 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTräumerAI: Dreaming Music with StyleGAN
Paper and Code
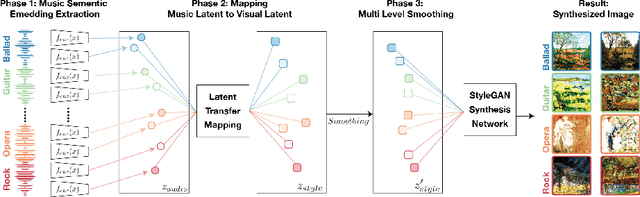


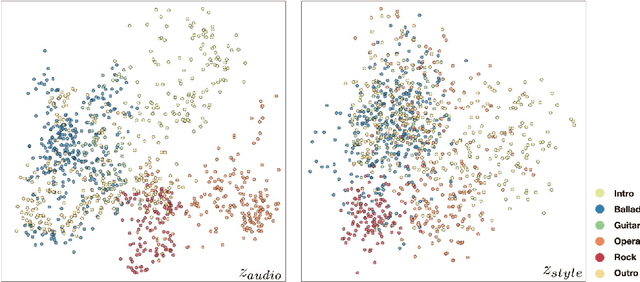
The goal of this paper to generate a visually appealing video that responds to music with a neural network so that each frame of the video reflects the musical characteristics of the corresponding audio clip. To achieve the goal, we propose a neural music visualizer directly mapping deep music embeddings to style embeddings of StyleGAN, named Tr\"aumerAI, which consists of a music auto-tagging model using short-chunk CNN and StyleGAN2 pre-trained on WikiArt dataset. Rather than establishing an objective metric between musical and visual semantics, we manually labeled the pairs in a subjective manner. An annotator listened to 100 music clips of 10 seconds long and selected an image that suits the music among the 200 StyleGAN-generated examples. Based on the collected data, we trained a simple transfer function that converts an audio embedding to a style embedding. The generated examples show that the mapping between audio and video makes a certain level of intra-segment similarity and inter-segment dissimilarity.