 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuAIL: Quality-Aware Inertial Learning for Robust Training under Data Corruption
Feb 03, 2026Tabular machine learning systems are frequently trained on data affected by non-uniform corruption, including noisy measurements, missing entries, and feature-specific biases. In practice, these defects are often documented only through column-level reliability indicators rather than instance-wise quality annotations, limiting the applicability of many robustness and cleaning techniques. We present QuAIL, a quality-informed training mechanism that incorporates feature reliability priors directly into the learning process. QuAIL augments existing models with a learnable feature-modulation layer whose updates are selectively constrained by a quality-dependent proximal regularizer, thereby inducing controlled adaptation across features of varying trustworthiness. This stabilizes optimization under structured corruption without explicit data repair or sample-level reweighting. Empirical evaluation across 50 classification and regression datasets demonstrates that QuAIL consistently improves average performance over neural baselines under both random and value-dependent corruption, with especially robust behavior in low-data and systematically biased settings. These results suggest that incorporating feature reliability information directly into optimization dynamics is a practical and effective approach for resilient tabular learning.
SurvKAN: A Fully Parametric Survival Model Based on Kolmogorov-Arnold Networks
Feb 02, 2026Accurate prediction of time-to-event outcomes is critical for clinical decision-making, treatment planning, and resource allocation in modern healthcare. While classical survival models such as Cox remain widely adopted in standard practice, they rely on restrictive assumptions, including linear covariate relationships and proportional hazards over time, that often fail to capture real-world clinical dynamics. Recent deep learning approaches like DeepSurv and DeepHit offer improved expressivity but sacrifice interpretability, limiting clinical adoption where trust and transparency are paramount. Hybrid models incorporating Kolmogorov-Arnold Networks (KANs), such as CoxKAN, have begun to address this trade-off but remain constrained by the semi-parametric Cox framework. In this work we introduce SurvKAN, a fully parametric, time-continuous survival model based on KAN architectures that eliminates the proportional hazards constraint. SurvKAN treats time as an explicit input to a KAN that directly predicts the log-hazard function, enabling end-to-end training on the full survival likelihood. Our architecture preserves interpretability through learnable univariate functions that indicate how individual features influence risk over time. Extensive experiments on standard survival benchmarks demonstrate that SurvKAN achieves competitive or superior performance compared to classical and state-of-the-art baselines across concordance and calibration metrics. Additionally, interpretability analyses reveal clinically meaningful patterns that align with medical domain knowledge.
Deep Variational Contrastive Learning for Joint Risk Stratification and Time-to-Event Estimation
Feb 01, 2026Survival analysis is essential for clinical decision-making, as it allows practitioners to estimate time-to-event outcomes, stratify patient risk profiles, and guide treatment planning. Deep learning has revolutionized this field with unprecedented predictive capabilities but faces a fundamental trade-off between performance and interpretability. While neural networks achieve high accuracy, their black-box nature limits clinical adoption. Conversely, deep clustering-based methods that stratify patients into interpretable risk groups typically sacrifice predictive power. We propose CONVERSE (CONtrastive Variational Ensemble for Risk Stratification and Estimation), a deep survival model that bridges this gap by unifying variational autoencoders with contrastive learning for interpretable risk stratification. CONVERSE combines variational embeddings with multiple intra- and inter-cluster contrastive losses. Self-paced learning progressively incorporates samples from easy to hard, improving training stability. The model supports cluster-specific survival heads, enabling accurate ensemble predictions. Comprehensive evaluation on four benchmark datasets demonstrates that CONVERSE achieves competitive or superior performance compared to existing deep survival methods, while maintaining meaningful patient stratification.
Latent Neural Cellular Automata for Resource-Efficient Image Restoration
Mar 22, 2024



Neural cellular automata represent an evolution of the traditional cellular automata model, enhanced by the integration of a deep learning-based transition function. This shift from a manual to a data-driven approach significantly increases the adaptability of these models, enabling their application in diverse domains, including content generation and artificial life. However, their widespread application has been hampered by significant computational requirements. In this work, we introduce the Latent Neural Cellular Automata (LNCA) model, a novel architecture designed to address the resource limitations of neural cellular automata. Our approach shifts the computation from the conventional input space to a specially designed latent space, relying on a pre-trained autoencoder. We apply our model in the context of image restoration, which aims to reconstruct high-quality images from their degraded versions. This modification not only reduces the model's resource consumption but also maintains a flexible framework suitable for various applications. Our model achieves a significant reduction in computational requirements while maintaining high reconstruction fidelity. This increase in efficiency allows for inputs up to 16 times larger than current state-of-the-art neural cellular automata models, using the same resources.
