 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic MLP for Fine-Grained Image Classification by Leveraging Geographical and Temporal Information
Mar 07, 2022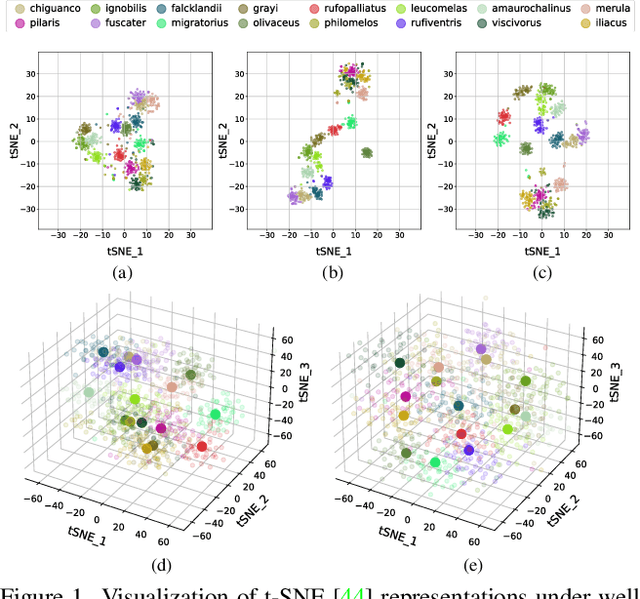
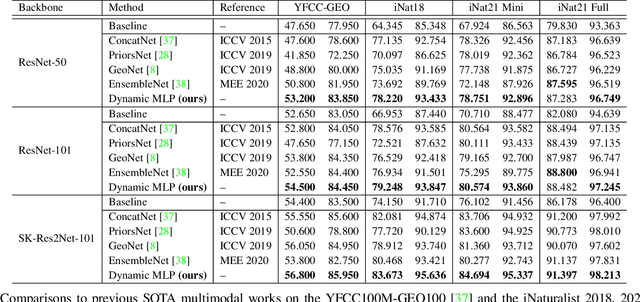
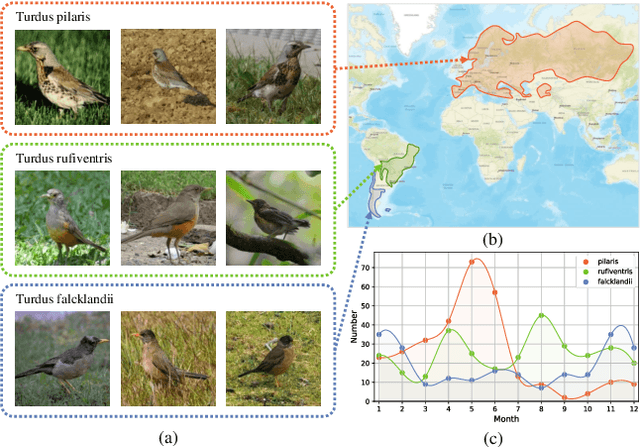
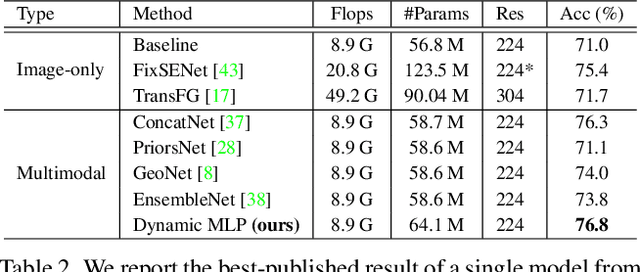
Fine-grained image classification is a challenging computer vision task where various species share similar visual appearances, resulting in misclassification if merely based on visual clues. Therefore, it is helpful to leverage additional information, e.g., the locations and dates for data shooting, which can be easily accessible but rarely exploited. In this paper, we first demonstrate that existing multimodal methods fuse multiple features only on a single dimension, which essentially has insufficient help in feature discrimination. To fully explore the potential of multimodal information, we propose a dynamic MLP on top of the image representation, which interacts with multimodal features at a higher and broader dimension. The dynamic MLP is an efficient structure parameterized by the learned embeddings of variable locations and dates. It can be regarded as an adaptive nonlinear projection for generating more discriminative image representations in visual tasks. To our best knowledge, it is the first attempt to explore the idea of dynamic networks to exploit multimodal information in fine-grained image classification tasks. Extensive experiments demonstrate the effectiveness of our method. The t-SNE algorithm visually indicates that our technique improves the recognizability of image representations that are visually similar but with different categories. Furthermore, among published works across multiple fine-grained datasets, dynamic MLP consistently achieves SOTA results https://paperswithcode.com/dataset/inaturalist and takes third place in the iNaturalist challenge at FGVC8 https://www.kaggle.com/c/inaturalist-2021/leaderboard. Code is available at https://github.com/ylingfeng/DynamicMLP.git