 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple Code Hashing for Efficient Image Retrieval
Aug 04, 2020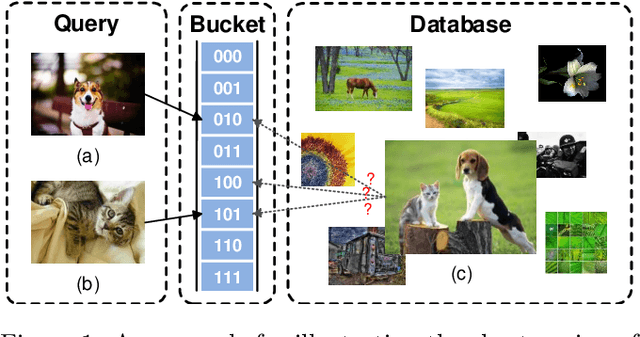

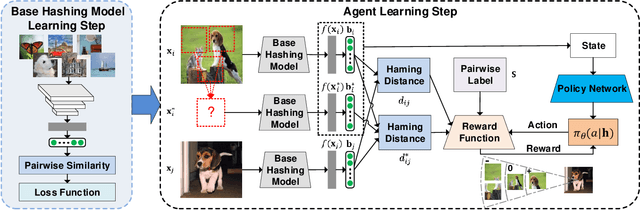
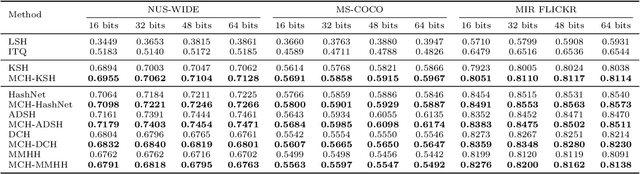
Due to its low storage cost and fast query speed, hashing has been widely used in large-scale image retrieval tasks. Hash bucket search returns data points within a given Hamming radius to each query, which can enable search at a constant or sub-linear time cost. However, existing hashing methods cannot achieve satisfactory retrieval performance for hash bucket search in complex scenarios, since they learn only one hash code for each image. More specifically, by using one hash code to represent one image, existing methods might fail to put similar image pairs to the buckets with a small Hamming distance to the query when the semantic information of images is complex. As a result, a large number of hash buckets need to be visited for retrieving similar images, based on the learned codes. This will deteriorate the efficiency of hash bucket search. In this paper, we propose a novel hashing framework, called multiple code hashing (MCH), to improve the performance of hash bucket search. The main idea of MCH is to learn multiple hash codes for each image, with each code representing a different region of the image. Furthermore, we propose a deep reinforcement learning algorithm to learn the parameters in MCH. To the best of our knowledge, this is the first work that proposes to learn multiple hash codes for each image in image retrieval. Experiments demonstrate that MCH can achieve a significant improvement in hash bucket search, compared with existing methods that learn only one hash code for each image.
Deep Multi-Index Hashing for Person Re-Identification
May 27, 2019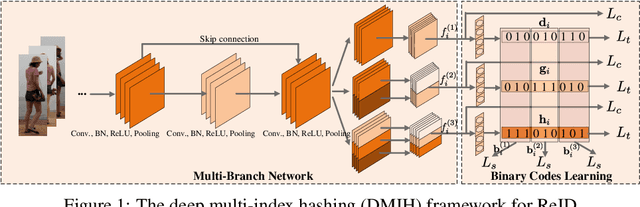
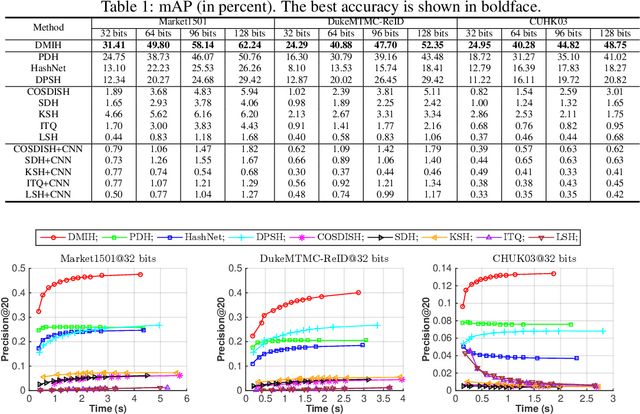
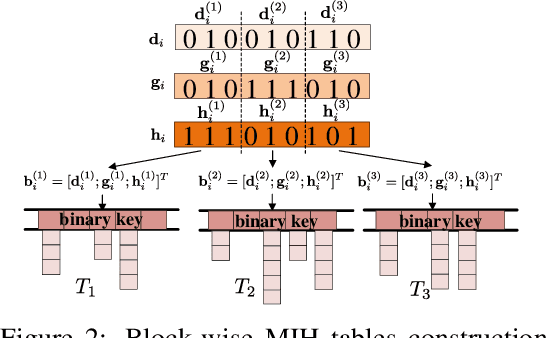
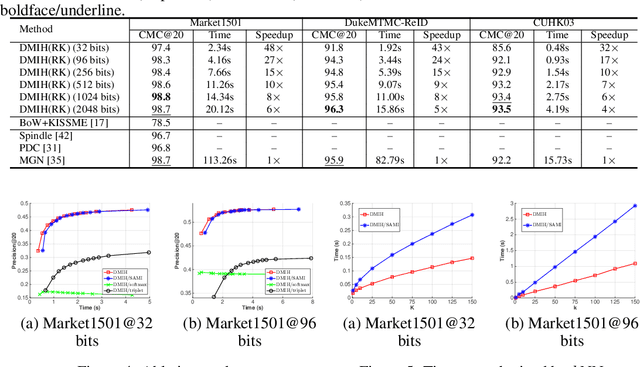
