 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocus on Low-Resolution Information: Multi-Granular Information-Lossless Model for Low-Resolution Human Pose Estimation
May 19, 2024In real-world applications of human pose estimation, low-resolution input images are frequently encountered when the performance of the image acquisition equipment is limited or the shooting distance is too far. However, existing state-of-the-art models for human pose estimation perform poorly on low-resolution images. One key reason is the presence of downsampling layers in these models, e.g., strided convolutions and pooling layers. It further reduces the already insufficient image information. Another key reason is that the body skeleton and human kinematic information are not fully utilized. In this work, we propose a Multi-Granular Information-Lossless (MGIL) model to replace the downsampling layers to address the above issues. Specifically, MGIL employs a Fine-grained Lossless Information Extraction (FLIE) module, which can prevent the loss of local information. Furthermore, we design a Coarse-grained Information Interaction (CII) module to adequately leverage human body structural information. To efficiently fuse cross-granular information and thoroughly exploit the relationships among keypoints, we further introduce a Multi-Granular Adaptive Fusion (MGAF) mechanism. The mechanism assigns weights to features of different granularities based on the content of the image. The model is effective, flexible, and universal. We show its potential in various vision tasks with comprehensive experiments. It outperforms the SOTA methods by 7.7 mAP on COCO and performs well with different input resolutions, different backbones, and different vision tasks. The code is provided in supplementary material.
Cross-Domain Knowledge Distillation for Low-Resolution Human Pose Estimation
May 19, 2024



In practical applications of human pose estimation, low-resolution inputs frequently occur, and existing state-of-the-art models perform poorly with low-resolution images. This work focuses on boosting the performance of low-resolution models by distilling knowledge from a high-resolution model. However, we face the challenge of feature size mismatch and class number mismatch when applying knowledge distillation to networks with different input resolutions. To address this issue, we propose a novel cross-domain knowledge distillation (CDKD) framework. In this framework, we construct a scale-adaptive projector ensemble (SAPE) module to spatially align feature maps between models of varying input resolutions. It adopts a projector ensemble to map low-resolution features into multiple