 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodePMP: Scalable Preference Model Pretraining for Large Language Model Reasoning
Oct 03, 2024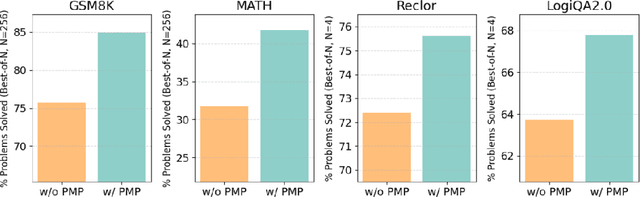
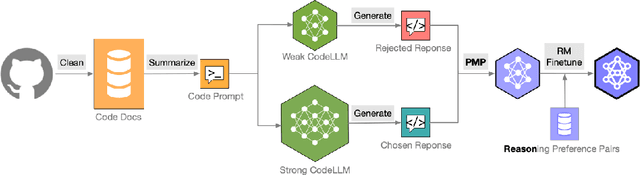

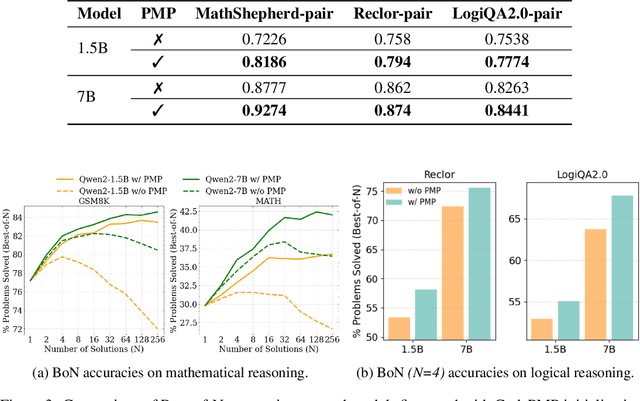
Large language models (LLMs) have made significant progress in natural language understanding and generation, driven by scalable pretraining and advanced finetuning. However, enhancing reasoning abilities in LLMs, particularly via reinforcement learning from human feedback (RLHF), remains challenging due to the scarcity of high-quality preference data, which is labor-intensive to annotate and crucial for reward model (RM) finetuning. To alleviate this issue, we introduce CodePMP, a scalable preference model pretraining (PMP) pipeline that utilizes a large corpus of synthesized code-preference pairs from publicly available high-quality source code. CodePMP improves RM finetuning efficiency by pretraining preference models on large-scale synthesized code-preference pairs. We evaluate CodePMP on mathematical reasoning tasks (GSM8K, MATH) and logical reasoning tasks (ReClor, LogiQA2.0), consistently showing significant improvements in reasoning performance of LLMs and highlighting the importance of scalable preference model pretraining for efficient reward modeling.
ZeroVL: A Strong Baseline for Aligning Vision-Language Representations with Limited Resources
Jan 18, 2022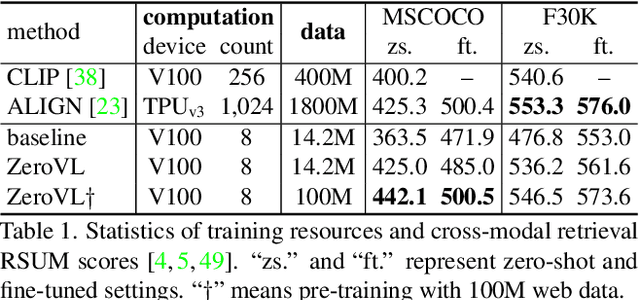
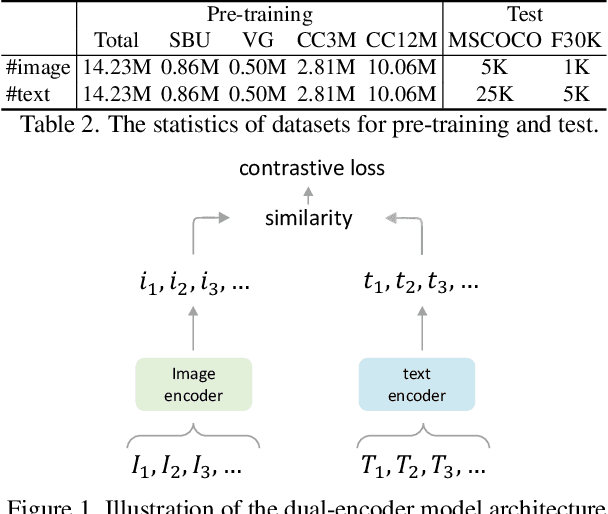
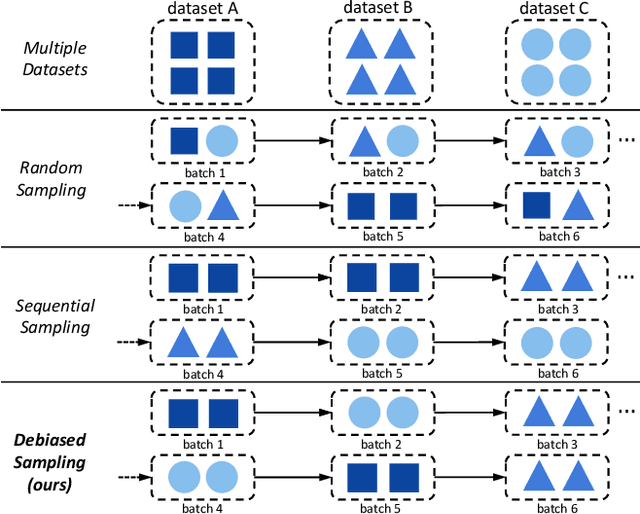
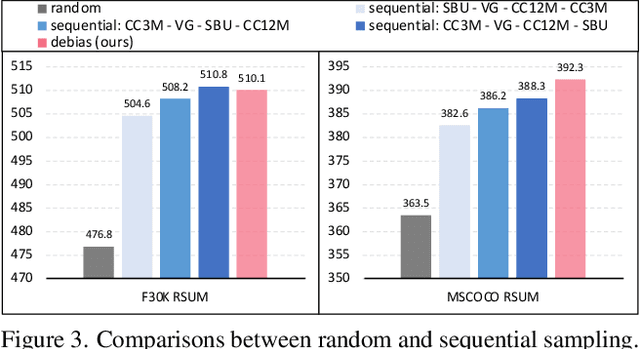
Pioneering dual-encoder pre-training works (e.g., CLIP and ALIGN) have revealed the potential of aligning multi-modal representations with contrastive learning. However, these works require a tremendous amount of data and computational resources (e.g., billion-level web data and hundreds of GPUs), which prevent researchers with limited resources from reproduction and further exploration. To this end, we explore a stack of simple but effective heuristics, and provide a comprehensive training guidance, which allows us to conduct dual-encoder multi-modal