Traditional person re-identification (ReID) methods typically represent person images as real-valued features, which makes ReID inefficient when the gallery set is extremely large. Recently, some hashing methods have been proposed to make ReID more efficient. However, these hashing methods will deteriorate the accuracy in general, and the efficiency of them is still not high enough. In this paper, we propose a novel hashing method, called deep multi-index hashing (DMIH), to improve both efficiency and accuracy for ReID. DMIH seamlessly integrates multi-index hashing and multi-branch based networks into the same framework. Furthermore, a novel block-wise multi-index hashing table construction approach and a search-aware multi-index (SAMI) loss are proposed in DMIH to improve the search efficiency. Experiments on three widely used datasets show that DMIH can outperform other state-of-the-art baselines, including both hashing methods and real-valued methods, in terms of both efficiency and accuracy.
Proximal SCOPE for Distributed Sparse Learning: Better Data Partition Implies Faster Convergence Rate
Oct 26, 2018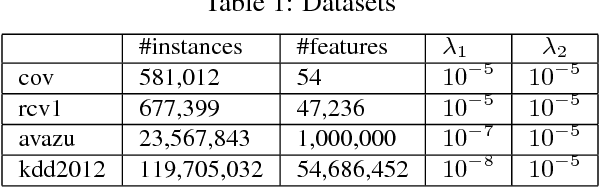
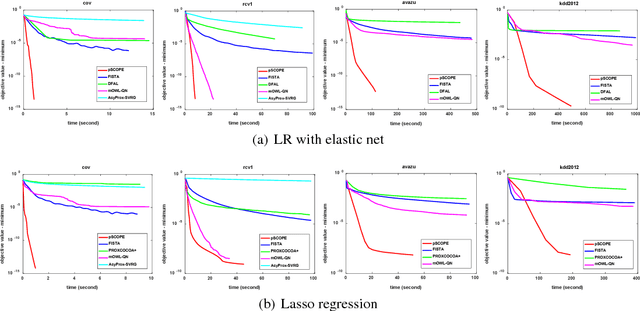
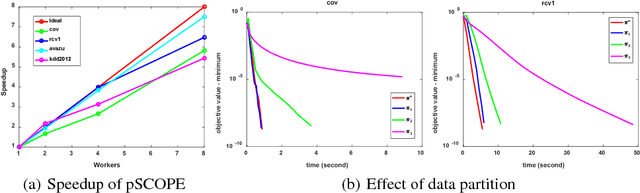
Distributed sparse learning with a cluster of multiple machines has attracted much attention in machine learning, especially for large-scale applications with high-dimensional data. One popular way to implement sparse learning is to use $L_1$ regularization. In this paper, we propose a novel method, called proximal \mbox{SCOPE}~(\mbox{pSCOPE}), for distributed sparse learning with $L_1$ regularization. pSCOPE is based on a \underline{c}ooperative \underline{a}utonomous \underline{l}ocal \underline{l}earning~(\mbox{CALL}) framework. In the \mbox{CALL} framework of \mbox{pSCOPE}, we find that the data partition affects the convergence of the learning procedure, and subsequently we define a metric to measure the goodness of a data partition. Based on the defined metric, we theoretically prove that pSCOPE is convergent with a linear convergence rate if the data partition is good enough. We also prove that better data partition implies faster convergence rate. Furthermore, pSCOPE is also communication efficient. Experimental results on real data sets show that pSCOPE can outperform other state-of-the-art distributed methods for sparse learning.