common spaces and adaptively merges them based on multi-scale information to match high-resolution features. Additionally, we construct a cross-class alignment (CCA) module to solve the problem of the mismatch of class numbers. By combining an easy-to-hard training (ETHT) strategy, the CCA module further enhances the distillation performance. The effectiveness and efficiency of our approach are demonstrated by extensive experiments on two common benchmark datasets: MPII and COCO. The code is made available in supplementary material.
Mutual Information-driven Triple Interaction Network for Efficient Image Dehazing
Aug 14, 2023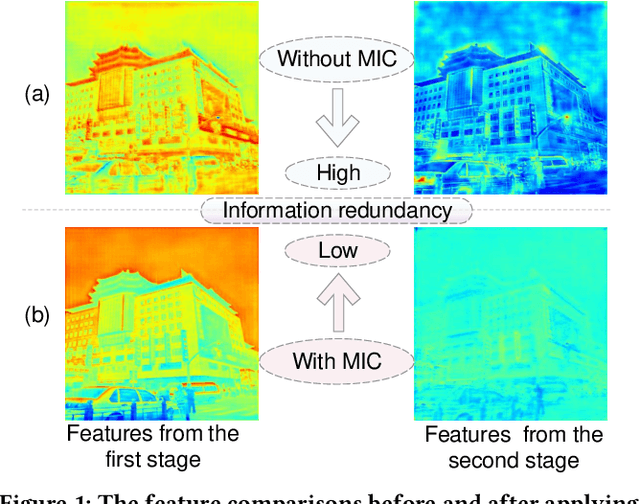
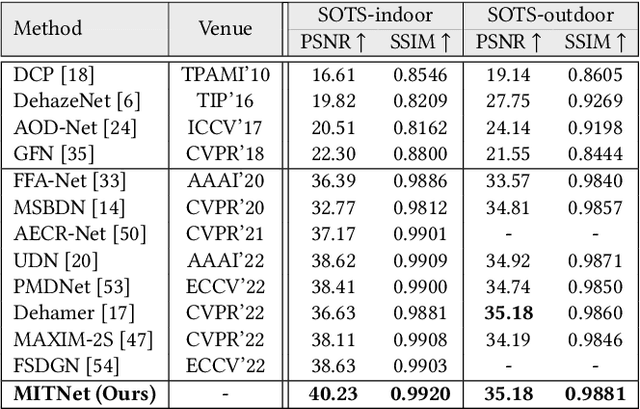
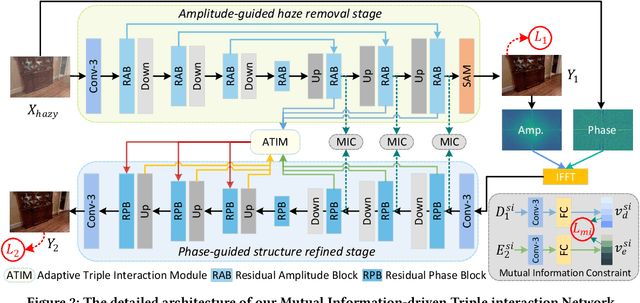
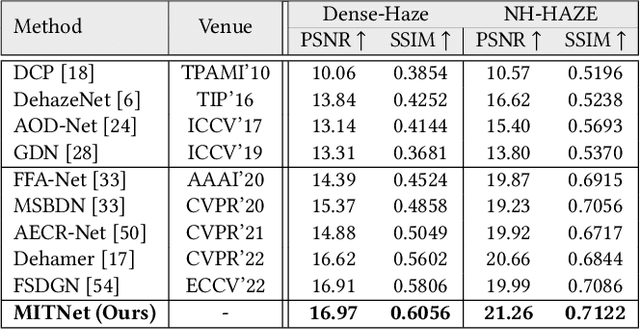
Multi-stage architectures have exhibited efficacy in image dehazing, which usually decomposes a challenging task into multiple more tractable sub-tasks and progressively estimates latent hazy-free images. Despite the remarkable progress, existing methods still suffer from the following shortcomings: (1) limited exploration of frequency domain information; (2) insufficient information interaction; (3) severe feature redundancy. To remedy these issues, we propose a novel Mutual Information-driven Triple interaction Network (MITNet) based on spatial-frequency dual domain information and two-stage architecture. To be specific, the first stage, named amplitude-guided haze removal, aims to recover the amplitude spectrum of the hazy images for haze removal. And the second stage, named phase-guided structure refined, devotes to learning the transformation and refinement of the phase spectrum. To facilitate the information exchange between two stages, an Adaptive Triple Interaction Module (ATIM) is developed to simultaneously aggregate cross-domain, cross-scale, and cross-stage features, where the fused features are further used to generate content-adaptive dynamic filters so that applying them to enhance global context representation. In addition, we impose the mutual information minimization constraint on paired scale encoder and decoder features from both stages. Such an operation can effectively reduce information redundancy and enhance cross-stage feature complementarity. Extensive experiments on multiple public datasets exhibit that our MITNet performs superior performance with lower model complexity.The code and models are available at https://github.com/it-hao/MITNet.
Adaptive Dynamic Filtering Network for Image Denoising
Nov 26, 2022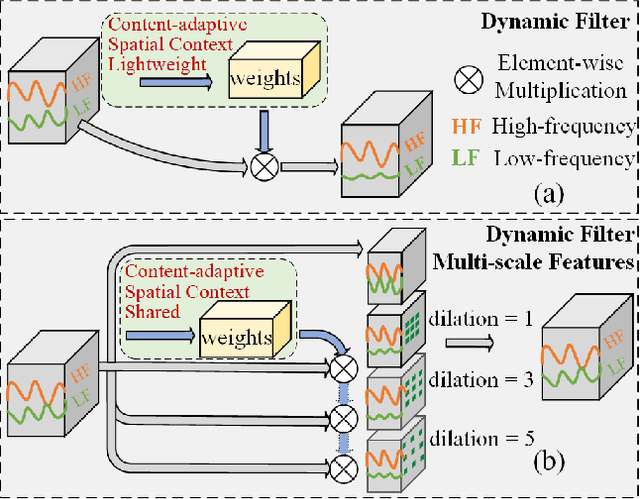

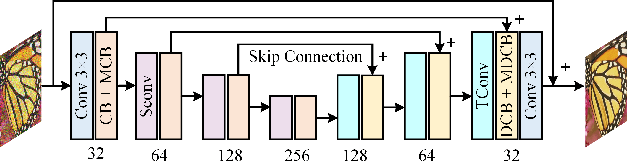
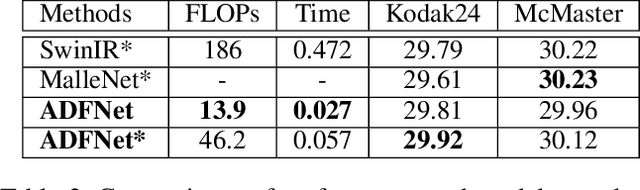
