 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpressive Acoustic Guitar Sound Synthesis with an Instrument-Specific Input Representation and Diffusion Outpainting
Jan 24, 2024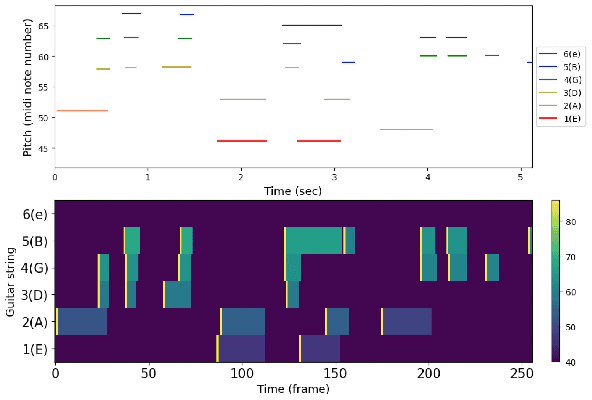
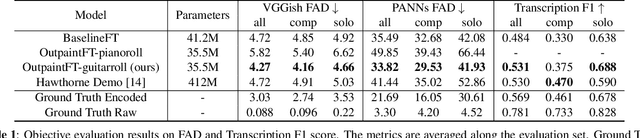
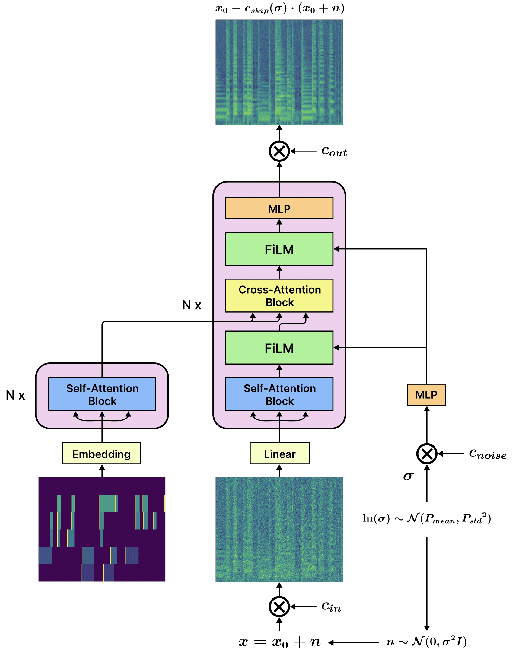
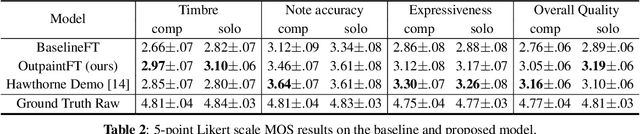
Synthesizing performing guitar sound is a highly challenging task due to the polyphony and high variability in expression. Recently, deep generative models have shown promising results in synthesizing expressive polyphonic instrument sounds from music scores, often using a generic MIDI input. In this work, we propose an expressive acoustic guitar sound synthesis model with a customized input representation to the instrument, which we call guitarroll. We implement the proposed approach using diffusion-based outpainting which can generate audio with long-term consistency. To overcome the lack of MIDI/audio-paired datasets, we used not only an existing guitar dataset but also collected data from a high quality sample-based guitar synthesizer. Through quantitative and qualitative evaluations, we show that our proposed model has higher audio quality than the baseline model and generates more realistic timbre sounds than the previous leading work.
Neural Vocoder Feature Estimation for Dry Singing Voice Separation
Nov 29, 2022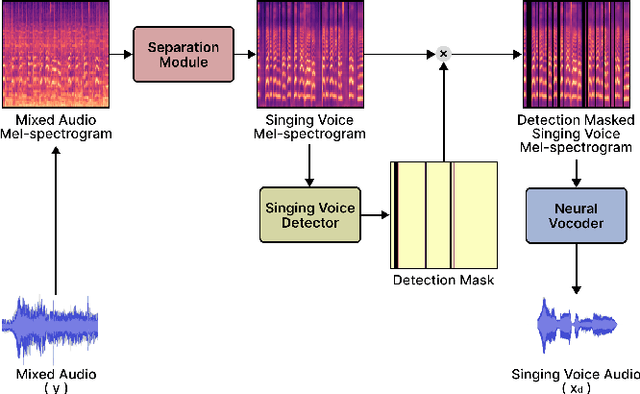
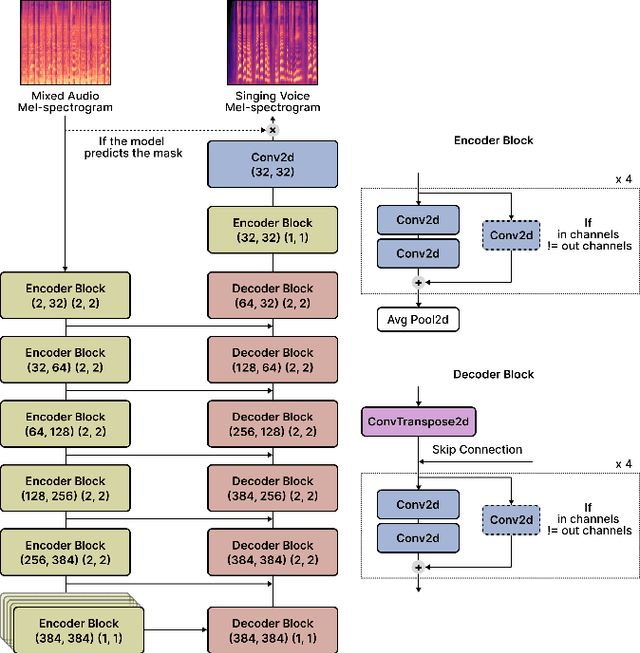
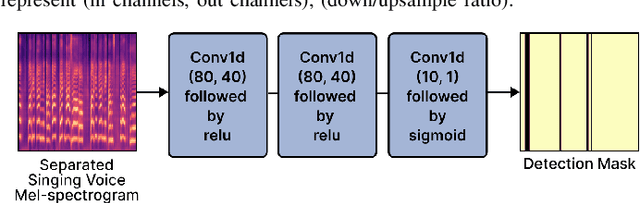

Singing voice separation (SVS) is a task that separates singing voice audio from its mixture with instrumental audio. Previous SVS studies have mainly employed the spectrogram masking method which requires a large dimensionality in predicting the binary masks. In addition, they focused on extracting a vocal stem that retains the wet sound with the reverberation effect. This result may hinder the reusability of the isolated singing voice. This paper addresses the issues by predicting mel-spectrogram of dry singing voices