 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual 3D H&E Staining from Phase-contrast Back-illumination Interference Tomography
May 21, 2026Three-dimensional (3D) histopathology of unprocessed tissues has the potential to transform disease management by enabling volumetric characterization of tissue microarchitecture and in-vivo assessment. Back-illumination Interference Tomography (BIT) is a new phase microscopy technology that provides rapid, non-destructive volumetric imaging of unprocessed tissues. However, translating BIT volumes into clinically interpretable H&E images remains challenging, particularly due to shift-variant contrast and the absence of quantitative validation benchmarks. We introduce HistoBIT3D, the first voxel-wise paired BIT and fluorescence-labeled nuclei dataset, enabling quantitative evaluation of structural preservation in unsupervised virtual staining against ground-truth nuclear distributions. Using this dataset, we present a novel virtual staining framework that translates BIT volumes with shift-variant contrast into realistic H&E volumes by leveraging bidirectional multiscale content consistency and cross-domain style reuse to enhance structural fidelity and perceptual realism. Our method achieves state-of-the-art realism metrics while significantly improving 3D nuclei segmentation accuracy and boundary preservation under zero-shot Cellpose evaluation. Together, these contributions establish a quantitatively validated, structurally faithful, and scalable pipeline for 3D virtual H&E staining, advancing the paradigm of slide-free, volumetric computational histopathology. Our data and code are available at: https://github.com/aasong113/HistoBIT3D_VirtualStaining.
Discriminability-Transferability Trade-Off: An Information-Theoretic Perspective
Mar 08, 2022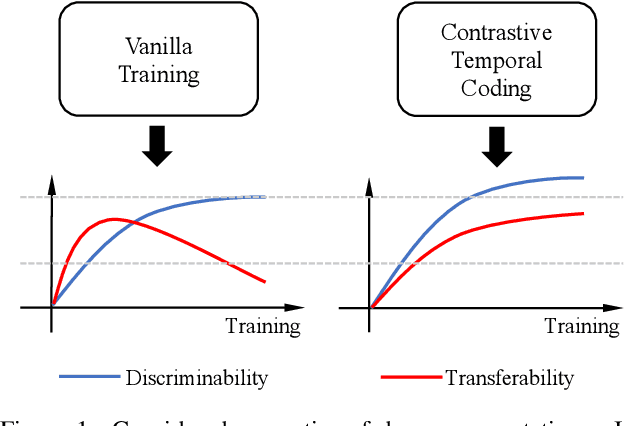

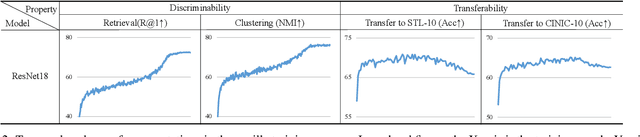

This work simultaneously considers the discriminability and transferability properties of deep representations in the typical supervised learning task, i.e., image classification. By a comprehensive temporal analysis, we observe a trade-off between these two properties. The discriminability keeps increasing with the training progressing while the transferability intensely diminishes in the later training period. From the perspective of information-bottleneck theory, we reveal that the incompatibility between discriminability and transferability is attributed to the over-compression of input information. More importantly, we investigate why and how the InfoNCE loss can alleviate the over-compression, and further present a learning framework, named contrastive temporal coding~(CTC), to counteract the over-compression and alleviate the incompatibility. Extensive experiments validate that CTC successfully mitigates the incompatibility, yielding discriminative and transferable representations. Noticeable improvements are achieved on the image classification task and challenging transfer learning tasks. We hope that this work will raise the significance of the transferability property in the conventional supervised learning setting. Code will be publicly available.
