 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Absolute to Relative: Rethinking Reward Shaping in Group-Based Reinforcement Learning
Jan 30, 2026Reinforcement learning has become a cornerstone for enhancing the reasoning capabilities of Large Language Models, where group-based approaches such as GRPO have emerged as efficient paradigms that optimize policies by leveraging intra-group performance differences. However, these methods typically rely on absolute numerical rewards, introducing intrinsic limitations. In verifiable tasks, identical group evaluations often result in sparse supervision, while in open-ended scenarios, the score range instability of reward models undermines advantage estimation based on group means. To address these limitations, we propose Reinforcement Learning with Relative Rewards (RLRR), a framework that shifts reward shaping from absolute scoring to relative ranking. Complementing this framework, we introduce the Ranking Reward Model, a listwise preference model tailored for group-based optimization to directly generate relative rankings. By transforming raw evaluations into robust relative signals, RLRR effectively mitigates signal sparsity and reward instability. Experimental results demonstrate that RLRR yields consistent performance improvements over standard group-based baselines across reasoning benchmarks and open-ended generation tasks.
Asymmetric Decision-Making in Online Knowledge Distillation:Unifying Consensus and Divergence
Mar 09, 2025
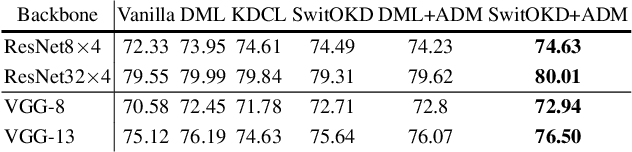
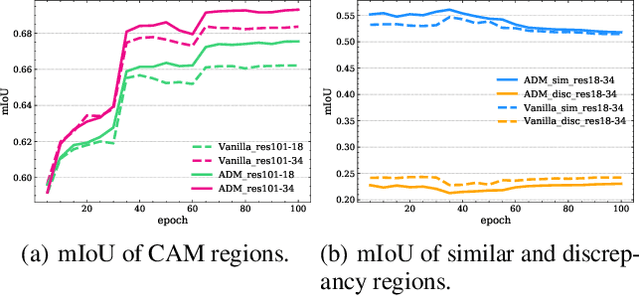
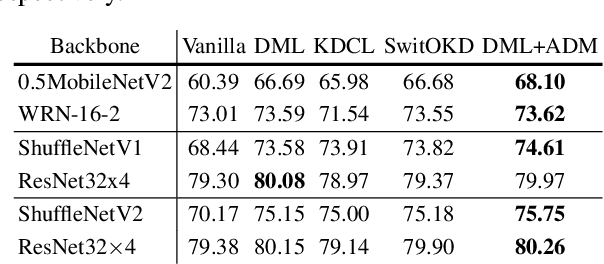
Online Knowledge Distillation (OKD) methods streamline the distillation training process into a single stage, eliminating the need for knowledge transfer from a pretrained teacher network to a more compact student network. This paper presents an innovative approach to leverage intermediate spatial representations. Our analysis of the intermediate features from both teacher and student models reveals two pivotal insights: (1) the similar features between students and teachers are predominantly focused on foreground objects. (2) teacher models emphasize foreground objects more than students. Building on these findings, we propose Asymmetric Decision-Making (ADM) to enhance feature consensus learning for student models while continuously promoting feature diversity in teacher models. Specifically, Consensus Learning for student models prioritizes spatial features with high consensus relative to teacher models. Conversely, Divergence Learning for teacher models highlights spatial features with lower similarity compared to student models, indicating superior performance by teacher models in these regions. Consequently, ADM facilitates the student models to catch up with the feature learning process of the teacher models. Extensive experiments demonstrate that ADM consistently surpasses existing OKD methods across various online knowledge distillation settings and also achieves superior results when applied to offline knowledge distillation, semantic segmentation and diffusion distillation tasks.