Scaling Survival Analysis in Healthcare with Federated Survival Forests: A Comparative Study on Heart Failure and Breast Cancer Genomics
Aug 04, 2023Survival analysis is a fundamental tool in medicine, modeling the time until an event of interest occurs in a population. However, in real-world applications, survival data are often incomplete, censored, distributed, and confidential, especially in healthcare settings where privacy is critical. The scarcity of data can severely limit the scalability of survival models to distributed applications that rely on large data pools. Federated learning is a promising technique that enables machine learning models to be trained on multiple datasets without compromising user privacy, making it particularly well-suited for addressing the challenges of survival data and large-scale survival applications. Despite significant developments in federated learning for classification and regression, many directions remain unexplored in the context of survival analysis. In this work, we propose an extension of the Federated Survival Forest algorithm, called FedSurF++. This federated ensemble method constructs random survival forests in heterogeneous federations. Specifically, we investigate several new tree sampling methods from client forests and compare the results with state-of-the-art survival models based on neural networks. The key advantage of FedSurF++ is its ability to achieve comparable performance to existing methods while requiring only a single communication round to complete. The extensive empirical investigation results in a significant improvement from the algorithmic and privacy preservation perspectives, making the original FedSurF algorithm more efficient, robust, and private. We also present results on two real-world datasets demonstrating the success of FedSurF++ in real-world healthcare studies. Our results underscore the potential of FedSurF++ to improve the scalability and effectiveness of survival analysis in distributed settings while preserving user privacy.
Discriminative Adversarial Privacy: Balancing Accuracy and Membership Privacy in Neural Networks
Jun 05, 2023



The remarkable proliferation of deep learning across various industries has underscored the importance of data privacy and security in AI pipelines. As the evolution of sophisticated Membership Inference Attacks (MIAs) threatens the secrecy of individual-specific information used for training deep learning models, Differential Privacy (DP) raises as one of the most utilized techniques to protect models against malicious attacks. However, despite its proven theoretical properties, DP can significantly hamper model performance and increase training time, turning its use impractical in real-world scenarios. Tackling this issue, we present Discriminative Adversarial Privacy (DAP), a novel learning technique designed to address the limitations of DP by achieving a balance between model performance, speed, and privacy. DAP relies on adversarial training based on a novel loss function able to minimise the prediction error while maximising the MIA's error. In addition, we introduce a novel metric named Accuracy Over Privacy (AOP) to capture the performance-privacy trade-off. Finally, to validate our claims, we compare DAP with diverse DP scenarios, providing an analysis of the results from performance, time, and privacy preservation perspectives.
Federated Survival Forests
Feb 06, 2023Survival analysis is a subfield of statistics concerned with modeling the occurrence time of a particular event of interest for a population. Survival analysis found widespread applications in healthcare, engineering, and social sciences. However, real-world applications involve survival datasets that are distributed, incomplete, censored, and confidential. In this context, federated learning can tremendously improve the performance of survival analysis applications. Federated learning provides a set of privacy-preserving techniques to jointly train machine learning models on multiple datasets without compromising user privacy, leading to a better generalization performance. Despite the widespread development of federated learning in recent AI research, only a few studies focus on federated survival analysis. In this work, we present a novel federated algorithm for survival analysis based on one of the most successful survival models, the random survival forest. We call the proposed method Federated Survival Forest (FedSurF). With a single communication round, FedSurF obtains a discriminative power comparable to deep-learning-based federated models trained over hundreds of federated iterations. Moreover, FedSurF retains all the advantages of random forests, namely low computational cost and natural handling of missing values and incomplete datasets. These advantages are especially desirable in real-world federated environments with multiple small datasets stored on devices with low computational capabilities. Numerical experiments compare FedSurF with state-of-the-art survival models in federated networks, showing how FedSurF outperforms deep-learning-based federated algorithms in realistic environments with non-identically distributed data.
