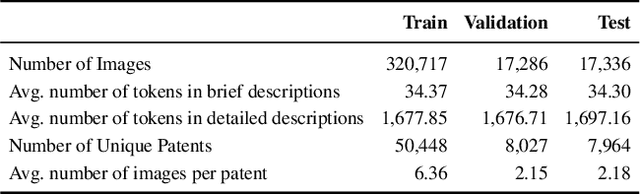
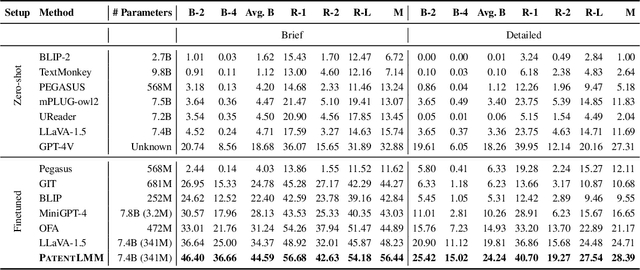
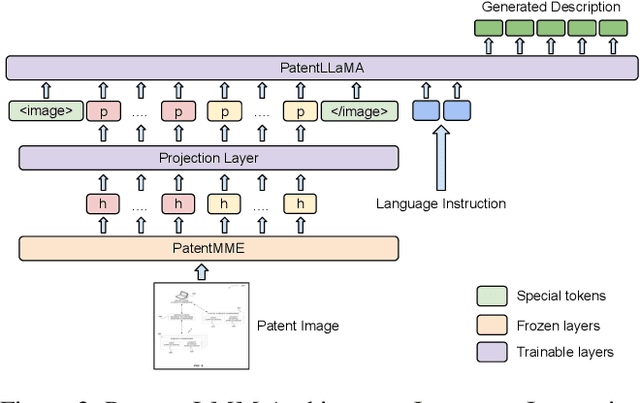
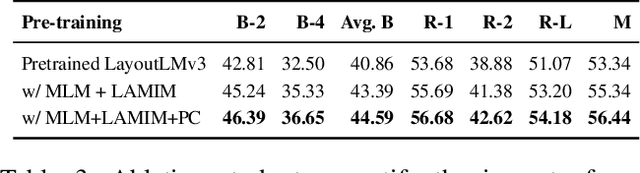
Writing comprehensive and accurate descriptions of technical drawings in patent documents is crucial to effective knowledge sharing and enabling the replication and protection of intellectual property. However, automation of this task has been largely overlooked by the research community. To this end, we introduce PatentDesc-355K, a novel large-scale dataset containing ~355K patent figures along with their brief and detailed textual descriptions extracted from more than 60K US patent documents. In addition, we propose PatentLMM - a novel multimodal large language model specifically tailored to generate high-quality descriptions of patent figures. Our proposed PatentLMM comprises two key components: (i) PatentMME, a specialized multimodal vision encoder that captures the unique structural elements of patent figures, and (ii) PatentLLaMA, a domain-adapted version of LLaMA fine-tuned on a large collection of patents. Extensive experiments demonstrate that training a vision encoder specifically designed for patent figures significantly boosts the performance, generating coherent descriptions compared to fine-tuning similar-sized off-the-shelf multimodal models. PatentDesc-355K and PatentLMM pave the way for automating the understanding of patent figures, enabling efficient knowledge sharing and faster drafting of patent documents. We make the code and data publicly available.
Thought2Text: Text Generation from EEG Signal using Large Language Models (LLMs)
Oct 10, 2024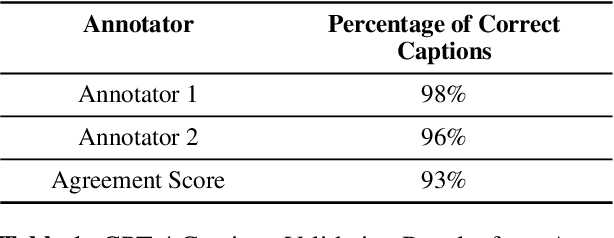
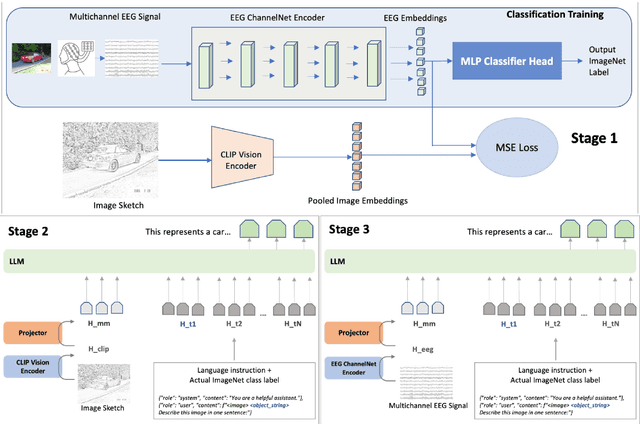
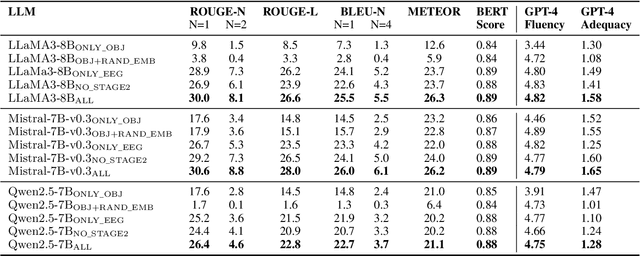
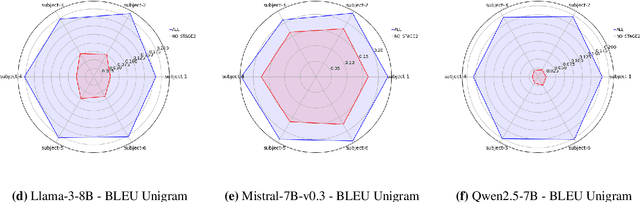
Decoding and expressing brain activity in a comprehensible form is a challenging frontier in AI. This paper presents Thought2Text, which uses instruction-tuned Large Language Models (LLMs) fine-tuned with EEG data to achieve this goal. The approach involves three stages: (1) training an EEG encoder for visual feature extraction, (2) fine-tuning LLMs on image and text data, enabling multimodal description generation, and (3) further fine-tuning on EEG embeddings to generate text directly from EEG during inference. Experiments on a public EEG dataset collected for six subjects with image stimuli demonstrate the efficacy of multimodal LLMs (LLaMa-v3, Mistral-v0.3, Qwen2.5), validated using traditional language generation evaluation metrics, GPT-4 based assessments, and evaluations by human expert. This approach marks a significant advancement towards portable, low-cost "thoughts-to-text" technology with potential applications in both neuroscience and natural language processing (NLP).