 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing social media with crowdsourcing in Crowd4SDG
Aug 04, 2022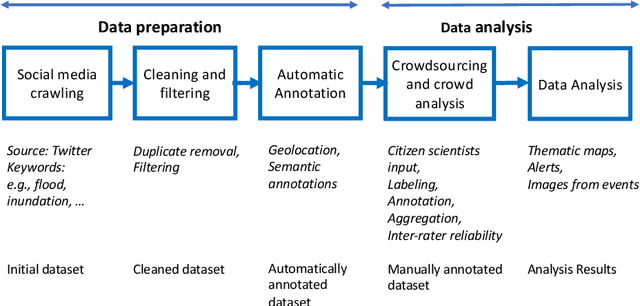

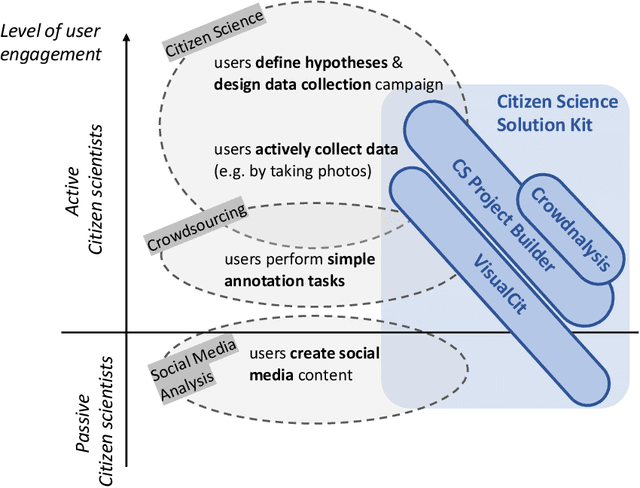
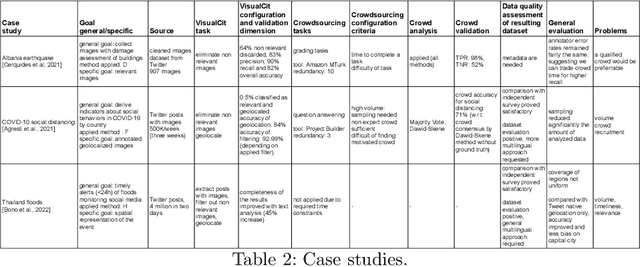
Social media have the potential to provide timely information about emergency situations and sudden events. However, finding relevant information among millions of posts being posted every day can be difficult, and developing a data analysis project usually requires time and technical skills. This study presents an approach that provides flexible support for analyzing social media, particularly during emergencies. Different use cases in which social media analysis can be adopted are introduced, and the challenges of retrieving information from large sets of posts are discussed. The focus is on analyzing images and text contained in social media posts and a set of automatic data processing tools for filtering, classification, and geolocation of content with a human-in-the-loop approach to support the data analyst. Such support includes both feedback and suggestions to configure automated tools, and crowdsourcing to gather inputs from citizens. The results are validated by discussing three case studies developed within the Crowd4SDG H2020 European project.
