 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuAIL: Quality-Aware Inertial Learning for Robust Training under Data Corruption
Feb 03, 2026Tabular machine learning systems are frequently trained on data affected by non-uniform corruption, including noisy measurements, missing entries, and feature-specific biases. In practice, these defects are often documented only through column-level reliability indicators rather than instance-wise quality annotations, limiting the applicability of many robustness and cleaning techniques. We present QuAIL, a quality-informed training mechanism that incorporates feature reliability priors directly into the learning process. QuAIL augments existing models with a learnable feature-modulation layer whose updates are selectively constrained by a quality-dependent proximal regularizer, thereby inducing controlled adaptation across features of varying trustworthiness. This stabilizes optimization under structured corruption without explicit data repair or sample-level reweighting. Empirical evaluation across 50 classification and regression datasets demonstrates that QuAIL consistently improves average performance over neural baselines under both random and value-dependent corruption, with especially robust behavior in low-data and systematically biased settings. These results suggest that incorporating feature reliability information directly into optimization dynamics is a practical and effective approach for resilient tabular learning.
Analyzing social media with crowdsourcing in Crowd4SDG
Aug 04, 2022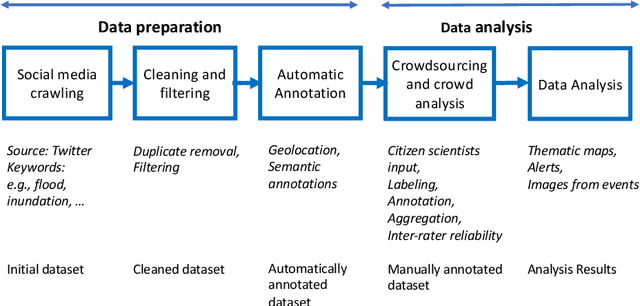

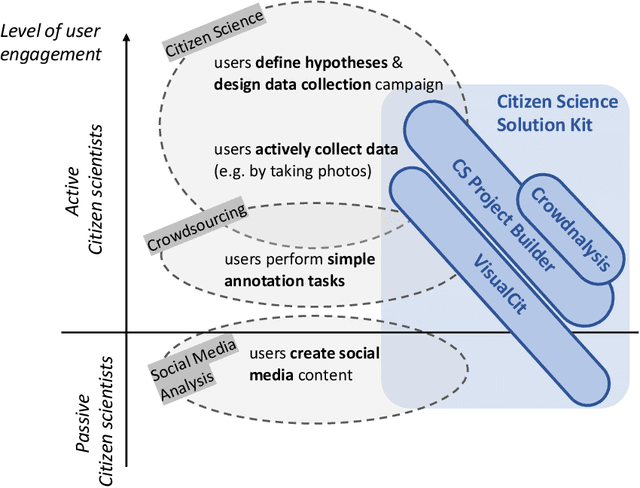
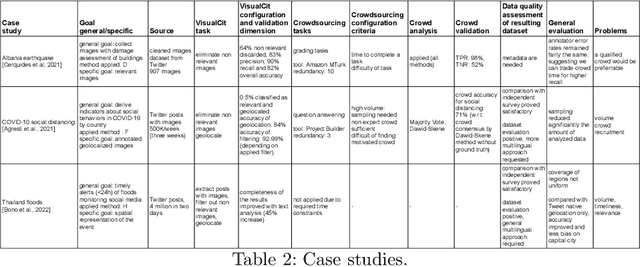
Social media have the potential to provide timely information about emergency situations and sudden events. However, finding relevant information among millions of posts being posted every day can be difficult, and developing a data analysis project usually requires time and technical skills. This study presents an approach that provides flexible support for analyzing social media, particularly during emergencies. Different use cases in which social media analysis can be adopted are introduced, and the challenges of retrieving information from large sets of posts are discussed. The focus is on analyzing images and text contained in social media posts and a set of automatic data processing tools for filtering, classification, and geolocation of content with a human-in-the-loop approach to support the data analyst. Such support includes both feedback and suggestions to configure automated tools, and crowdsourcing to gather inputs from citizens. The results are validated by discussing three case studies developed within the Crowd4SDG H2020 European project.