 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscriminability-Transferability Trade-Off: An Information-Theoretic Perspective
Mar 08, 2022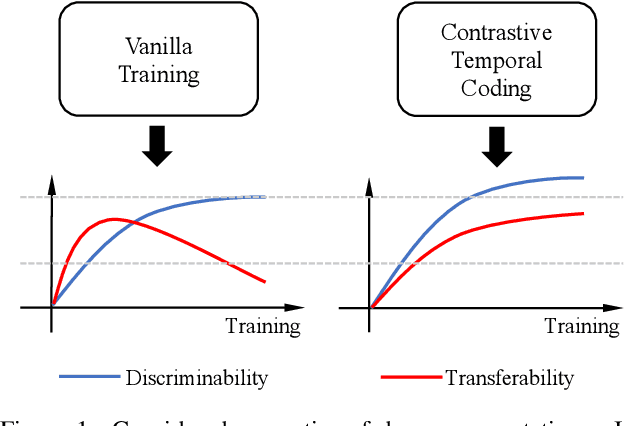

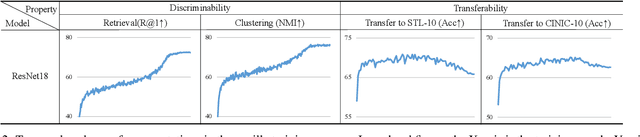

This work simultaneously considers the discriminability and transferability properties of deep representations in the typical supervised learning task, i.e., image classification. By a comprehensive temporal analysis, we observe a trade-off between these two properties. The discriminability keeps increasing with the training progressing while the transferability intensely diminishes in the later training period. From the perspective of information-bottleneck theory, we reveal that the incompatibility between discriminability and transferability is attributed to the over-compression of input information. More importantly, we investigate why and how the InfoNCE loss can alleviate the over-compression, and further present a learning framework, named contrastive temporal coding~(CTC), to counteract the over-compression and alleviate the incompatibility. Extensive experiments validate that CTC successfully mitigates the incompatibility, yielding discriminative and transferable representations. Noticeable improvements are achieved on the image classification task and challenging transfer learning tasks. We hope that this work will raise the significance of the transferability property in the conventional supervised learning setting. Code will be publicly available.
Hierarchical Context Embedding for Region-based Object Detection
Aug 04, 2020



State-of-the-art two-stage object detectors apply a classifier to a sparse set of object proposals, relying on region-wise features extracted by RoIPool or RoIAlign as inputs. The region-wise features, in spite of aligning well with the proposal locations, may still lack the crucial context information which is necessary for filtering out noisy background detections, as well as recognizing objects possessing no distinctive appearances. To address this issue, we present a simple but effective Hierarchical Context Embedding (HCE) framework, which can be applied as a plug-and-play component, to facilitate the classification ability of a series of region-based detectors by mining contextual cues. Specifically, to advance the recognition of context-dependent object categories, we propose an image-level categorical embedding module which leverages the holistic image-level context to learn object-level concepts. Then, novel RoI features are generated by exploiting hierarchically embedded context information beneath both whole images and interested regions, which are also complementary to conventional RoI features. Moreover, to make full use of our hierarchical contextual RoI features, we propose the early-and-late fusion strategies (i.e., feature fusion and confidence fusion), which can be combined to boost the classification accuracy of region-based detectors. Comprehensive experiments demonstrate that our HCE framework is flexible and generalizable, leading to significant and consistent improvements upon various region-based detectors, including FPN, Cascade R-CNN and Mask R-CNN.
BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition
Dec 13, 2019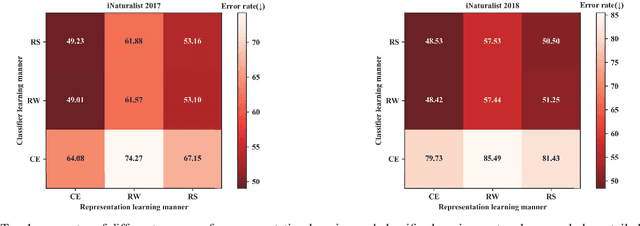