In image denoising networks, feature scaling is widely used to enlarge the receptive field size and reduce computational costs. This practice, however, also leads to the loss of high-frequency information and fails to consider within-scale characteristics. Recently, dynamic convolution has exhibited powerful capabilities in processing high-frequency information (e.g., edges, corners, textures), but previous works lack sufficient spatial contextual information in filter generation. To alleviate these issues, we propose to employ dynamic convolution to improve the learning of high-frequency and multi-scale features. Specifically, we design a spatially enhanced kernel generation (SEKG) module to improve dynamic convolution, enabling the learning of spatial context information with a very low computational complexity. Based on the SEKG module, we propose a dynamic convolution block (DCB) and a multi-scale dynamic convolution block (MDCB). The former enhances the high-frequency information via dynamic convolution and preserves low-frequency information via skip connections. The latter utilizes shared adaptive dynamic kernels and the idea of dilated convolution to achieve efficient multi-scale feature extraction. The proposed multi-dimension feature integration (MFI) mechanism further fuses the multi-scale features, providing precise and contextually enriched feature representations. Finally, we build an efficient denoising network with the proposed DCB and MDCB, named ADFNet. It achieves better performance with low computational complexity on real-world and synthetic Gaussian noisy datasets. The source code is available at https://github.com/it-hao/ADFNet.
A Light-weight, Effective and Efficient Model for Label Aggregation in Crowdsourcing
Nov 19, 2022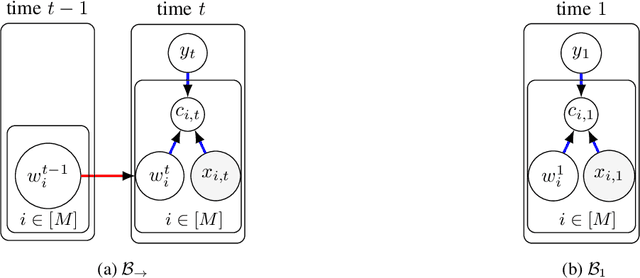
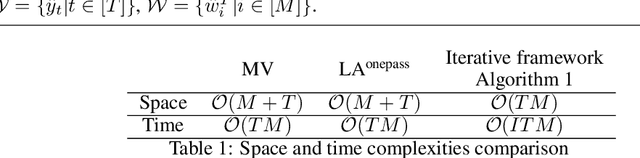
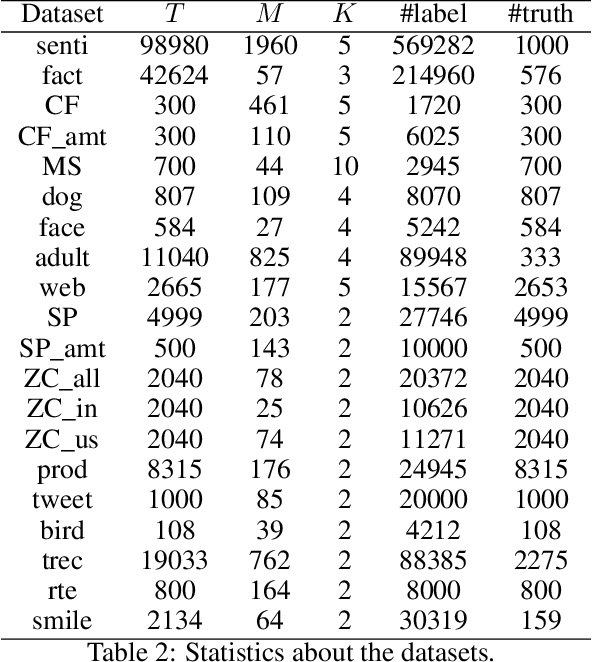
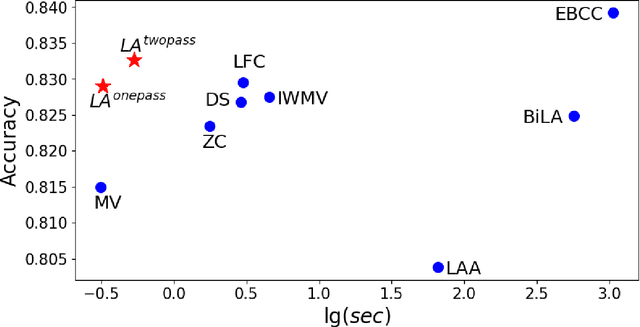
Due to the noises in crowdsourced labels, label aggregation (LA) has emerged as a standard procedure to post-process crowdsourced labels. LA methods estimate true labels from crowdsourced labels by modeling worker qualities. Most existing LA methods are iterative in nature. They need to traverse all the crowdsourced labels multiple times in order to jointly and iteratively update true labels and worker qualities until convergence. Consequently, these methods have high space and time complexities. In this paper, we treat LA as a dynamic system and model it as a Dynamic Bayesian network. From the dynamic model we derive two light-weight algorithms, LA\textsuperscript{onepass} and LA\textsuperscript{twopass}, which can effectively and efficiently estimate