 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAQVolt26: High-Temperature r$^2$SCAN Halide Dataset for Universal ML Potentials and Solid-State Batteries
Apr 02, 2026The demand for safe, high-energy-density batteries has spotlighted halide solid-state electrolytes, which offer the potential for enhanced ionic mobility, electrochemical stability, and interfacial deformability. Accelerating their discovery requires extensive molecular dynamics, which has been increasingly enabled by universal machine learning interatomic potentials trained on foundational datasets. However, the dynamic softness of halides poses a stringent test of whether general-purpose models can reliably replace first-principles calculations under the highly distorted, elevated-temperature regimes necessary to probe ion transport. Here, we present AQVolt26, a dataset of 322,656 r$^2$SCAN single-point calculations for lithium halides, generated via high-temperature configurational sampling across $\sim$5K structures. We demonstrate that foundational datasets provide a strong baseline for stable halide chemistries and transfer local forces well, however absolute energy predictions degrade in distorted higher-temperature regimes. Co-training with AQVolt26 resolves this blind spot. Furthermore, incorporating Materials Project relaxation data improves near-equilibrium performance but degrades extreme-strain robustness without enhancing high-temperature force accuracy. These results demonstrate that domain-specific configurational sampling is essential for the reliable dynamic screening of halide electrolytes. Furthermore, our findings suggest that while foundational models provide a robust base, they are most effective for dynamically soft solid-state chemistries when augmented with targeted, high-temperature data. Finally, we show that near-equilibrium relaxation data serves as a task-specific complement rather than a universally beneficial addition.
Bias-Aware Machine Unlearning: Towards Fairer Vision Models via Controllable Forgetting
Sep 09, 2025Deep neural networks often rely on spurious correlations in training data, leading to biased or unfair predictions in safety-critical domains such as medicine and autonomous driving. While conventional bias mitigation typically requires retraining from scratch or redesigning data pipelines, recent advances in machine unlearning provide a promising alternative for post-hoc model correction. In this work, we investigate \textit{Bias-Aware Machine Unlearning}, a paradigm that selectively removes biased samples or feature representations to mitigate diverse forms of bias in vision models. Building on privacy-preserving unlearning techniques, we evaluate various strategies including Gradient Ascent, LoRA, and Teacher-Student distillation. Through empirical analysis on three benchmark datasets, CUB-200-2011 (pose bias), CIFAR-10 (synthetic patch bias), and CelebA (gender bias in smile detection), we demonstrate that post-hoc unlearning can substantially reduce subgroup disparities, with improvements in demographic parity of up to \textbf{94.86\%} on CUB-200, \textbf{30.28\%} on CIFAR-10, and \textbf{97.37\%} on CelebA. These gains are achieved with minimal accuracy loss and with methods scoring an average of 0.62 across the 3 settings on the joint evaluation of utility, fairness, quality, and privacy. Our findings establish machine unlearning as a practical framework for enhancing fairness in deployed vision systems without necessitating full retraining.
Early-Cycle Internal Impedance Enables ML-Based Battery Cycle Life Predictions Across Manufacturers
Oct 05, 2024Predicting the end-of-life (EOL) of lithium-ion batteries across different manufacturers presents significant challenges due to variations in electrode materials, manufacturing processes, cell formats, and a lack of generally available data. Methods that construct features solely on voltage-capacity profile data typically fail to generalize across cell chemistries. This study introduces a methodology that combines traditional voltage-capacity features with Direct Current Internal Resistance (DCIR) measurements, enabling more accurate and generalizable EOL predictions. The use of early-cycle DCIR data captures critical degradation mechanisms related to internal resistance growth, enhancing model robustness. Models are shown to successfully predict the number of cycles to EOL for unseen manufacturers of varied electrode composition with a mean absolute error (MAE) of 150 cycles. This cross-manufacturer generalizability reduces the need for extensive new data collection and retraining, enabling manufacturers to optimize new battery designs using existing datasets. Additionally, a novel DCIR-compatible dataset is released as part of ongoing efforts to enrich the growing ecosystem of cycling data and accelerate battery materials development.