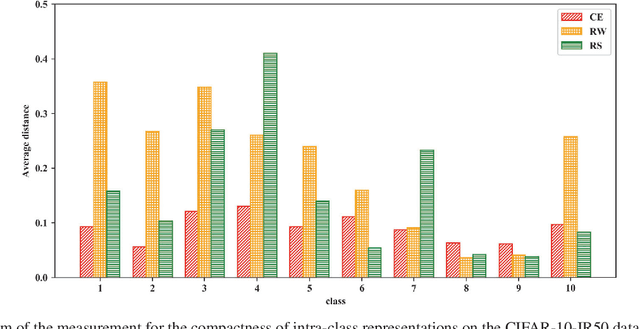
Our work focuses on tackling the challenging but natural visual recognition task of long-tailed data distribution (i.e., a few classes occupy most of the data, while most classes have rarely few samples). In the literature, class re-balancing strategies (e.g., re-weighting and re-sampling) are the prominent and effective methods proposed to alleviate the extreme imbalance for dealing with long-tailed problems. In this paper, we firstly discover that these re-balancing methods achieving satisfactory recognition accuracy owes to that they could significantly promote the classifier learning of deep networks. However, at the same time, they will unexpectedly damage the representative ability of the learned deep features to some extent. Therefore, we propose a unified Bilateral-Branch Network (BBN) to take care of both representation learning and classifier learning simultaneously, where each branch does perform its own duty separately. In particular, our BBN model is further equipped with a novel cumulative learning strategy, which is designed to first learn the universal patterns and then pay attention to the tail data gradually. Extensive experiments on four benchmark datasets, including the large-scale iNaturalist ones, justify that the proposed BBN can significantly outperform state-of-the-art methods. Furthermore, validation experiments can demonstrate both our preliminary discovery and effectiveness of tailored designs in BBN for long-tailed problems. Our method won the first place in the iNaturalist 2019 large scale species classification competition, and our code is open-source and available at https://github.com/Megvii-Nanjing/BBN.
Multi-Label Image Recognition with Graph Convolutional Networks
Apr 07, 2019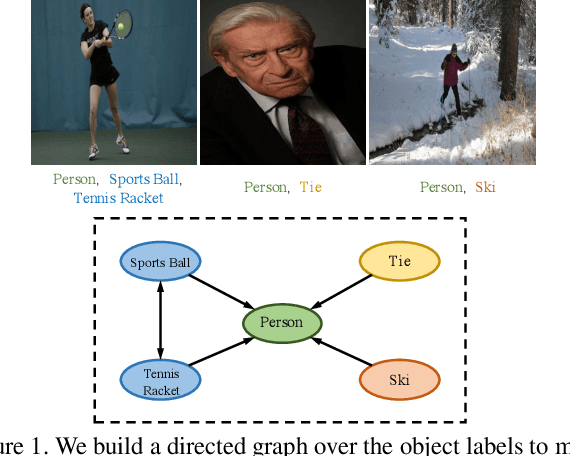
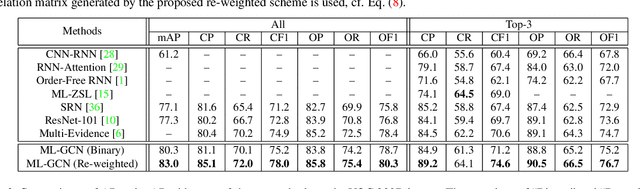
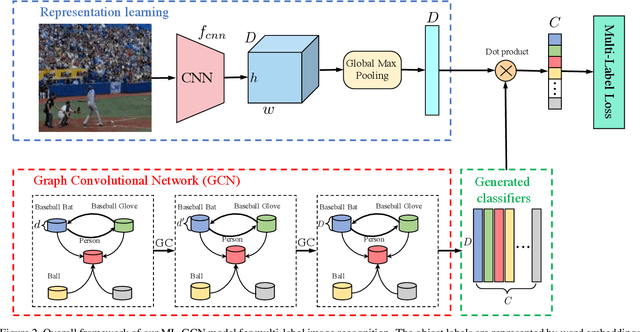
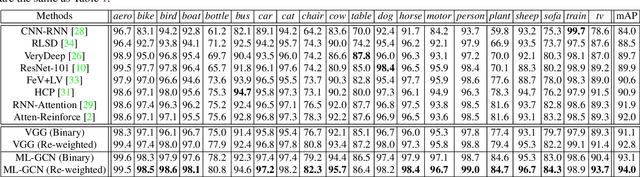
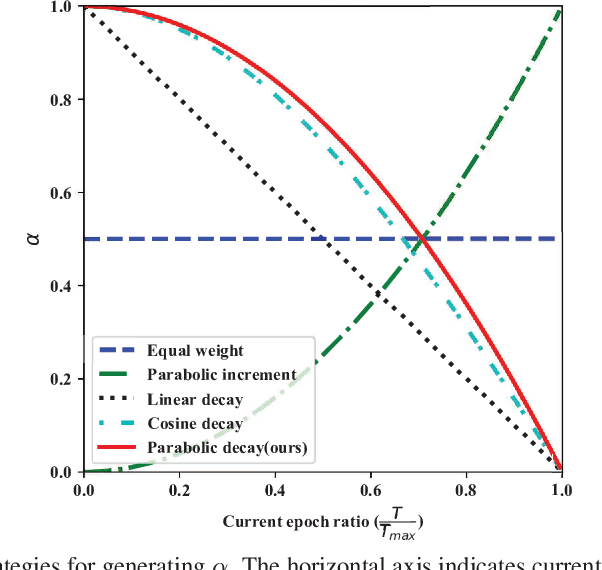
The task of multi-label image recognition is to predict a set of object labels that present in an image. As objects normally co-occur in an image, it is desirable to model the label dependencies to improve the recognition performance. To capture and explore such important dependencies, we propose a multi-label classification model based on Graph Convolutional Network (GCN). The model builds a directed graph over the object labels, where each node (label) is represented by word embeddings of a label, and GCN is learned to map this label graph into a set of inter-dependent object classifiers. These classifiers are applied to the image descriptors extracted by another sub-net, enabling the whole network to be end-to-end trainable. Furthermore, we propose a novel re-weighted scheme to create an effective label correlation matrix to guide information propagation among the nodes in GCN. Experiments on two multi-label image recognition datasets show that our approach obviously outperforms other existing state-of-the-art methods. In addition, visualization analyses reveal that the classifiers learned by our model maintain meaningful semantic topology.