worker qualities and true labels by traversing all the labels at most twice. Due to the dynamic nature, the proposed algorithms can also estimate true labels online without re-visiting historical data. We theoretically prove the convergence property of the proposed algorithms, and bound the error of estimated worker qualities. We also analyze the space and time complexities of the proposed algorithms and show that they are equivalent to those of majority voting. Experiments conducted on 20 real-world datasets demonstrate that the proposed algorithms can effectively and efficiently aggregate labels in both offline and online settings even if they traverse all the labels at most twice.
Orderly Dual-Teacher Knowledge Distillation for Lightweight Human Pose Estimation
Apr 21, 2021

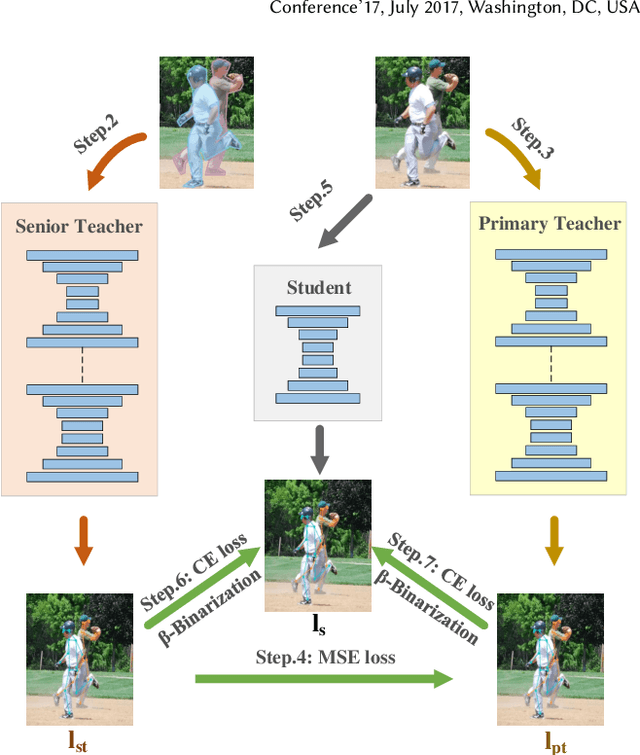
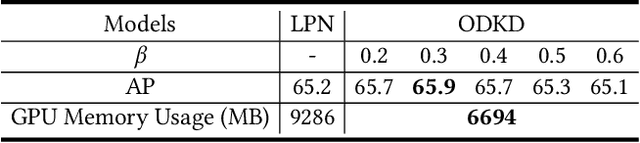
Although deep convolution neural networks (DCNN) have achieved excellent performance in human pose estimation, these networks often have a large number of parameters and computations, leading to the slow inference speed. For this issue, an effective solution is knowledge distillation, which transfers knowledge from a large pre-trained network (teacher) to a small network (student). However, there are some defects in the existing approaches: (I) Only a single teacher is adopted, neglecting the potential that a student can learn from multiple teachers. (II) The human segmentation mask can be regarded as additional prior information to restrict the location of keypoints, which is never utilized. (III) A student with a small number of parameters cannot fully imitate heatmaps provided by datasets and teachers. (IV) There exists noise in heatmaps generated by teachers, which causes model degradation. To overcome these defects, we propose an orderly dual-teacher knowledge distillation (ODKD) framework, which consists of two teachers with different capabilities. Specifically, the weaker one (primary teacher, PT) is used to teach keypoints information, the stronger one (senior teacher, ST) is utilized to transfer segmentation and keypoints information by adding the human segmentation mask. Taking dual-teacher together, an orderly learning strategy is proposed to promote knowledge absorbability. Moreover, we employ a binarization operation which further improves the learning ability of the student and reduces noise in heatmaps. Experimental results on COCO and OCHuman keypoints datasets show that our proposed ODKD can improve the performance of different lightweight models by a large margin, and HRNet-W16 equipped with ODKD achieves state-of-the-art performance for lightweight human pose estimation.
