 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerson-in-Context Synthesiswith Compositional Structural Space
Paper and Code
Aug 28, 2020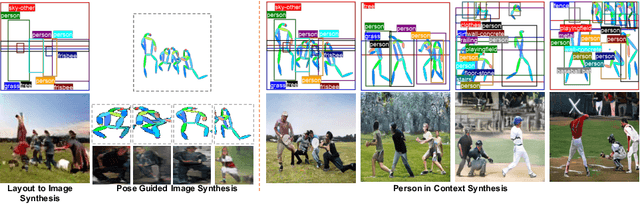
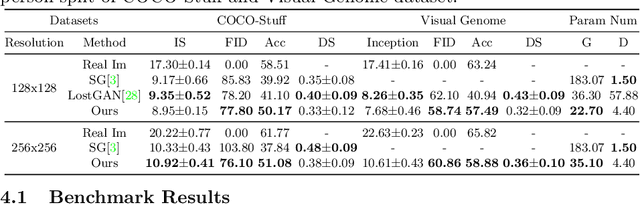
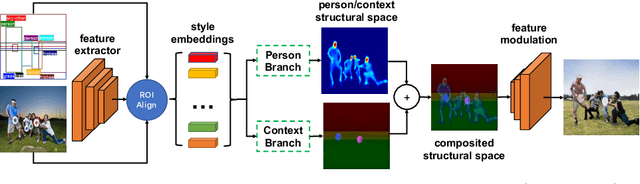

Despite significant progress, controlled generation of complex images with interacting people remains difficult. Existing layout generation methods fall short of synthesizing realistic person instances; while pose-guided generation approaches focus on a single person and assume simple or known backgrounds. To tackle these limitations, we propose a new problem, \textbf{Persons in Context Synthesis}, which aims to synthesize diverse person instance(s) in consistent contexts, with user control over both. The context is specified by the bounding box object layout which lacks shape information, while pose of the person(s) by keypoints which are sparsely annotated. To handle the stark difference in input structures, we proposed two separate neural branches to attentively composite the respective (context/person) inputs into shared ``compositional structural space'', which encodes shape, location and appearance information for both context and person structures in a disentangled manner. This structural space is then decoded to the image space using multi-level feature modulation strategy, and learned in a self supervised manner from image collections and their corresponding inputs. Extensive experiments on two large-scale datasets (COCO-Stuff \cite{caesar2018cvpr} and Visual Genome \cite{krishna2017visual}) demonstrate that our framework outperforms state-of-the-art methods w.r.t. synthesis quality.