EaZy Learning: An Adaptive Variant of Ensemble Learning for Fingerprint Liveness Detection
Mar 03, 2021
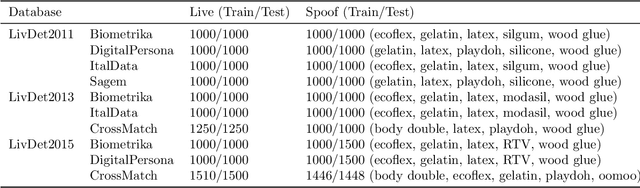
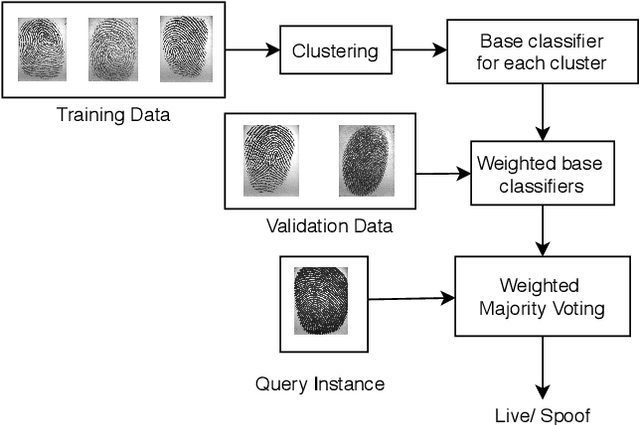
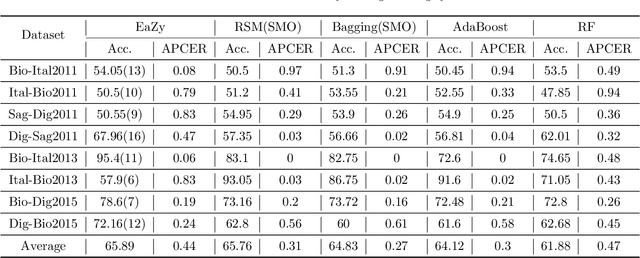
In the field of biometrics, fingerprint recognition systems are vulnerable to presentation attacks made by artificially generated spoof fingerprints. Therefore, it is essential to perform liveness detection of a fingerprint before authenticating it. Fingerprint liveness detection mechanisms perform well under the within-dataset environment but fail miserably under cross-sensor (when tested on a fingerprint acquired by a new sensor) and cross-dataset (when trained on one dataset and tested on another) settings. To enhance the generalization abilities, robustness and the interoperability of the fingerprint spoof detectors, the learning models need to be adaptive towards the data. We propose a generic model, EaZy learning which can be considered as an adaptive midway between eager and lazy learning. We show the usefulness of this adaptivity under cross-sensor and cross-dataset environments. EaZy learning examines the properties intrinsic to the dataset while generating a pool of hypotheses. EaZy learning is similar to ensemble learning as it generates an ensemble of base classifiers and integrates them to make a prediction. Still, it differs in the way it generates the base classifiers. EaZy learning develops an ensemble of entirely disjoint base classifiers which has a beneficial influence on the diversity of the underlying ensemble. Also, it integrates the predictions made by these base classifiers based on their performance on the validation data. Experiments conducted on the standard high dimensional datasets LivDet 2011, LivDet 2013 and LivDet 2015 prove the efficacy of the model under cross-dataset and cross-sensor environments.