A Technical Survey on Statistical Modelling and Design Methods for Crowdsourcing Quality Control
Dec 05, 2018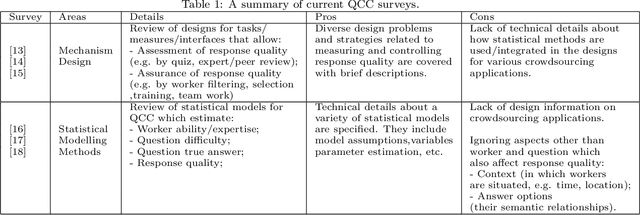
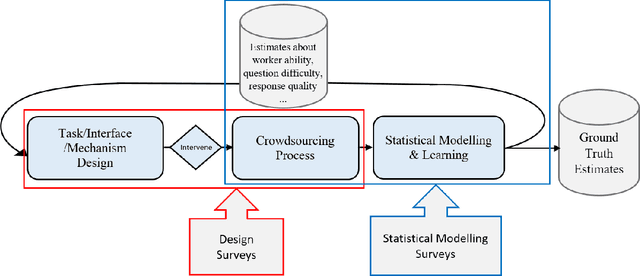
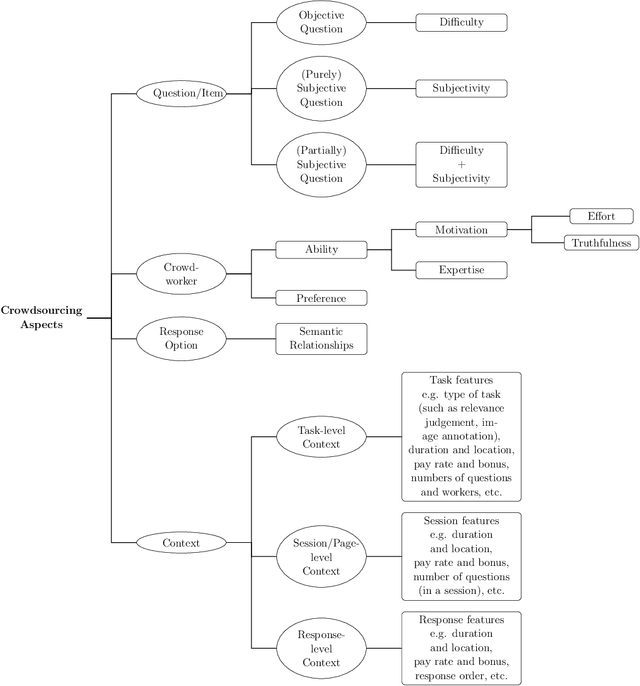
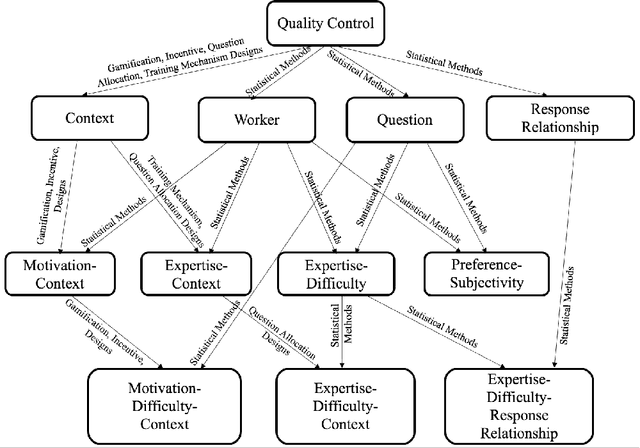
Online crowdsourcing provides a scalable and inexpensive means to collect knowledge (e.g. labels) about various types of data items (e.g. text, audio, video). However, it is also known to result in large variance in the quality of recorded responses which often cannot be directly used for training machine learning systems. To resolve this issue, a lot of work has been conducted to control the response quality such that low-quality responses cannot adversely affect the performance of the machine learning systems. Such work is referred to as the quality control for crowdsourcing. Past quality control research can be divided into two major branches: quality control mechanism design and statistical models. The first branch focuses on designing measures, thresholds, interfaces and workflows for payment, gamification, question assignment and other mechanisms that influence workers' behaviour. The second branch focuses on developing statistical models to perform effective aggregation of responses to infer correct responses. The two branches are connected as statistical models (i) provide parameter estimates to support the measure and threshold calculation, and (ii) encode modelling assumptions used to derive (theoretical) performance guarantees for the mechanisms. There are surveys regarding each branch but they lack technical details about the other branch. Our survey is the first to bridge the two branches by providing technical details on how they work together under frameworks that systematically unify crowdsourcing aspects modelled by both of them to determine the response quality. We are also the first to provide taxonomies of quality control papers based on the proposed frameworks. Finally, we specify the current limitations and the corresponding future directions for the quality control research.
