 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Open Domain Question Answering Systems Answer Visual Knowledge Questions?
Paper and Code

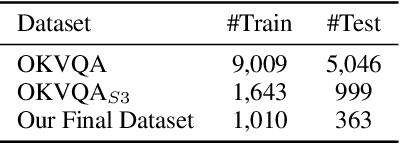

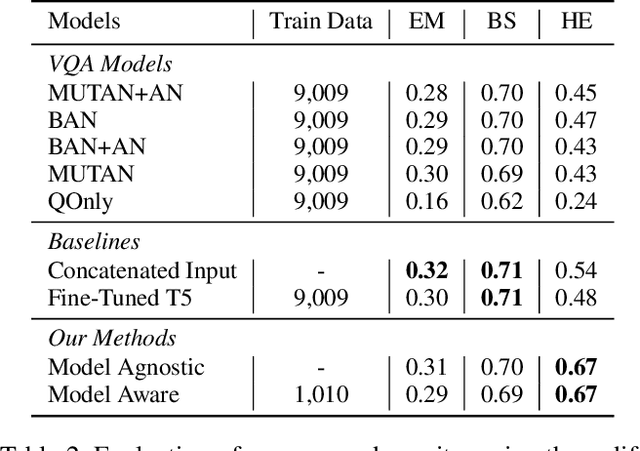
The task of Outside Knowledge Visual Question Answering (OKVQA) requires an automatic system to answer natural language questions about pictures and images using external knowledge. We observe that many visual questions, which contain deictic referential phrases referring to entities in the image, can be rewritten as "non-grounded" questions and can be answered by existing text-based question answering systems. This allows for the reuse of existing text-based Open Domain Question Answering (QA) Systems for visual question answering. In this work, we propose a potentially data-efficient approach that reuses existing systems for (a) image analysis, (b) question rewriting, and (c) text-based question answering to answer such visual questions. Given an image and a question pertaining to that image (a visual question), we first extract the entities present in the image using pre-trained object and scene classifiers. Using these detected entities, the visual questions can be rewritten so as to be answerable by open domain QA systems. We explore two rewriting strategies: (1) an unsupervised method using BERT for masking and rewriting, and (2) a weakly supervised approach that combines adaptive rewriting and reinforcement learning techniques to use the implicit feedback from the QA system. We test our strategies on the publicly available OKVQA dataset and obtain a competitive performance with state-of-the-art models while using only 10% of the training data.