AILearn: An Adaptive Incremental Learning Model for Spoof Fingerprint Detection
Dec 29, 2020
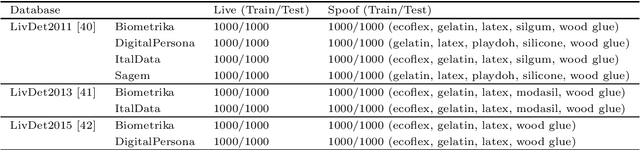
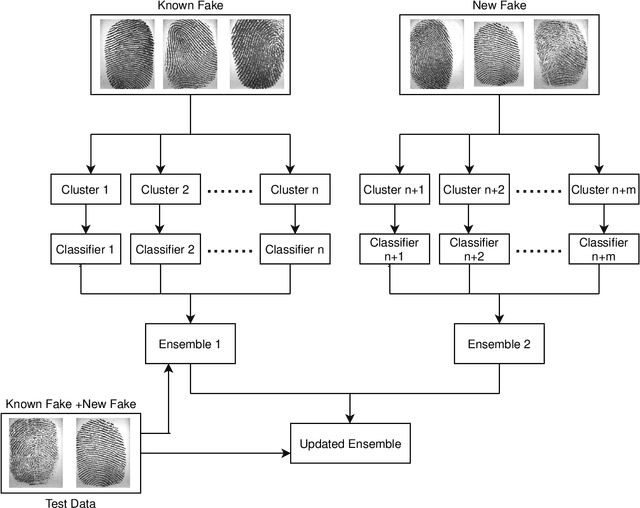
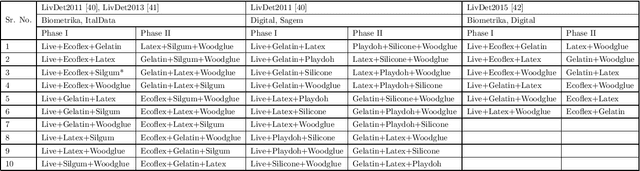
Incremental learning enables the learner to accommodate new knowledge without retraining the existing model. It is a challenging task which requires learning from new data as well as preserving the knowledge extracted from the previously accessed data. This challenge is known as the stability-plasticity dilemma. We propose AILearn, a generic model for incremental learning which overcomes the stability-plasticity dilemma by carefully integrating the ensemble of base classifiers trained on new data with the current ensemble without retraining the model from scratch using entire data. We demonstrate the efficacy of the proposed AILearn model on spoof fingerprint detection application. One of the significant challenges associated with spoof fingerprint detection is the performance drop on spoofs generated using new fabrication materials. AILearn is an adaptive incremental learning model which adapts to the features of the ``live'' and ``spoof'' fingerprint images and efficiently recognizes the new spoof fingerprints as well as the known spoof fingerprints when the new data is available. To the best of our knowledge, AILearn is the first attempt in incremental learning algorithms that adapts to the properties of data for generating a diverse ensemble of base classifiers. From the experiments conducted on standard high-dimensional datasets LivDet 2011, LivDet 2013 and LivDet 2015, we show that the performance gain on new fake materials is significantly high. On an average, we achieve $49.57\%$ improvement in accuracy between the consecutive learning phases.
EILearn: Learning Incrementally Using Previous Knowledge Obtained From an Ensemble of Classifiers
Feb 08, 2019

We propose an algorithm for incremental learning of classifiers. The proposed method enables an ensemble of classifiers to learn incrementally by accommodating new training data. We use an effective mechanism to overcome the stability-plasticity dilemma. In incremental learning, the general convention is to use only the knowledge acquired in the previous phase but not the previously seen data. We follow this convention by retaining the previously acquired knowledge which is relevant and using it along with the current data. The performance of each classifier is monitored to eliminate the poorly performing classifiers in the subsequent phases. Experimental results show that the proposed approach outperforms the existing incremental learning approaches.
