 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupled Knowledge Distillation
Paper and Code
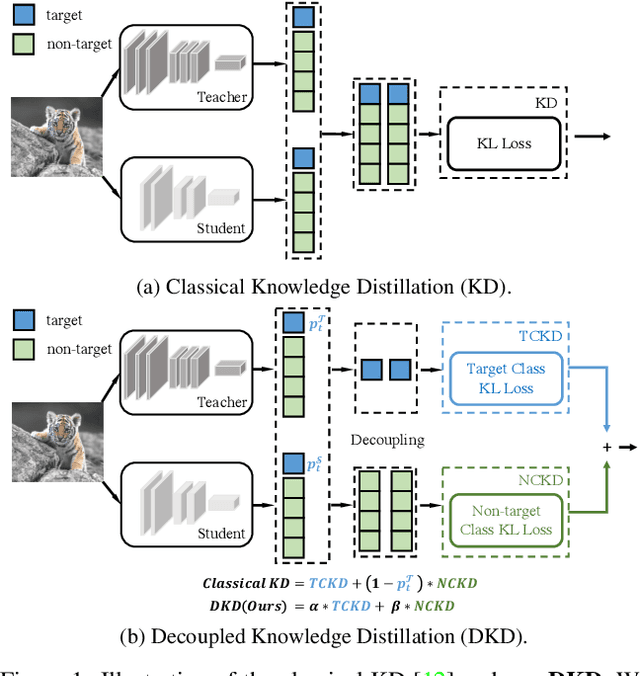
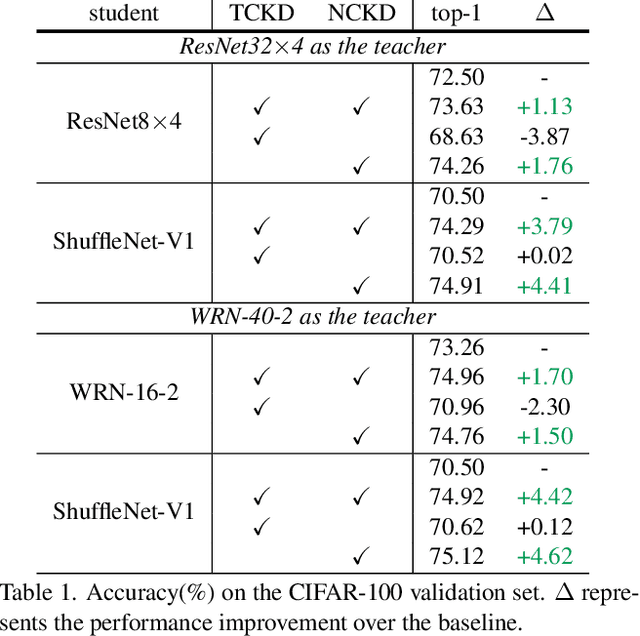
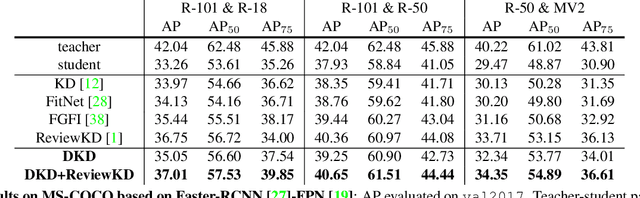
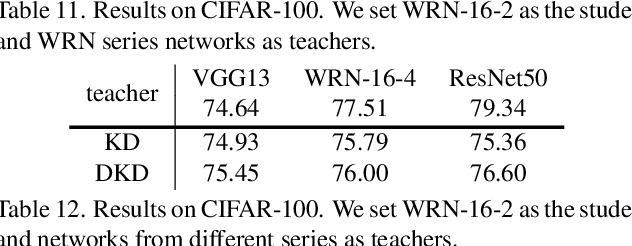
State-of-the-art distillation methods are mainly based on distilling deep features from intermediate layers, while the significance of logit distillation is greatly overlooked. To provide a novel viewpoint to study logit distillation, we reformulate the classical KD loss into two parts, i.e., target class knowledge distillation (TCKD) and non-target class knowledge distillation (NCKD). We empirically investigate and prove the effects of the two parts: TCKD transfers knowledge concerning the "difficulty" of training samples, while NCKD is the prominent reason why logit distillation works. More importantly, we reveal that the classical KD loss is a coupled formulation, which (1) suppresses the effectiveness of NCKD and (2) limits the flexibility to balance these two parts. To address these issues, we present Decoupled Knowledge Distillation (DKD), enabling TCKD and NCKD to play their roles more efficiently and flexibly. Compared with complex feature-based methods, our DKD achieves comparable or even better results and has better training efficiency on CIFAR-100, ImageNet, and MS-COCO datasets for image classification and object detection tasks. This paper proves the great potential of logit distillation, and we hope it will be helpful for future research. The code is available at https://github.com/megvii-research/mdistiller.