Distinguishing Question Subjectivity from Difficulty for Improved Crowdsourcing
Feb 14, 2018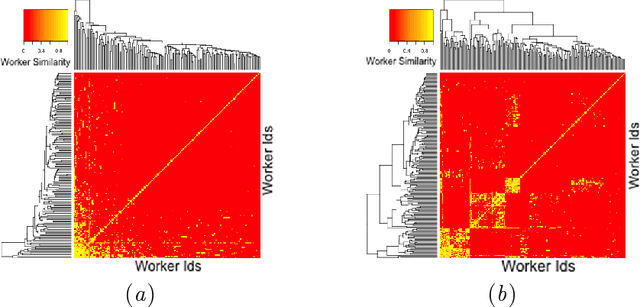

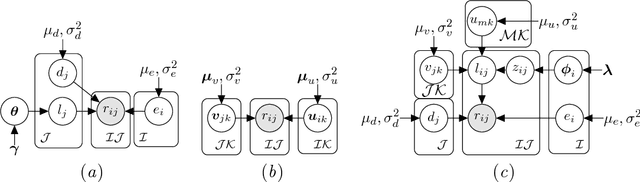
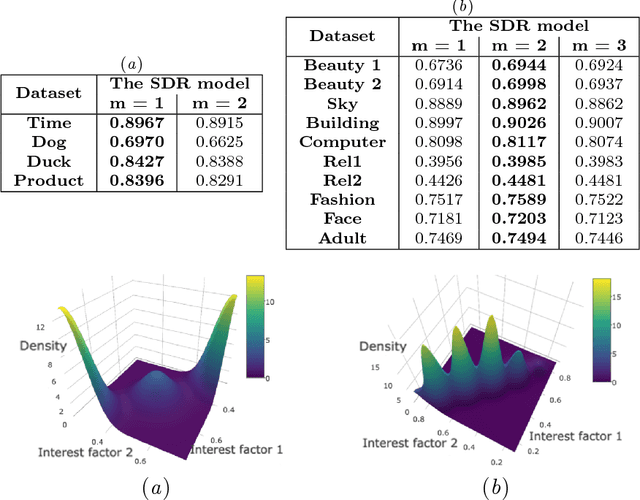
The questions in a crowdsourcing task typically exhibit varying degrees of difficulty and subjectivity. Their joint effects give rise to the variation in responses to the same question by different crowd-workers. This variation is low when the question is easy to answer and objective, and high when it is difficult and subjective. Unfortunately, current quality control methods for crowdsourcing consider only the question difficulty to account for the variation. As a result,these methods cannot distinguish workers personal preferences for different correct answers of a partially subjective question from their ability/expertise to avoid objectively wrong answers for that question. To address this issue, we present a probabilistic model which (i) explicitly encodes question difficulty as a model parameter and (ii) implicitly encodes question subjectivity via latent preference factors for crowd-workers. We show that question subjectivity induces grouping of crowd-workers, revealed through clustering of their latent preferences. Moreover, we develop a quantitative measure of the subjectivity of a question. Experiments show that our model(1) improves the performance of both quality control for crowd-sourced answers and next answer prediction for crowd-workers,and (2) can potentially provide coherent rankings of questions in terms of their difficulty and subjectivity, so that task providers can refine their designs of the crowdsourcing tasks, e.g. by removing highly subjective questions or inappropriately difficult questions.
Automatic Identification of Sarcasm Target: An Introductory Approach
Aug 25, 2017



Past work in computational sarcasm deals primarily with sarcasm detection. In this paper, we introduce a novel, related problem: sarcasm target identification i.e., extracting the target of ridicule in a sarcastic sentence). We present an introductory approach for sarcasm target identification. Our approach employs two types of extractors: one based on rules, and another consisting of a statistical classifier. To compare our approach, we use two baselines: a na\"ive baseline and another baseline based on work in sentiment target identification. We perform our experiments on book snippets and tweets, and show that our hybrid approach performs better than the two baselines and also, in comparison with using the two extractors individually. Our introductory approach establishes the viability of sarcasm target identification, and will serve as a baseline for future work.
