 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Investigation into Pre-Training Object-Centric Representations for Reinforcement Learning
Paper and Code
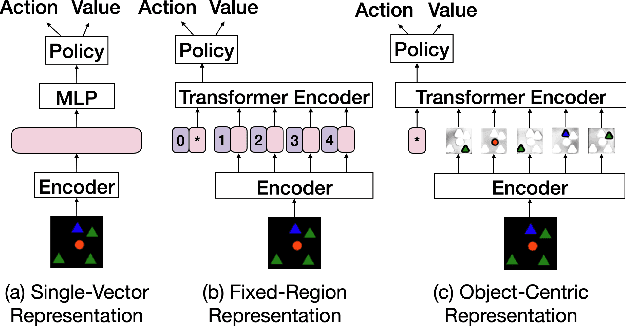
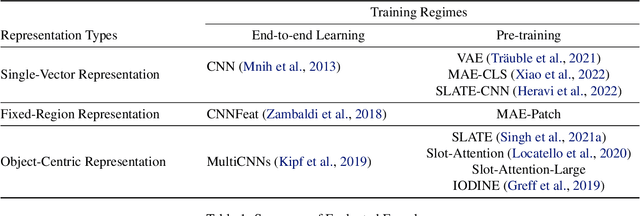
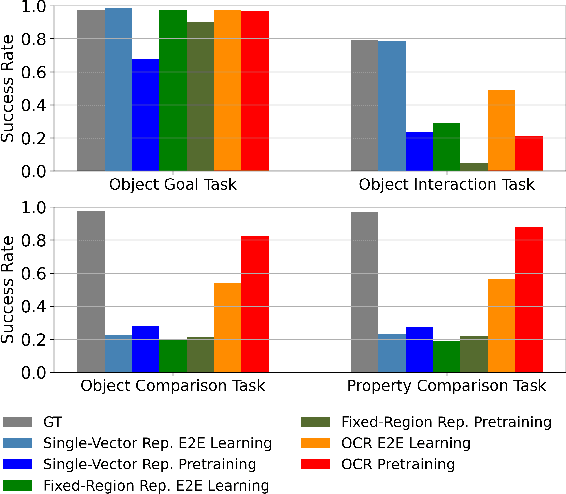
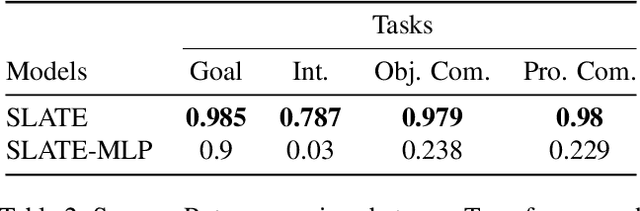
Unsupervised object-centric representation (OCR) learning has recently drawn attention as a new paradigm of visual representation. This is because of its potential of being an effective pre-training technique for various downstream tasks in terms of sample efficiency, systematic generalization, and reasoning. Although image-based reinforcement learning (RL) is one of the most important and thus frequently mentioned such downstream tasks, the benefit in RL has surprisingly not been investigated systematically thus far. Instead, most of the evaluations have focused on rather indirect metrics such as segmentation quality and object property prediction accuracy. In this paper, we investigate the effectiveness of OCR pre-training for image-based reinforcement learning via empirical experiments. For systematic evaluation, we introduce a simple object-centric visual RL benchmark and conduct experiments to answer questions such as ``Does OCR pre-training improve performance on object-centric tasks?'' and ``Can OCR pre-training help with out-of-distribution generalization?''. Our results provide empirical evidence for valuable insights into the effectiveness of OCR pre-training for RL and the potential limitations of its use in certain scenarios. Additionally, this study also examines the critical aspects of incorporating OCR pre-training in RL, including performance in a visually complex environment and the appropriate pooling layer to aggregate the object representations.