 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Melody-Unsupervision Model for Singing Voice Synthesis
Paper and Code
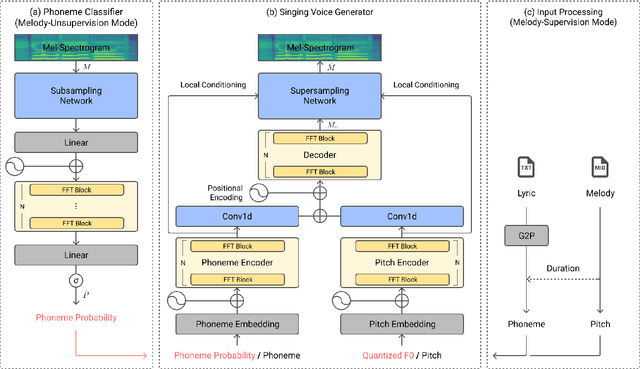

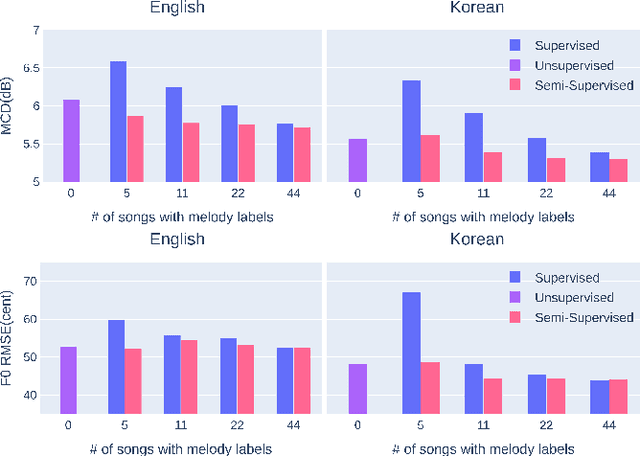
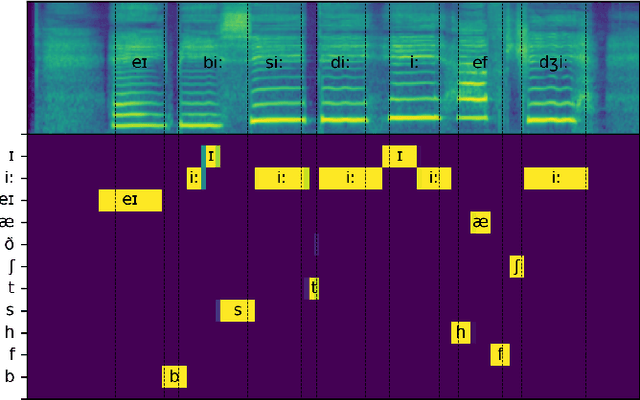
Recent studies in singing voice synthesis have achieved high-quality results leveraging advances in text-to-speech models based on deep neural networks. One of the main issues in training singing voice synthesis models is that they require melody and lyric labels to be temporally aligned with audio data. The temporal alignment is a time-exhausting manual work in preparing for the training data. To address the issue, we propose a melody-unsupervision model that requires only audio-and-lyrics pairs without temporal alignment in training time but generates singing voice audio given a melody and lyrics input in inference time. The proposed model is composed of a phoneme classifier and a singing voice generator jointly trained in an end-to-end manner. The model can be fine-tuned by adjusting the amount of supervision with temporally aligned melody labels. Through experiments in melody-unsupervision and semi-supervision settings, we compare the audio quality of synthesized singing voice. We also show that the proposed model is capable of being trained with speech audio and text labels but can generate singing voice in inference time.