Expect the unexpected: Harnessing Sentence Completion for Sarcasm Detection
Jul 19, 2017
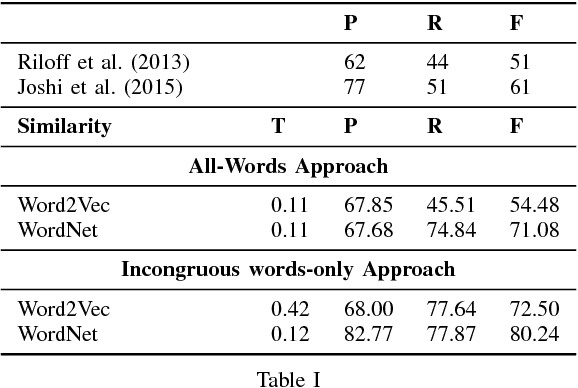
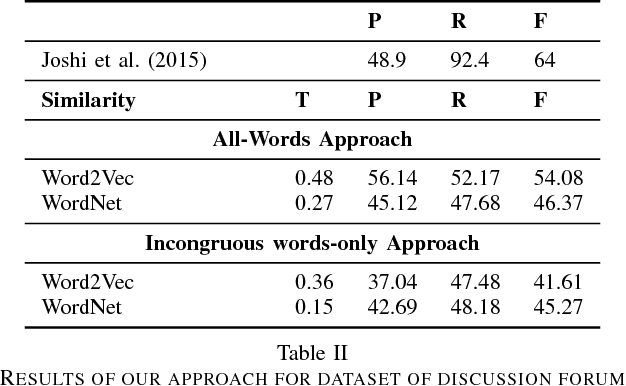
The trigram `I love being' is expected to be followed by positive words such as `happy'. In a sarcastic sentence, however, the word `ignored' may be observed. The expected and the observed words are, thus, incongruous. We model sarcasm detection as the task of detecting incongruity between an observed and an expected word. In order to obtain the expected word, we use Context2Vec, a sentence completion library based on Bidirectional LSTM. However, since the exact word where such an incongruity occurs may not be known in advance, we present two approaches: an All-words approach (which consults sentence completion for every content word) and an Incongruous words-only approach (which consults sentence completion for the 50% most incongruous content words). The approaches outperform reported values for tweets but not for discussion forum posts. This is likely to be because of redundant consultation of sentence completion for discussion forum posts. Therefore, we consider an oracle case where the exact incongruous word is manually labeled in a corpus reported in past work. In this case, the performance is higher than the all-words approach. This sets up the promise for using sentence completion for sarcasm detection.
`Who would have thought of that!': A Hierarchical Topic Model for Extraction of Sarcasm-prevalent Topics and Sarcasm Detection