representation alignment with limited resources. We provide a reproducible strong baseline of competitive results, namely ZeroVL, with only 14M publicly accessible academic datasets and 8 V100 GPUs. Additionally, we collect 100M web data for pre-training, and achieve comparable or superior results than state-of-the-art methods, further proving the effectiveness of our method on large-scale data. We hope that this work will provide useful data points and experience for future research in multi-modal pre-training. Our code is available at https://github.com/zerovl/ZeroVL.
Person-in-Context Synthesiswith Compositional Structural Space
Aug 28, 2020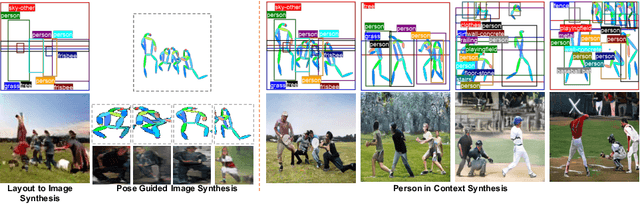
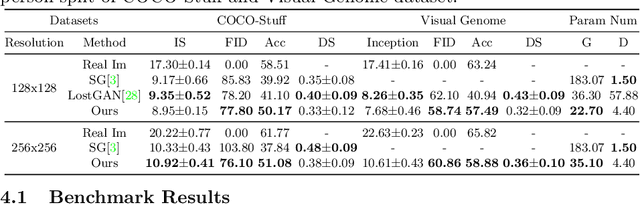
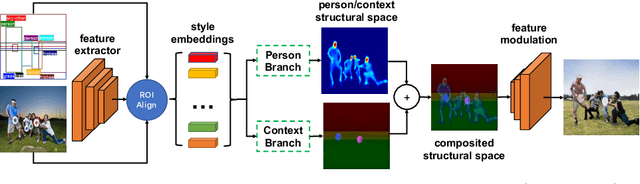

Despite significant progress, controlled generation of complex images with interacting people remains difficult. Existing layout generation methods fall short of synthesizing realistic person instances; while pose-guided generation approaches focus on a single person and assume simple or known backgrounds. To tackle these limitations, we propose a new problem, \textbf{Persons in Context Synthesis}, which aims to synthesize diverse person instance(s) in consistent contexts, with user control over both. The context is specified by the bounding box object layout which lacks shape information, while pose of the person(s) by keypoints which are sparsely annotated. To handle the stark difference in input structures, we proposed two separate neural branches to attentively composite the respective (context/person) inputs into shared ``compositional structural space'', which encodes shape, location and appearance information for both context and person structures in a disentangled manner. This structural space is then decoded to the image space using multi-level feature modulation strategy, and learned in a self supervised manner from image collections and their corresponding inputs. Extensive experiments on two large-scale datasets (COCO-Stuff \cite{caesar2018cvpr} and Visual Genome \cite{krishna2017visual}) demonstrate that our framework outperforms state-of-the-art methods w.r.t. synthesis quality.
