 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistinguishing Question Subjectivity from Difficulty for Improved Crowdsourcing
Paper and Code
Feb 14, 2018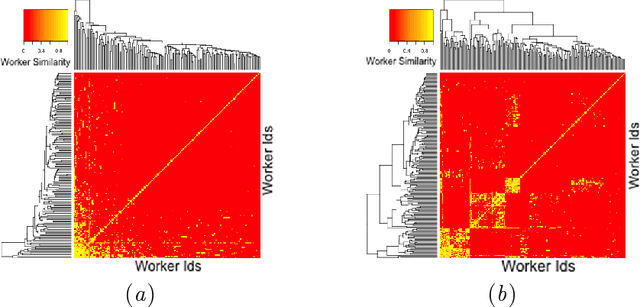

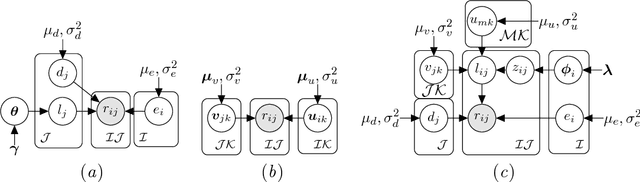
The questions in a crowdsourcing task typically exhibit varying degrees of difficulty and subjectivity. Their joint effects give rise to the variation in responses to the same question by different crowd-workers. This variation is low when the question is easy to answer and objective, and high when it is difficult and subjective. Unfortunately, current quality control methods for crowdsourcing consider only the question difficulty to account for the variation. As a result,these methods cannot distinguish workers personal preferences for different correct answers of a partially subjective question from their ability/expertise to avoid objectively wrong answers for that question. To address this issue, we present a probabilistic model which (i) explicitly encodes question difficulty as a model parameter and (ii) implicitly encodes question subjectivity via latent preference factors for crowd-workers. We show that question subjectivity induces grouping of crowd-workers, revealed through clustering of their latent preferences. Moreover, we develop a quantitative measure of the subjectivity of a question. Experiments show that our model(1) improves the performance of both quality control for crowd-sourced answers and next answer prediction for crowd-workers,and (2) can potentially provide coherent rankings of questions in terms of their difficulty and subjectivity, so that task providers can refine their designs of the crowdsourcing tasks, e.g. by removing highly subjective questions or inappropriately difficult questions.