Nov 22, 2016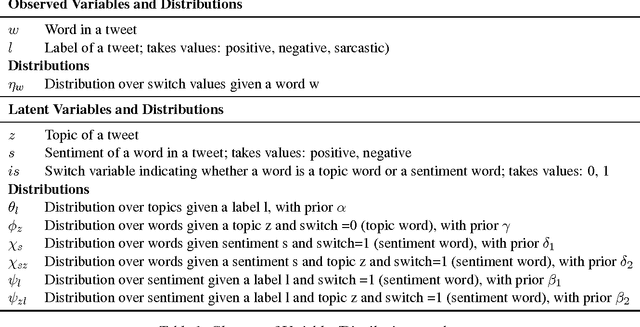
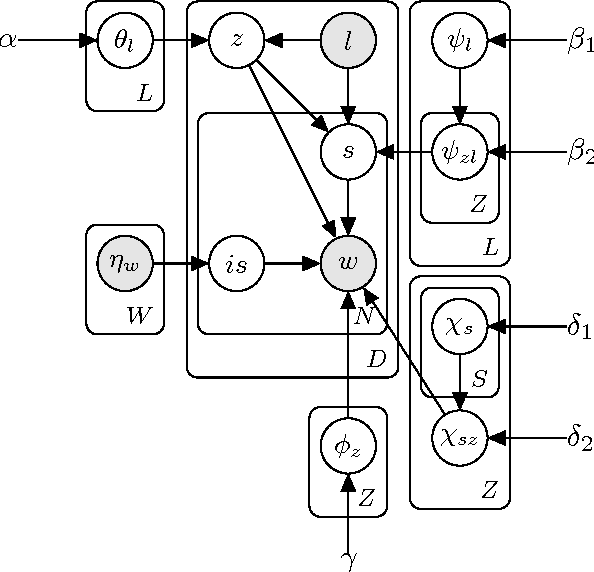
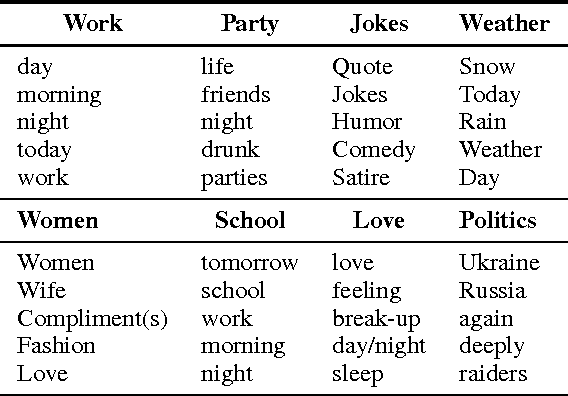
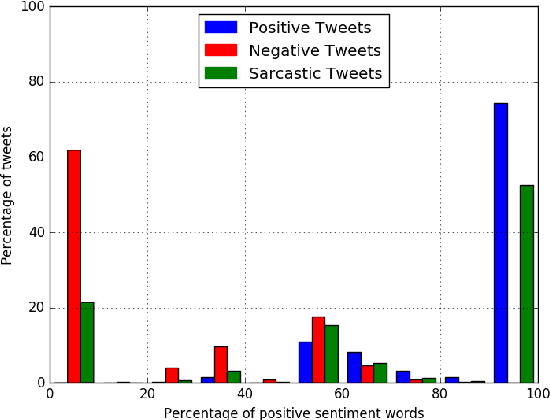
Topic Models have been reported to be beneficial for aspect-based sentiment analysis. This paper reports a simple topic model for sarcasm detection, a first, to the best of our knowledge. Designed on the basis of the intuition that sarcastic tweets are likely to have a mixture of words of both sentiments as against tweets with literal sentiment (either positive or negative), our hierarchical topic model discovers sarcasm-prevalent topics and topic-level sentiment. Using a dataset of tweets labeled using hashtags, the model estimates topic-level, and sentiment-level distributions. Our evaluation shows that topics such as `work', `gun laws', `weather' are sarcasm-prevalent topics. Our model is also able to discover the mixture of sentiment-bearing words that exist in a text of a given sentiment-related label. Finally, we apply our model to predict sarcasm in tweets. We outperform two prior work based on statistical classifiers with specific features, by around 25\%.
Are Word Embedding-based Features Useful for Sarcasm Detection?
Oct 04, 2016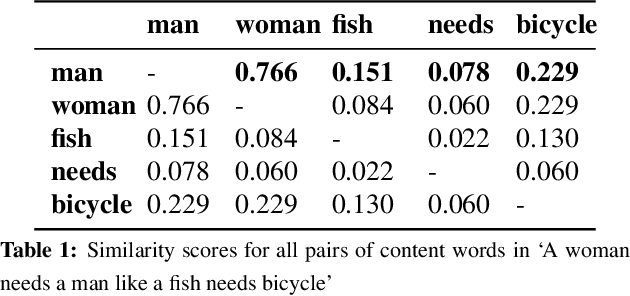
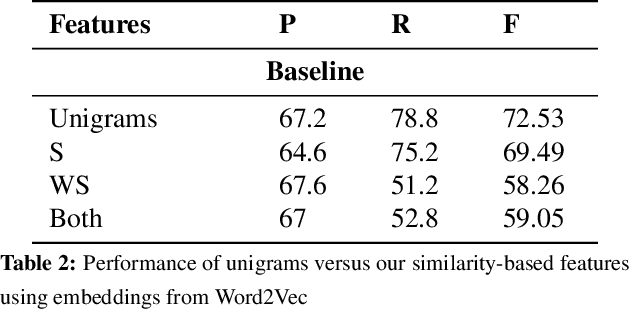
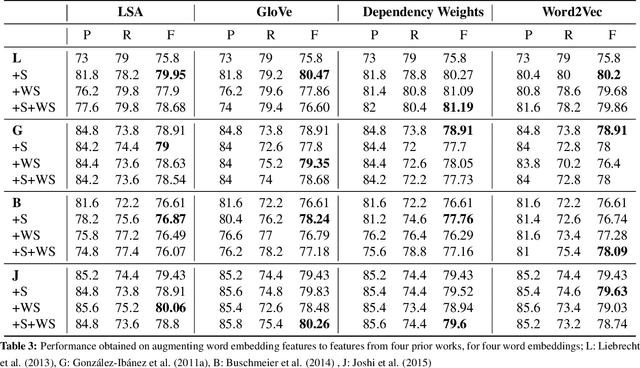
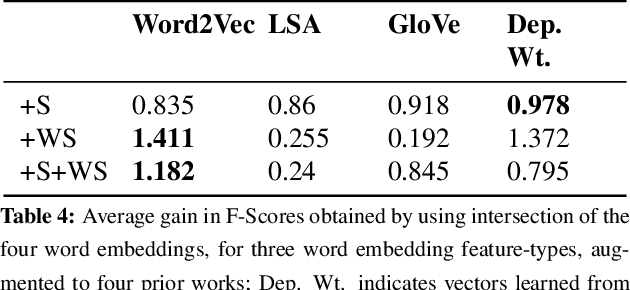