Instance-level Facial Attributes Transfer with Geometry-Aware Flow
Nov 30, 2018
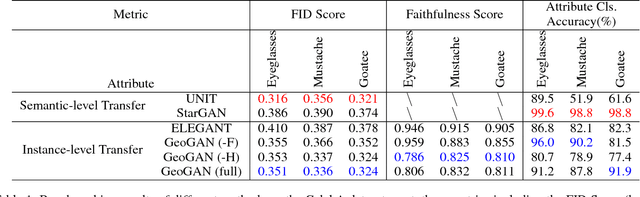
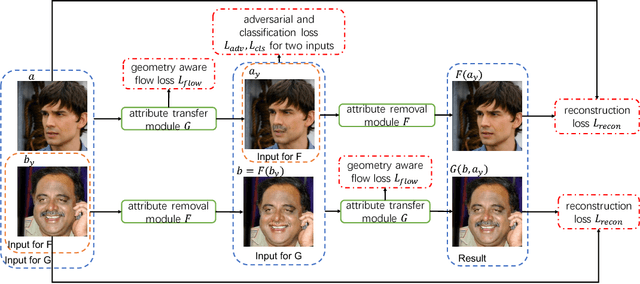
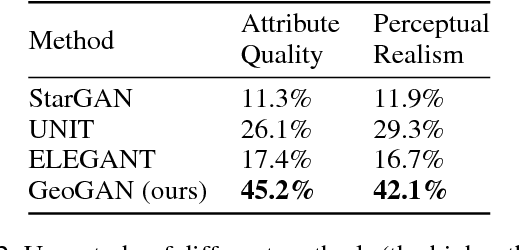
We address the problem of instance-level facial attribute transfer without paired training data, e.g. faithfully transferring the exact mustache from a source face to a target face. This is a more challenging task than the conventional semantic-level attribute transfer, which only preserves the generic attribute style instead of instance-level traits. We propose the use of geometry-aware flow, which serves as a well-suited representation for modeling the transformation between instance-level facial attributes. Specifically, we leverage the facial landmarks as the geometric guidance to learn the differentiable flows automatically, despite of the large pose gap existed. Geometry-aware flow is able to warp the source face attribute into the target face context and generate a warp-and-blend result. To compensate for the potential appearance gap between source and target faces, we propose a hallucination sub-network that produces an appearance residual to further refine the warp-and-blend result. Finally, a cycle-consistency framework consisting of both attribute transfer module and attribute removal module is designed, so that abundant unpaired face images can be used as training data. Extensive evaluations validate the capability of our approach in transferring instance-level facial attributes faithfully across large pose and appearance gaps. Thanks to the flow representation, our approach can readily be applied to generate realistic details on high-resolution images.
