 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThought2Text: Text Generation from EEG Signal using Large Language Models (LLMs)
Paper and Code
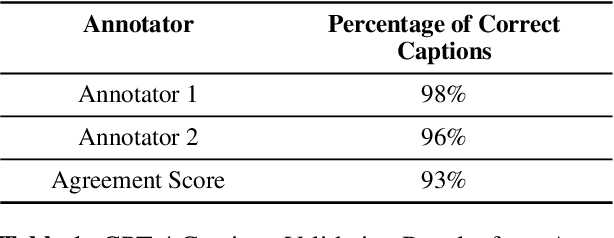
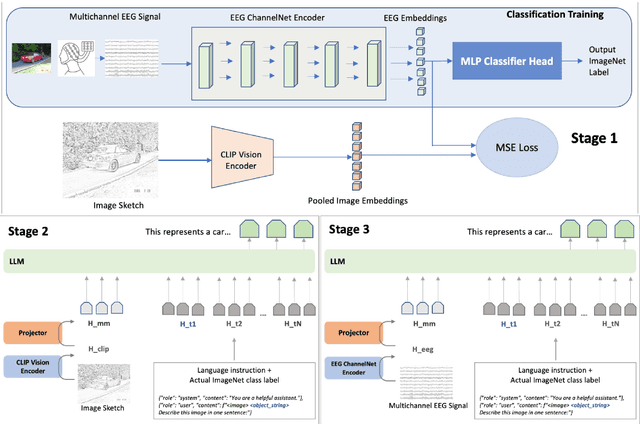
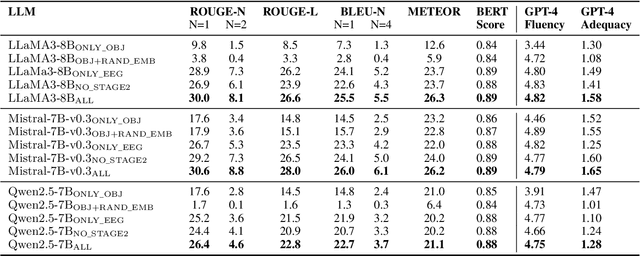
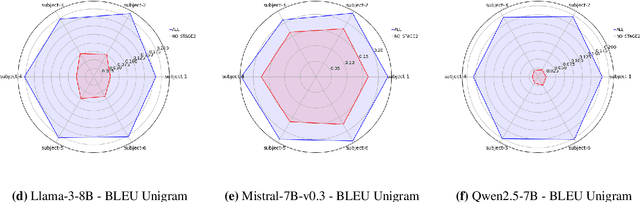
Decoding and expressing brain activity in a comprehensible form is a challenging frontier in AI. This paper presents Thought2Text, which uses instruction-tuned Large Language Models (LLMs) fine-tuned with EEG data to achieve this goal. The approach involves three stages: (1) training an EEG encoder for visual feature extraction, (2) fine-tuning LLMs on image and text data, enabling multimodal description generation, and (3) further fine-tuning on EEG embeddings to generate text directly from EEG during inference. Experiments on a public EEG dataset collected for six subjects with image stimuli demonstrate the efficacy of multimodal LLMs (LLaMa-v3, Mistral-v0.3, Qwen2.5), validated using traditional language generation evaluation metrics, GPT-4 based assessments, and evaluations by human expert. This approach marks a significant advancement towards portable, low-cost "thoughts-to-text" technology with potential applications in both neuroscience and natural language processing (NLP).