 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Technical Survey on Statistical Modelling and Design Methods for Crowdsourcing Quality Control
Paper and Code
Dec 05, 2018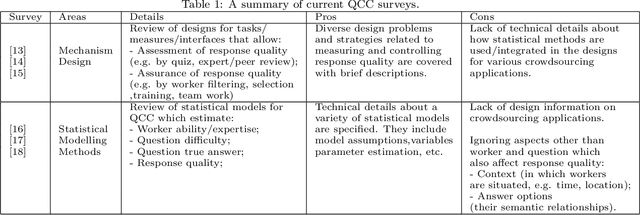
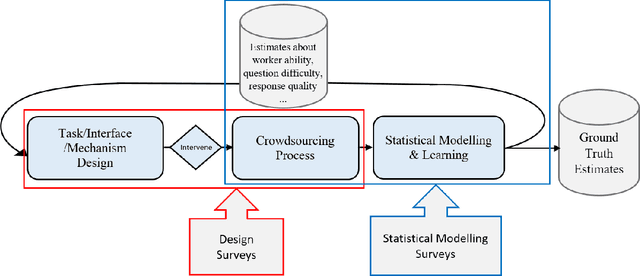
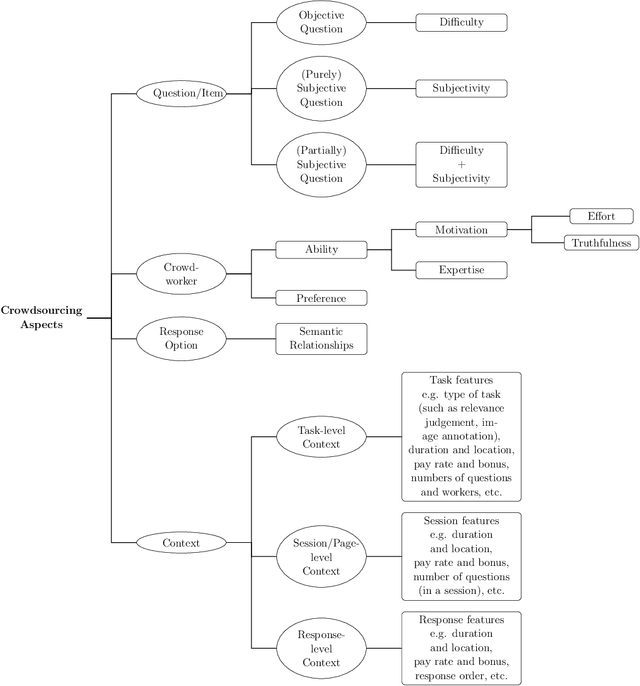
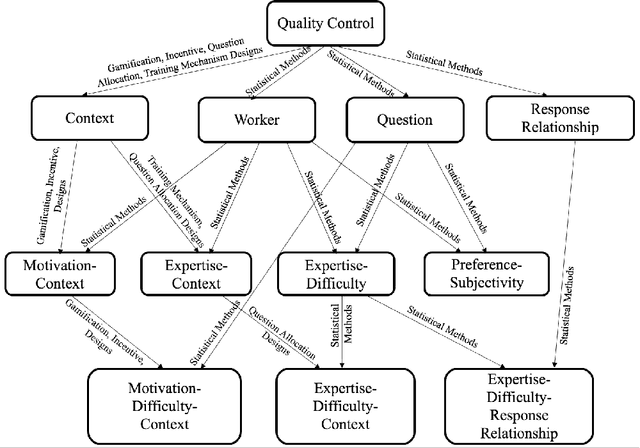
Online crowdsourcing provides a scalable and inexpensive means to collect knowledge (e.g. labels) about various types of data items (e.g. text, audio, video). However, it is also known to result in large variance in the quality of recorded responses which often cannot be directly used for training machine learning systems. To resolve this issue, a lot of work has been conducted to control the response quality such that low-quality responses cannot adversely affect the performance of the machine learning systems. Such work is referred to as the quality control for crowdsourcing. Past quality control research can be divided into two major branches: quality control mechanism design and statistical models. The first branch focuses on designing measures, thresholds, interfaces and workflows for payment, gamification, question assignment and other mechanisms that influence workers' behaviour. The second branch focuses on developing statistical models to perform effective aggregation of responses to infer correct responses. The two branches are connected as statistical models (i) provide parameter estimates to support the measure and threshold calculation, and (ii) encode modelling assumptions used to derive (theoretical) performance guarantees for the mechanisms. There are surveys regarding each branch but they lack technical details about the other branch. Our survey is the first to bridge the two branches by providing technical details on how they work together under frameworks that systematically unify crowdsourcing aspects modelled by both of them to determine the response quality. We are also the first to provide taxonomies of quality control papers based on the proposed frameworks. Finally, we specify the current limitations and the corresponding future directions for the quality control research.