from the mixed audio as neural vocoder features and synthesizing the singing voice waveforms from the neural vocoder. We experimented with two separation methods. One is predicting binary masks in the mel-spectrogram domain and the other is directly predicting the mel-spectrogram. Furthermore, we add a singing voice detector to identify the singing voice segments over time more explicitly. We measured the model performance in terms of audio, dereverberation, separation, and overall quality. The results show that our proposed model outperforms state-of-the-art singing voice separation models in both objective and subjective evaluation except the audio quality.
* 6 pages, 4 figures
A Melody-Unsupervision Model for Singing Voice Synthesis
Oct 13, 2021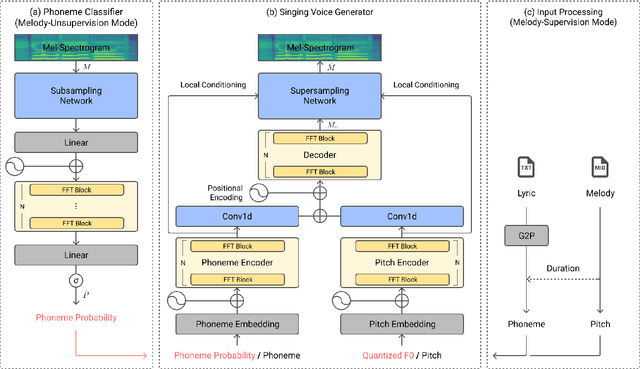

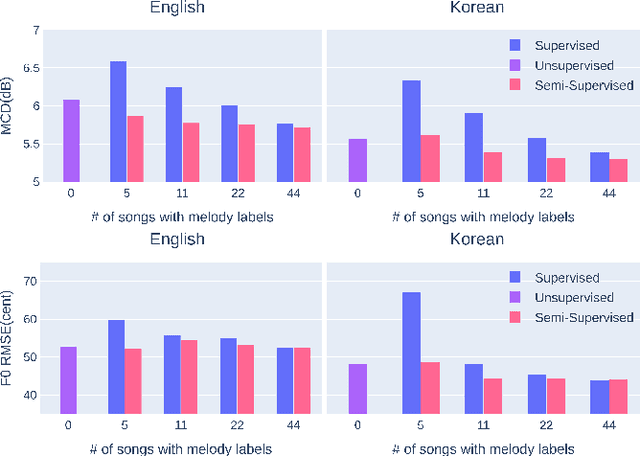
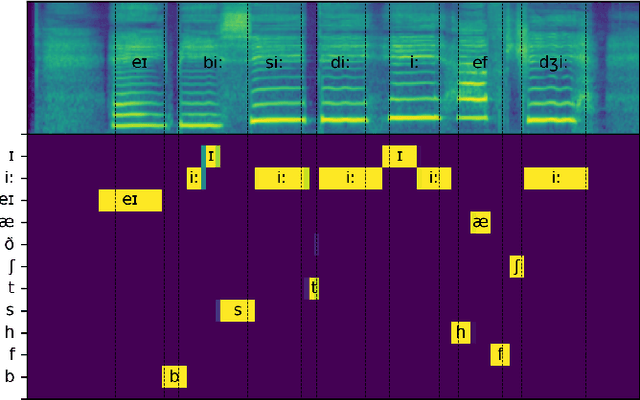
Recent studies in singing voice synthesis have achieved high-quality results leveraging advances in text-to-speech models based on deep neural networks. One of the main issues in training singing voice synthesis models is that they require melody and lyric labels to be temporally aligned with audio data. The temporal alignment is a time-exhausting manual work in preparing for the training data. To address the issue, we propose a melody-unsupervision model that requires only audio-and-lyrics pairs without temporal alignment in training time but generates singing voice audio given a melody and lyrics input in inference time. The proposed model is composed of a phoneme classifier and a singing voice generator jointly trained in an end-to-end manner. The model can be fine-tuned by adjusting the amount of supervision with temporally aligned melody labels. Through experiments in melody-unsupervision and semi-supervision settings, we compare the audio quality of synthesized singing voice. We also show that the proposed model is capable of being trained with speech audio and text labels but can generate singing voice in inference time.