This paper makes a simple increment to state-of-the-art in sarcasm detection research. Existing approaches are unable to capture subtle forms of context incongruity which lies at the heart of sarcasm. We explore if prior work can be enhanced using semantic similarity/discordance between word embeddings. We augment word embedding-based features to four feature sets reported in the past. We also experiment with four types of word embeddings. We observe an improvement in sarcasm detection, irrespective of the word embedding used or the original feature set to which our features are augmented. For example, this augmentation results in an improvement in F-score of around 4\% for three out of these four feature sets, and a minor degradation in case of the fourth, when Word2Vec embeddings are used. Finally, a comparison of the four embeddings shows that Word2Vec and dependency weight-based features outperform LSA and GloVe, in terms of their benefit to sarcasm detection.
A Computational Approach to Automatic Prediction of Drunk Texting
Oct 04, 2016
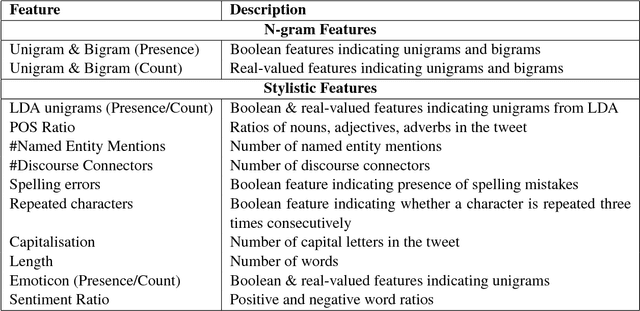
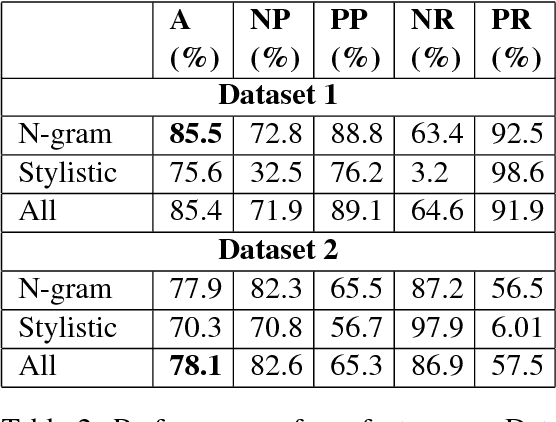

Alcohol abuse may lead to unsociable behavior such as crime, drunk driving, or privacy leaks. We introduce automatic drunk-texting prediction as the task of identifying whether a text was written when under the influence of alcohol. We experiment with tweets labeled using hashtags as distant supervision. Our classifiers use a set of N-gram and stylistic features to detect drunk tweets. Our observations present the first quantitative evidence that text contains signals that can be exploited to detect drunk-texting.