 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploration strategies for articulatory synthesis of complex syllable onsets
Apr 20, 2022



High-quality articulatory speech synthesis has many potential applications in speech science and technology. However, developing appropriate mappings from linguistic specification to articulatory gestures is difficult and time consuming. In this paper we construct an optimisation-based framework as a first step towards learning these mappings without manual intervention. We demonstrate the production of syllables with complex onsets and discuss the quality of the articulatory gestures with reference to coarticulation.
PyRCN: Exploration and Application of ESNs
Mar 08, 2021
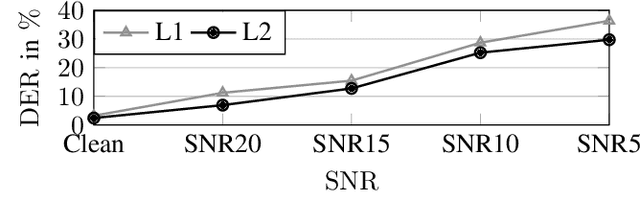


As a family member of Recurrent Neural Networks and similar to Long-Short-Term Memory cells, Echo State Networks (ESNs) are capable of solving temporal tasks, but with a substantially easier training paradigm based on linear regression. However, optimizing hyper-parameters and efficiently implementing the training process might be somewhat overwhelming for the first-time users of ESNs. This paper aims to facilitate the understanding of ESNs in theory and practice. Treating ESNs as non-linear filters, we explain the effect of the hyper-parameters using familiar concepts such as impulse responses. Furthermore, the paper introduces the Python toolbox PyRCN (Python Reservoir Computing Network) for developing, training and analyzing ESNs on arbitrarily large datasets. The tool is based on widely-used scientific packages, such as numpy and scipy and offers an interface to scikit-learn. Example code and results for classification and regression tasks are provided.
Cluster-based Input Weight Initialization for Echo State Networks
Mar 08, 2021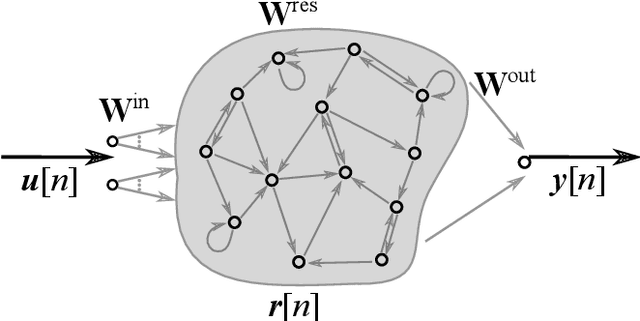
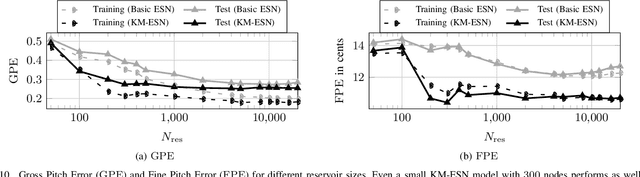
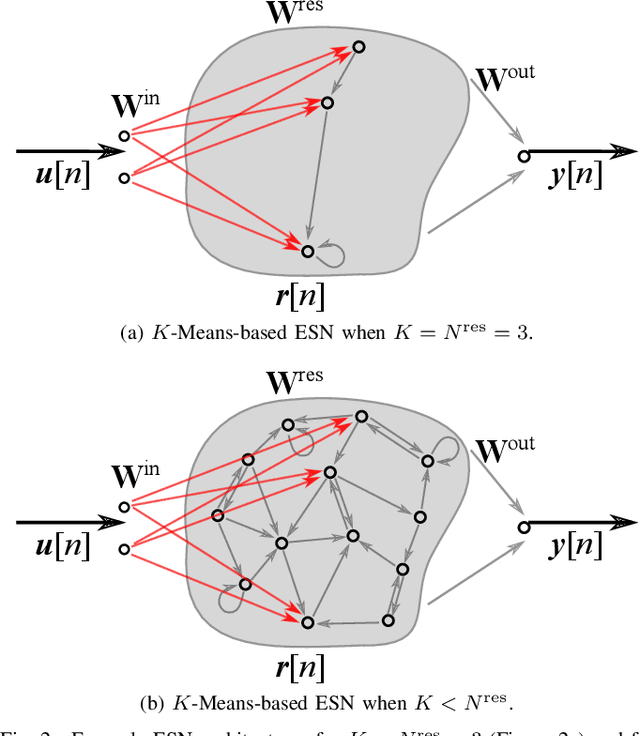
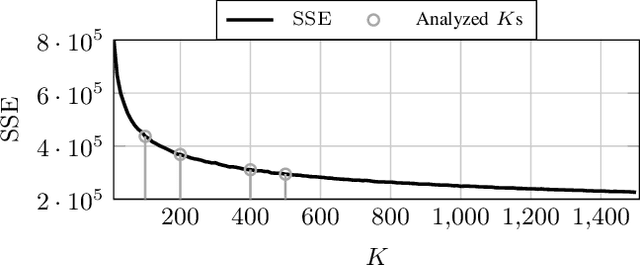
Echo State Networks (ESNs) are a special type of recurrent neural networks (RNNs), in which the input and recurrent connections are traditionally generated randomly, and only the output weights are trained. Despite the recent success of ESNs in various tasks of audio, image and radar recognition, we postulate that a purely random initialization is not the ideal way of initializing ESNs. The aim of this work is to propose an unsupervised initialization of the input connections using the K-Means algorithm on the training data. We show that this initialization performs equivalently or superior than a randomly initialized ESN whilst needing significantly less reservoir neurons (2000 vs. 4000 for spoken digit recognition, and 300 vs. 8000 neurons for f0 extraction) and thus reducing the amount of training time. Furthermore, we discuss that this approach provides the opportunity to estimate the suitable size of the reservoir based on the prior knowledge about the data.