 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpect the unexpected: Harnessing Sentence Completion for Sarcasm Detection
Paper and Code
Jul 19, 2017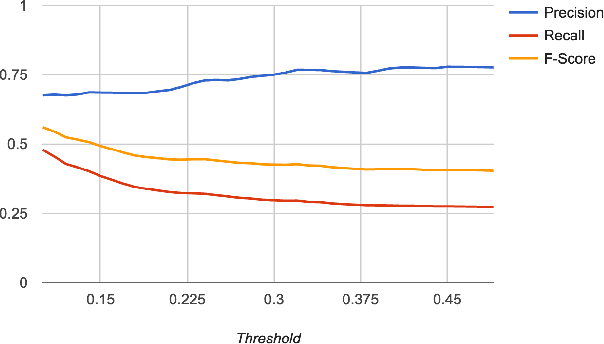
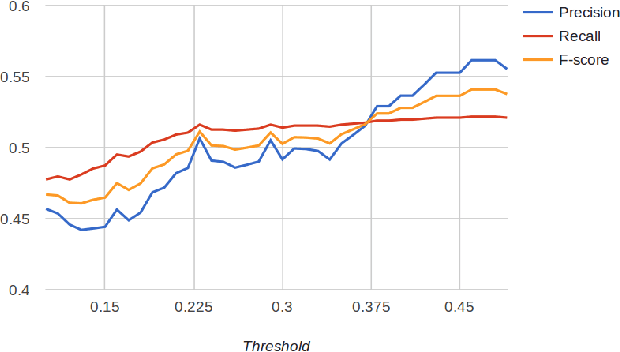
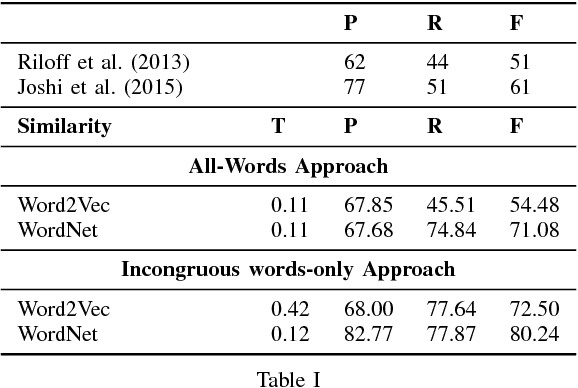
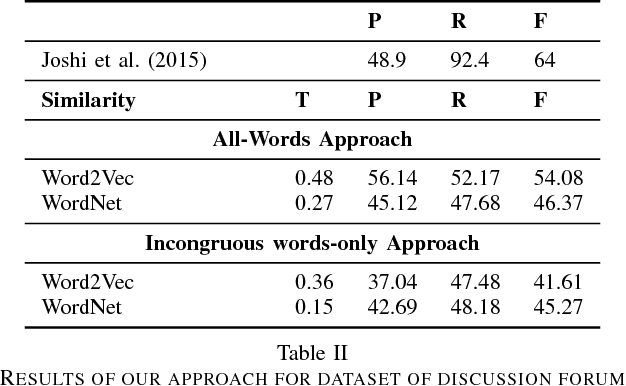
The trigram `I love being' is expected to be followed by positive words such as `happy'. In a sarcastic sentence, however, the word `ignored' may be observed. The expected and the observed words are, thus, incongruous. We model sarcasm detection as the task of detecting incongruity between an observed and an expected word. In order to obtain the expected word, we use Context2Vec, a sentence completion library based on Bidirectional LSTM. However, since the exact word where such an incongruity occurs may not be known in advance, we present two approaches: an All-words approach (which consults sentence completion for every content word) and an Incongruous words-only approach (which consults sentence completion for the 50% most incongruous content words). The approaches outperform reported values for tweets but not for discussion forum posts. This is likely to be because of redundant consultation of sentence completion for discussion forum posts. Therefore, we consider an oracle case where the exact incongruous word is manually labeled in a corpus reported in past work. In this case, the performance is higher than the all-words approach. This sets up the promise for using sentence completion for sarcasm detection.