ZeroVL: A Strong Baseline for Aligning Vision-Language Representations with Limited Resources
Jan 18, 2022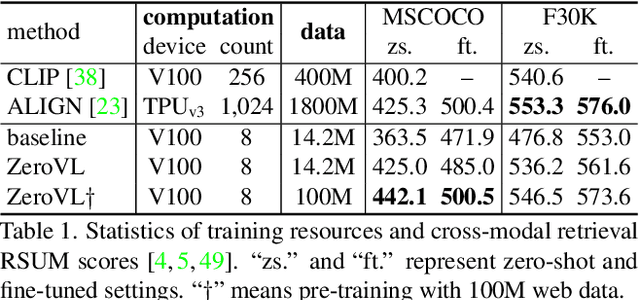
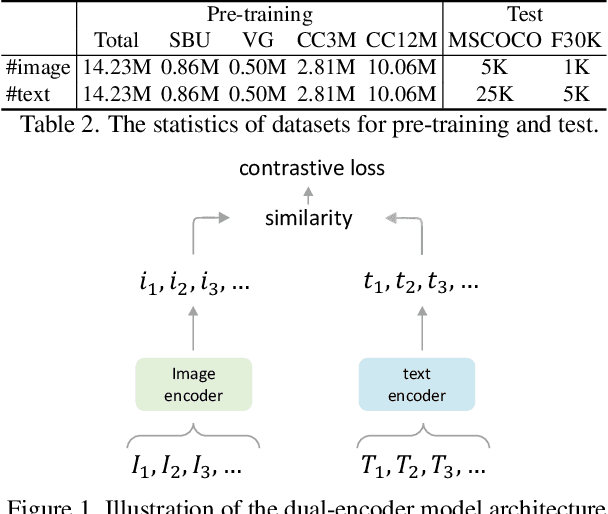
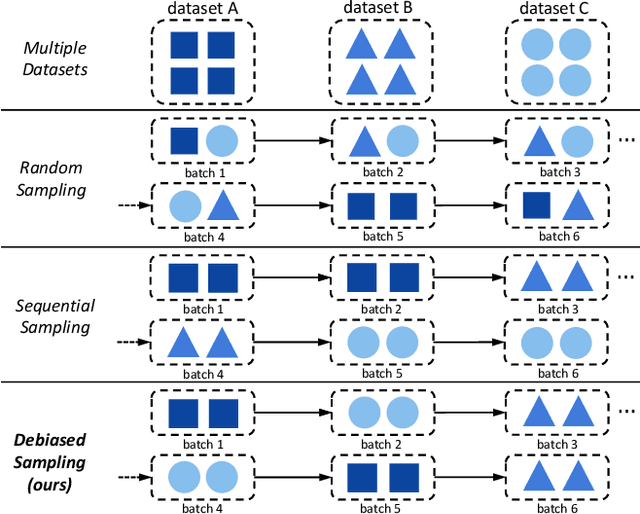
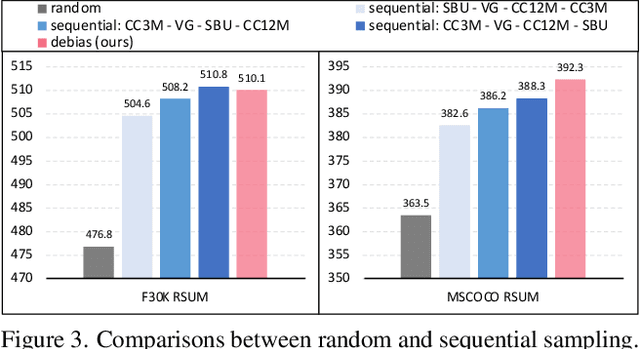
Pioneering dual-encoder pre-training works (e.g., CLIP and ALIGN) have revealed the potential of aligning multi-modal representations with contrastive learning. However, these works require a tremendous amount of data and computational resources (e.g., billion-level web data and hundreds of GPUs), which prevent researchers with limited resources from reproduction and further exploration. To this end, we explore a stack of simple but effective heuristics, and provide a comprehensive training guidance, which allows us to conduct dual-encoder multi-modal representation alignment with limited resources. We provide a reproducible strong baseline of competitive results, namely ZeroVL, with only 14M publicly accessible academic datasets and 8 V100 GPUs. Additionally, we collect 100M web data for pre-training, and achieve comparable or superior results than state-of-the-art methods, further proving the effectiveness of our method on large-scale data. We hope that this work will provide useful data points and experience for future research in multi-modal pre-training. Our code is available at https://github.com/zerovl/ZeroVL.
BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition
Dec 13, 2019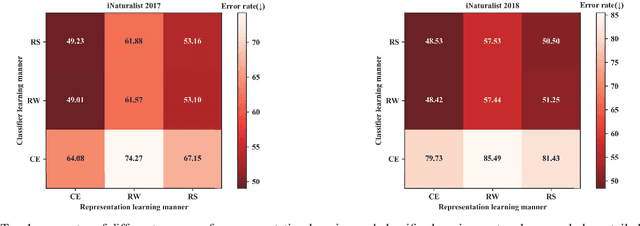

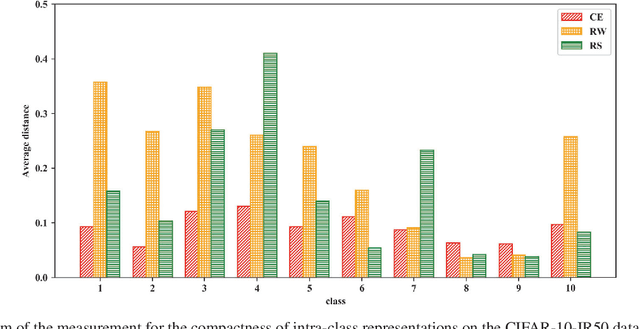
Our work focuses on tackling the challenging but natural visual recognition task of long-tailed data distribution (i.e., a few classes occupy most of the data, while most classes have rarely few samples). In the literature, class re-balancing strategies (e.g., re-weighting and re-sampling) are the prominent and effective methods proposed to alleviate the extreme imbalance for dealing with long-tailed problems. In this paper, we firstly discover that these re-balancing methods achieving satisfactory recognition accuracy owes to that they could significantly promote the classifier learning of deep networks. However, at the same time, they will unexpectedly damage the representative ability of the learned deep features to some extent. Therefore, we propose a unified Bilateral-Branch Network (BBN) to take care of both representation learning and classifier learning simultaneously, where each branch does perform its own duty separately. In particular, our BBN model is further equipped with a novel cumulative learning strategy, which is designed to first learn the universal patterns and then pay attention to the tail data gradually. Extensive experiments on four benchmark datasets, including the large-scale iNaturalist ones, justify that the proposed BBN can significantly outperform state-of-the-art methods. Furthermore, validation experiments can demonstrate both our preliminary discovery and effectiveness of tailored designs in BBN for long-tailed problems. Our method won the first place in the iNaturalist 2019 large scale species classification competition, and our code is open-source and available at https://github.com/Megvii-Nanjing/BBN.
WIDER Face and Pedestrian Challenge 2018: Methods and Results
Feb 19, 2019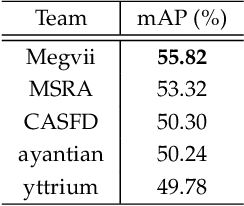

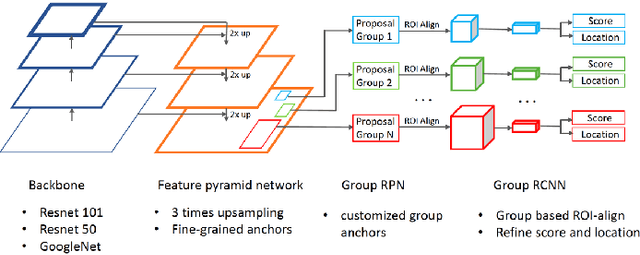
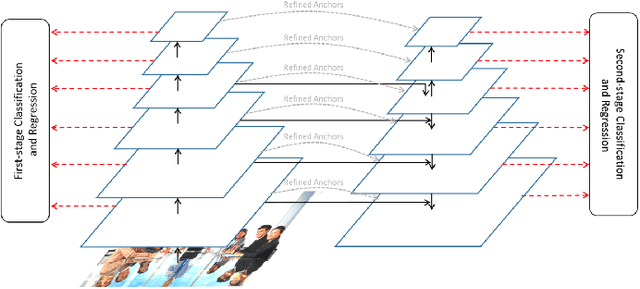
This paper presents a review of the 2018 WIDER Challenge on Face and Pedestrian. The challenge focuses on the problem of precise localization of human faces and bodies, and accurate association of identities. It comprises of three tracks: (i) WIDER Face which aims at soliciting new approaches to advance the state-of-the-art in face detection, (ii) WIDER Pedestrian which aims to find effective and efficient approaches to address the problem of pedestrian detection in unconstrained environments, and (iii) WIDER Person Search which presents an exciting challenge of searching persons across 192 movies. In total, 73 teams made valid submissions to the challenge tracks. We summarize the winning solutions for all three tracks. and present discussions on open problems and potential research directions in these topics.