 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Long-Tail Learning in Latent Space by sampling Synthetic Data
Sep 19, 2025Imbalanced classification datasets pose significant challenges in machine learning, often leading to biased models that perform poorly on underrepresented classes. With the rise of foundation models, recent research has focused on the full, partial, and parameter-efficient fine-tuning of these models to deal with long-tail classification. Despite the impressive performance of these works on the benchmark datasets, they still fail to close the gap with the networks trained using the balanced datasets and still require substantial computational resources, even for relatively smaller datasets. Underscoring the importance of computational efficiency and simplicity, in this work we propose a novel framework that leverages the rich semantic latent space of Vision Foundation Models to generate synthetic data and train a simple linear classifier using a mixture of real and synthetic data for long-tail classification. The computational efficiency gain arises from the number of trainable parameters that are reduced to just the number of parameters in the linear model. Our method sets a new state-of-the-art for the CIFAR-100-LT benchmark and demonstrates strong performance on the Places-LT benchmark, highlighting the effectiveness and adaptability of our simple and effective approach.
PatentLMM: Large Multimodal Model for Generating Descriptions for Patent Figures
Jan 25, 2025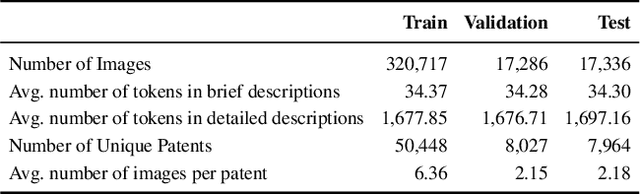
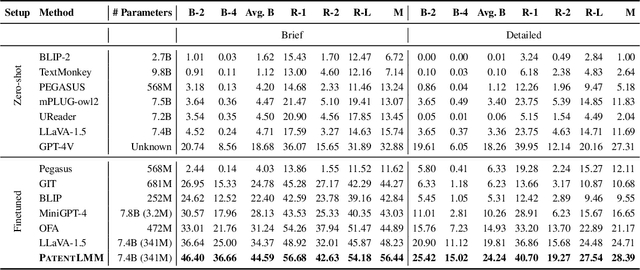
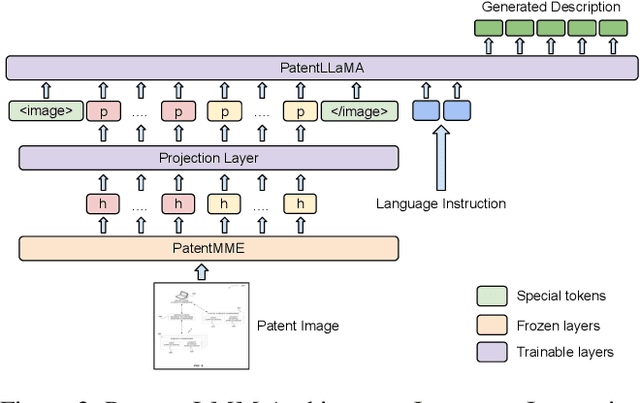
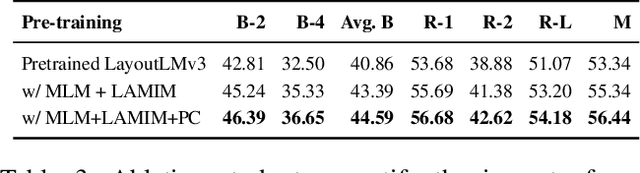
Writing comprehensive and accurate descriptions of technical drawings in patent documents is crucial to effective knowledge sharing and enabling the replication and protection of intellectual property. However, automation of this task has been largely overlooked by the research community. To this end, we introduce PatentDesc-355K, a novel large-scale dataset containing ~355K patent figures along with their brief and detailed textual descriptions extracted from more than 60K US patent documents. In addition, we propose PatentLMM - a novel multimodal large language model specifically tailored to generate high-quality descriptions of patent figures. Our proposed PatentLMM comprises two key components: (i) PatentMME, a specialized multimodal vision encoder that captures the unique structural elements of patent figures, and (ii) PatentLLaMA, a domain-adapted version of LLaMA fine-tuned on a large collection of patents. Extensive experiments demonstrate that training a vision encoder specifically designed for patent figures significantly boosts the performance, generating coherent descriptions compared to fine-tuning similar-sized off-the-shelf multimodal models. PatentDesc-355K and PatentLMM pave the way for automating the understanding of patent figures, enabling efficient knowledge sharing and faster drafting of patent documents. We make the code and data publicly available.
Sketch-guided Image Inpainting with Partial Discrete Diffusion Process
Apr 18, 2024In this work, we study the task of sketch-guided image inpainting. Unlike the well-explored natural language-guided image inpainting, which excels in capturing semantic details, the relatively less-studied sketch-guided inpainting offers greater user control in specifying the object's shape and pose to be inpainted. As one of the early solutions to this task, we introduce a novel partial discrete diffusion process (PDDP). The forward pass of the PDDP corrupts the masked regions of the image and the backward pass reconstructs these masked regions conditioned on hand-drawn sketches using our proposed sketch-guided bi-directional transformer. The proposed novel transformer module accepts two inputs -- the image containing the masked region to be inpainted and the query sketch to model the reverse diffusion process. This strategy effectively addresses the domain gap between sketches and natural images, thereby, enhancing the quality of inpainting results. In the absence of a large-scale dataset specific to this task, we synthesize a dataset from the MS-COCO to train and extensively evaluate our proposed framework against various competent approaches in the literature. The qualitative and quantitative results and user studies establish that the proposed method inpaints realistic objects that fit the context in terms of the visual appearance of the provided sketch. To aid further research, we have made our code publicly available at https://github.com/vl2g/Sketch-Inpainting .
Contrastive Multi-View Textual-Visual Encoding: Towards One Hundred Thousand-Scale One-Shot Logo Identification
Nov 23, 2022



In this paper, we study the problem of identifying logos of business brands in natural scenes in an open-set one-shot setting. This problem setup is significantly more challenging than traditionally-studied 'closed-set' and 'large-scale training samples per category' logo recognition settings. We propose a novel multi-view textual-visual encoding framework that encodes text appearing in the logos as well as the graphical design of the logos to learn robust contrastive representations. These representations are jointly learned for multiple views of logos over a batch and thereby they generalize well to unseen logos. We evaluate our proposed framework for cropped logo verification, cropped logo identification, and end-to-end logo identification in natural scene tasks; and compare it against state-of-the-art methods. Further, the literature lacks a 'very-large-scale' collection of reference logo images that can facilitate the study of one-hundred thousand-scale logo identification. To fill this gap in the literature, we introduce Wikidata Reference Logo Dataset (WiRLD), containing logos for 100K business brands harvested from Wikidata. Our proposed framework that achieves an area under the ROC curve of 91.3% on the QMUL-OpenLogo dataset for the verification task, outperforms state-of-the-art methods by 9.1% and 2.6% on the one-shot logo identification task on the Toplogos-10 and the FlickrLogos32 datasets, respectively. Further, we show that our method is more stable compared to other baselines even when the number of candidate logos is on a 100K scale.