Bid Optimization using Maximum Entropy Reinforcement Learning
Oct 11, 2021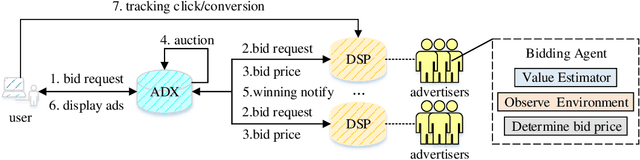

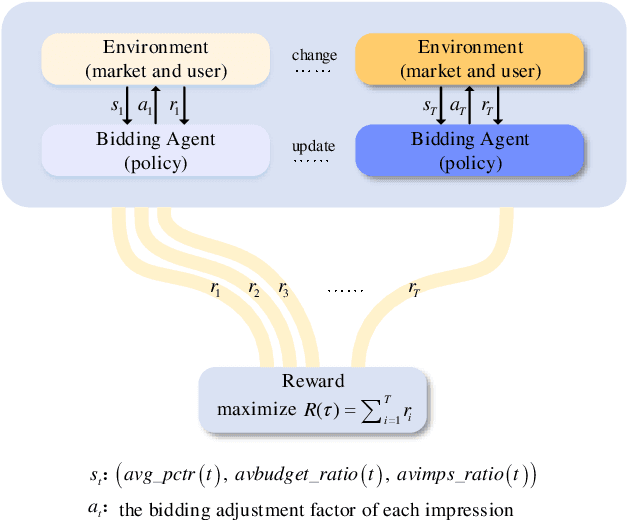
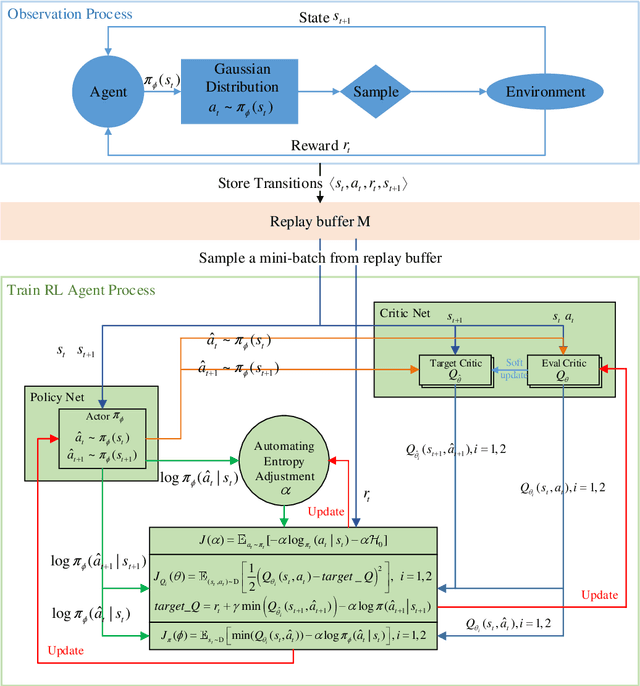
Real-time bidding (RTB) has become a critical way of online advertising. In RTB, an advertiser can participate in bidding ad impressions to display its advertisements. The advertiser determines every impression's bidding price according to its bidding strategy. Therefore, a good bidding strategy can help advertisers improve cost efficiency. This paper focuses on optimizing a single advertiser's bidding strategy using reinforcement learning (RL) in RTB. Unfortunately, it is challenging to optimize the bidding strategy through RL at the granularity of impression due to the highly dynamic nature of the RTB environment. In this paper, we first utilize a widely accepted linear bidding function to compute every impression's base price and optimize it by a mutable adjustment factor derived from the RTB auction environment, to avoid optimizing every impression's bidding price directly. Specifically, we use the maximum entropy RL algorithm (Soft Actor-Critic) to optimize the adjustment factor generation policy at the impression-grained level. Finally, the empirical study on a public dataset demonstrates that the proposed bidding strategy has superior performance compared with the baselines.
