 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient One Pass Self-distillation with Zipf's Label Smoothing
Paper and Code
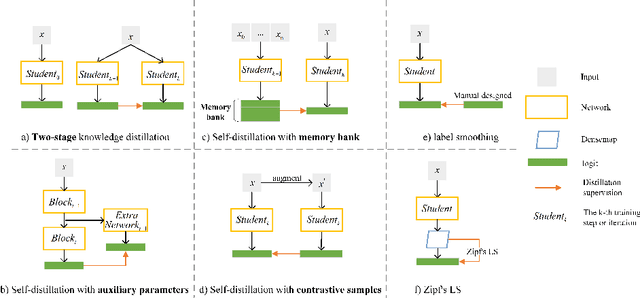
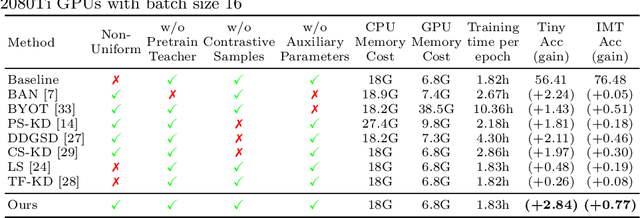
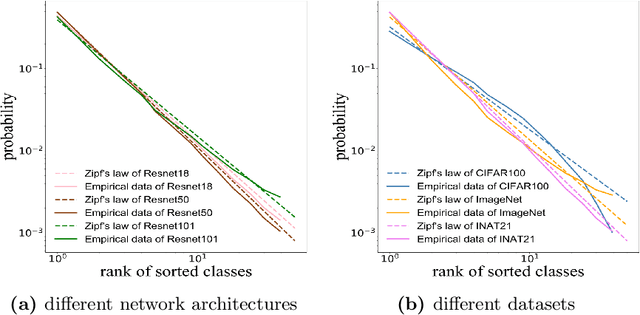
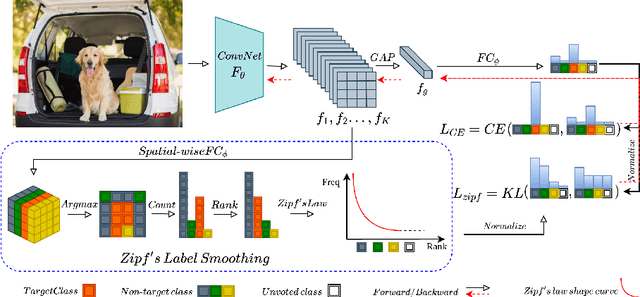
Self-distillation exploits non-uniform soft supervision from itself during training and improves performance without any runtime cost. However, the overhead during training is often overlooked, and yet reducing time and memory overhead during training is increasingly important in the giant models' era. This paper proposes an efficient self-distillation method named Zipf's Label Smoothing (Zipf's LS), which uses the on-the-fly prediction of a network to generate soft supervision that conforms to Zipf distribution without using any contrastive samples or auxiliary parameters. Our idea comes from an empirical observation that when the network is duly trained the output values of a network's final softmax layer, after sorting by the magnitude and averaged across samples, should follow a distribution reminiscent to Zipf's Law in the word frequency statistics of natural languages. By enforcing this property on the sample level and throughout the whole training period, we find that the prediction accuracy can be greatly improved. Using ResNet50 on the INAT21 fine-grained classification dataset, our technique achieves +3.61% accuracy gain compared to the vanilla baseline, and 0.88% more gain against the previous label smoothing or self-distillation strategies. The implementation is publicly available at https://github.com/megvii-research/zipfls.