Structuring an unordered text document
Jan 29, 2019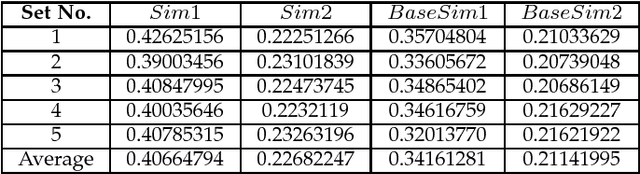
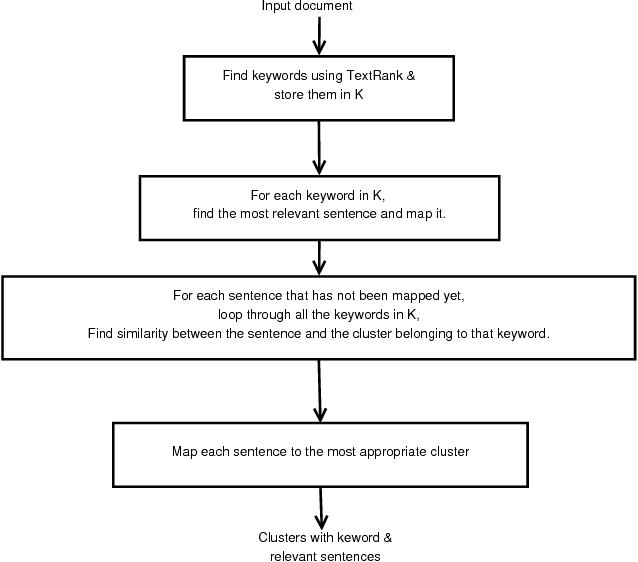
Segmenting an unordered text document into different sections is a very useful task in many text processing applications like multiple document summarization, question answering, etc. This paper proposes structuring of an unordered text document based on the keywords in the document. We test our approach on Wikipedia documents using both statistical and predictive methods such as the TextRank algorithm and Google's USE (Universal Sentence Encoder). From our experimental results, we show that the proposed model can effectively structure an unordered document into sections.
Recent Advances in Object Detection in the Age of Deep Convolutional Neural Networks
Sep 10, 2018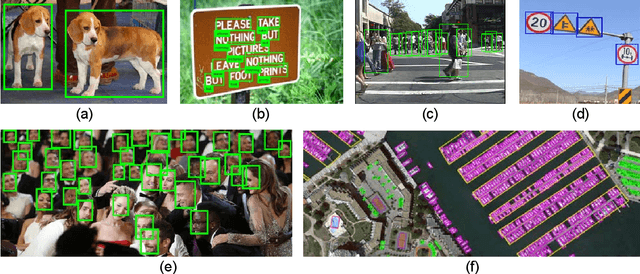
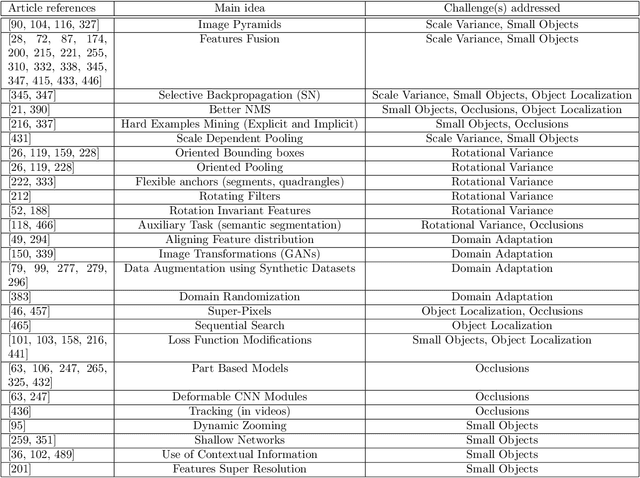
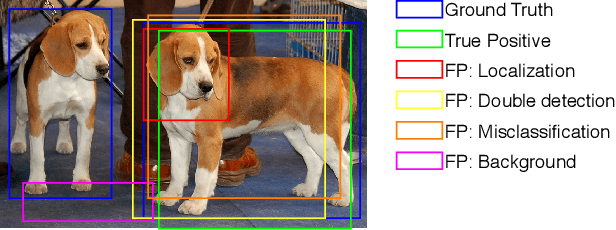

Object detection-the computer vision task dealing with detecting instances of objects of a certain class (e.g., 'car', 'plane', etc.) in images-attracted a lot of attention from the community during the last 5 years. This strong interest can be explained not only by the importance this task has for many applications but also by the phenomenal advances in this area since the arrival of deep convolutional neural networks (DCNN). This article reviews the recent literature on object detection with deep CNN, in a comprehensive way, and provides an in-depth view of these recent advances. The survey covers not only the typical architectures (SSD, YOLO, Faster-RCNN) but also discusses the challenges currently met by the community and goes on to show how the problem of object detection can be extended. This survey also reviews the public datasets and associated state-of-the-art algorithms.