Orderly Dual-Teacher Knowledge Distillation for Lightweight Human Pose Estimation
Apr 21, 2021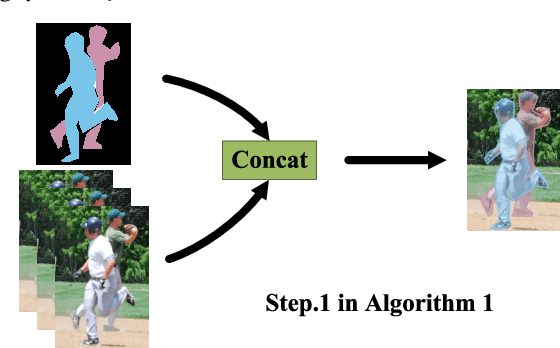

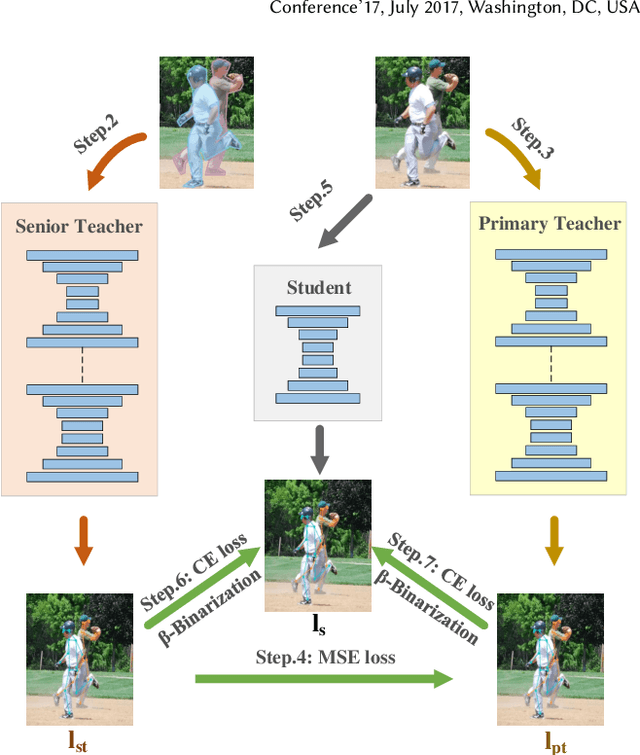
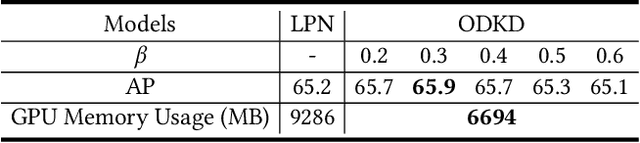
Although deep convolution neural networks (DCNN) have achieved excellent performance in human pose estimation, these networks often have a large number of parameters and computations, leading to the slow inference speed. For this issue, an effective solution is knowledge distillation, which transfers knowledge from a large pre-trained network (teacher) to a small network (student). However, there are some defects in the existing approaches: (I) Only a single teacher is adopted, neglecting the potential that a student can learn from multiple teachers. (II) The human segmentation mask can be regarded as additional prior information to restrict the location of keypoints, which is never utilized. (III) A student with a small number of parameters cannot fully imitate heatmaps provided by datasets and teachers. (IV) There exists noise in heatmaps generated by teachers, which causes model degradation. To overcome these defects, we propose an orderly dual-teacher knowledge distillation (ODKD) framework, which consists of two teachers with different capabilities. Specifically, the weaker one (primary teacher, PT) is used to teach keypoints information, the stronger one (senior teacher, ST) is utilized to transfer segmentation and keypoints information by adding the human segmentation mask. Taking dual-teacher together, an orderly learning strategy is proposed to promote knowledge absorbability. Moreover, we employ a binarization operation which further improves the learning ability of the student and reduces noise in heatmaps. Experimental results on COCO and OCHuman keypoints datasets show that our proposed ODKD can improve the performance of different lightweight models by a large margin, and HRNet-W16 equipped with ODKD achieves state-of-the-art performance for lightweight human pose estimation.