Image Generation from Layout
Nov 29, 2018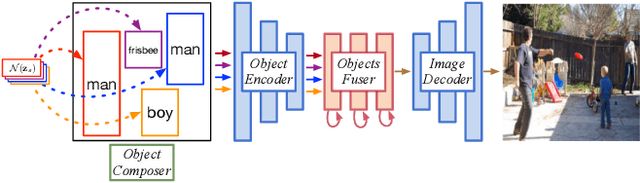
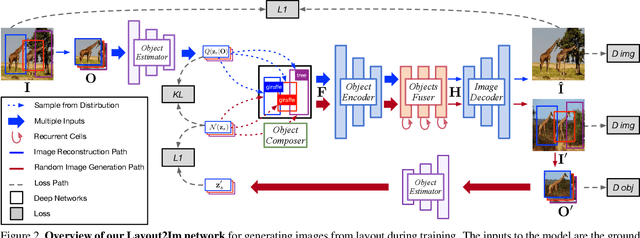

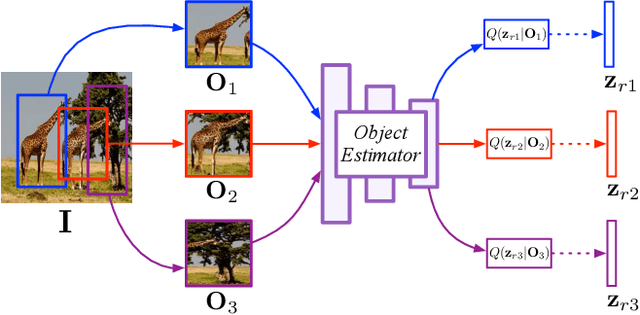
Despite significant recent progress on generative models, controlled generation of images depicting multiple and complex object layouts is still a difficult problem. Among the core challenges are the diversity of appearance a given object may possess and, as a result, exponential set of images consistent with a specified layout. To address these challenges, we propose a novel approach for layout-based image generation; we call it Layout2Im. Given the coarse spatial layout (bounding boxes + object categories), our model can generate a set of realistic images which have the correct objects in the desired locations. The representation of each object is disentangled into a specified/certain part (category) and an unspecified/uncertain part (appearance). The category is encoded using a word embedding and the appearance is distilled into a low-dimensional vector sampled from a normal distribution. Individual object representations are composed together using convolutional LSTM, to obtain an encoding of the complete layout, and then decoded to an image. Several loss terms are introduced to encourage accurate and diverse generation. The proposed Layout2Im model significantly outperforms the previous state of the art, boosting the best reported inception score by 24.66% and 28.57% on the very challenging COCO-Stuff and Visual Genome datasets, respectively. Extensive experiments also demonstrate our method's ability to generate complex and diverse images with multiple objects.
Semi-Latent GAN: Learning to generate and modify facial images from attributes
Apr 07, 2017
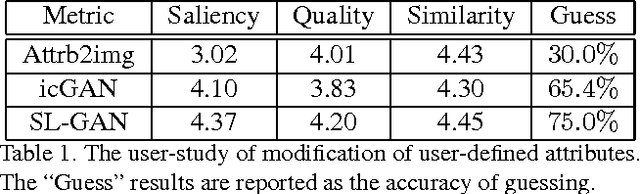
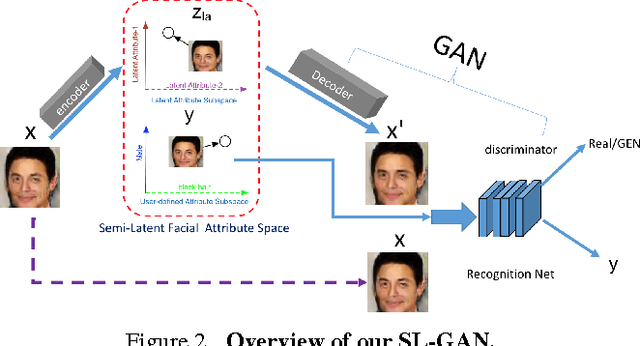
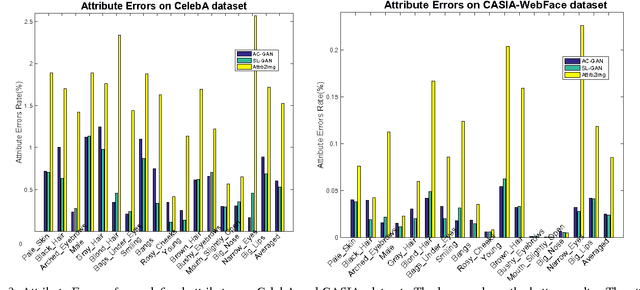
Generating and manipulating human facial images using high-level attributal controls are important and interesting problems. The models proposed in previous work can solve one of these two problems (generation or manipulation), but not both coherently. This paper proposes a novel model that learns how to both generate and modify the facial image from high-level semantic attributes. Our key idea is to formulate a Semi-Latent Facial Attribute Space (SL-FAS) to systematically learn relationship between user-defined and latent attributes, as well as between those attributes and RGB imagery. As part of this newly formulated space, we propose a new model --- SL-GAN which is a specific form of Generative Adversarial Network. Finally, we present an iterative training algorithm for SL-GAN. The experiments on recent CelebA and CASIA-WebFace datasets validate the effectiveness of our proposed framework. We will also make data, pre-trained models and code available.