Heterogeneous Datasets for Federated Survival Analysis Simulation
Jan 28, 2023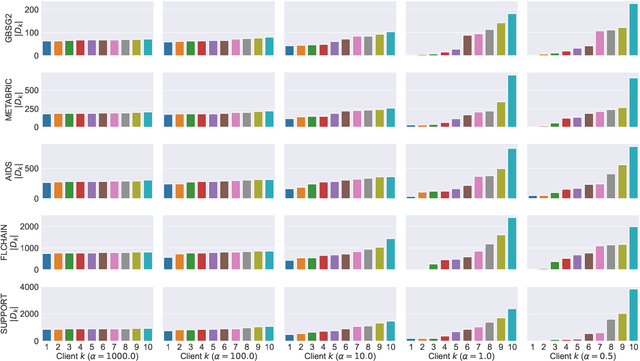
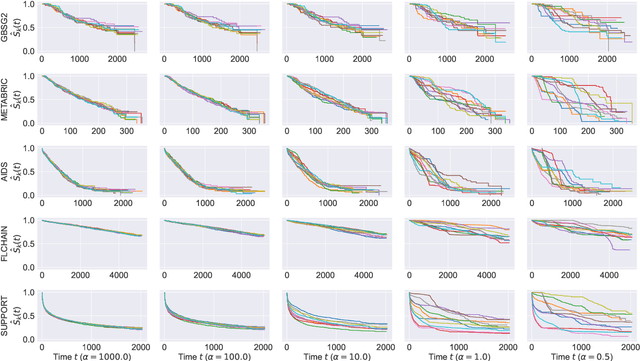
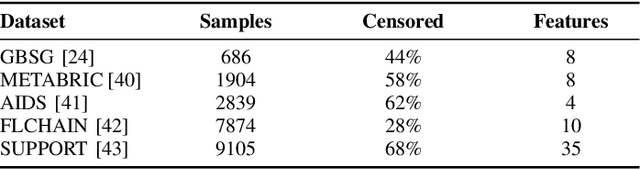
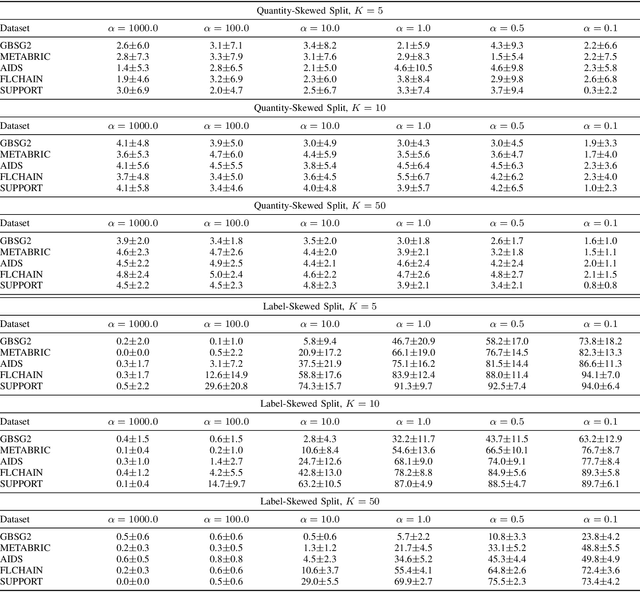
Survival analysis studies time-modeling techniques for an event of interest occurring for a population. Survival analysis found widespread applications in healthcare, engineering, and social sciences. However, the data needed to train survival models are often distributed, incomplete, censored, and confidential. In this context, federated learning can be exploited to tremendously improve the quality of the models trained on distributed data while preserving user privacy. However, federated survival analysis is still in its early development, and there is no common benchmarking dataset to test federated survival models. This work proposes a novel technique for constructing realistic heterogeneous datasets by starting from existing non-federated datasets in a reproducible way. Specifically, we provide two novel dataset-splitting algorithms based on the Dirichlet distribution to assign each data sample to a carefully chosen client: quantity-skewed splitting and label-skewed splitting. Furthermore, these algorithms allow for obtaining different levels of heterogeneity by changing a single hyperparameter. Finally, numerical experiments provide a quantitative evaluation of the heterogeneity level using log-rank tests and a qualitative analysis of the generated splits. The implementation of the proposed methods is publicly available in favor of reproducibility and to encourage common practices to simulate federated environments for survival analysis.
Neural Weighted A*: Learning Graph Costs and Heuristics with Differentiable Anytime A*
May 04, 2021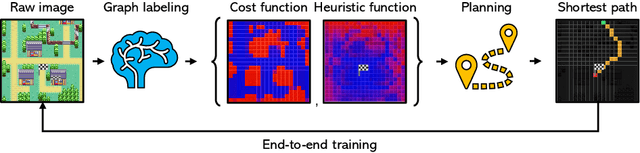

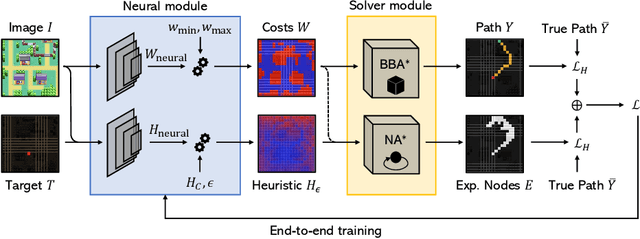

Recently, the trend of incorporating differentiable algorithms into deep learning architectures arose in machine learning research, as the fusion of neural layers and algorithmic layers has been beneficial for handling combinatorial data, such as shortest paths on graphs. Recent works related to data-driven planning aim at learning either cost functions or heuristic functions, but not both. We propose Neural Weighted A*, a differentiable anytime planner able to produce improved representations of planar maps as graph costs and heuristics. Training occurs end-to-end on raw images with direct supervision on planning examples, thanks to a differentiable A* solver integrated into the architecture. More importantly, the user can trade off planning accuracy for efficiency at run-time, using a single, real-valued parameter. The solution suboptimality is constrained within a linear bound equal to the optimal path cost multiplied by the tradeoff parameter. We experimentally show the validity of our claims by testing Neural Weighted A* against several baselines, introducing a novel, tile-based navigation dataset. We outperform similar architectures in planning accuracy and efficiency.