Object Detection with Deep Learning: A Review
Jul 15, 2018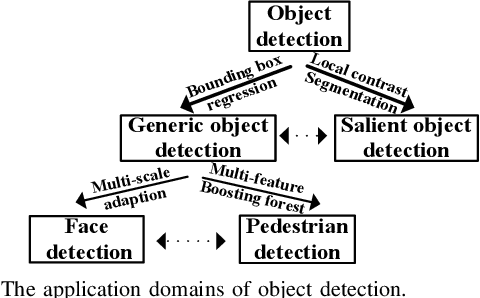

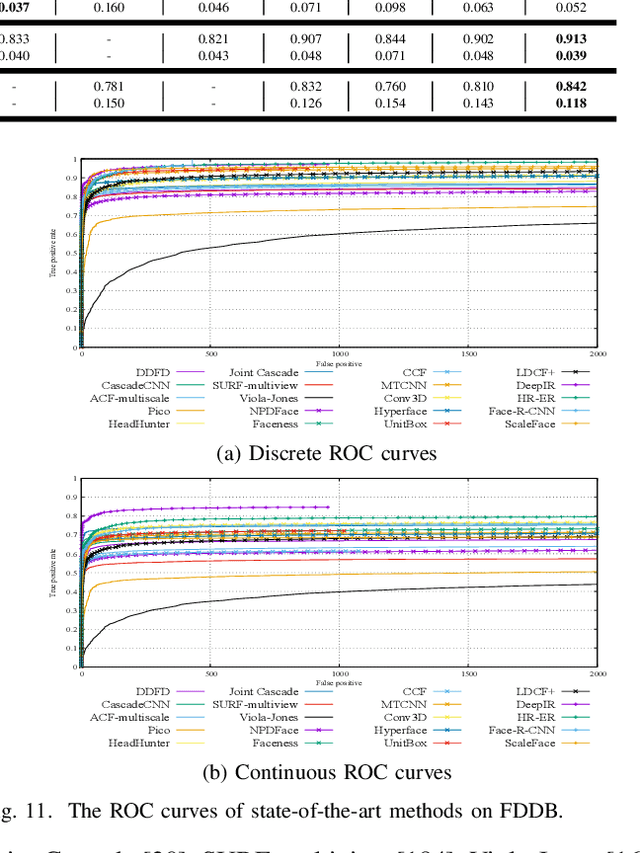

Due to object detection's close relationship with video analysis and image understanding, it has attracted much research attention in recent years. Traditional object detection methods are built on handcrafted features and shallow trainable architectures. Their performance easily stagnates by constructing complex ensembles which combine multiple low-level image features with high-level context from object detectors and scene classifiers. With the rapid development in deep learning, more powerful tools, which are able to learn semantic, high-level, deeper features, are introduced to address the problems existing in traditional architectures. These models behave differently in network architecture, training strategy and optimization function, etc. In this paper, we provide a review on deep learning based object detection frameworks. Our review begins with a brief introduction on the history of deep learning and its representative tool, namely Convolutional Neural Network (CNN). Then we focus on typical generic object detection architectures along with some modifications and useful tricks to improve detection performance further. As distinct specific detection tasks exhibit different characteristics, we also briefly survey several specific tasks, including salient object detection, face detection and pedestrian detection. Experimental analyses are also provided to compare various methods and draw some meaningful conclusions. Finally, several promising directions and tasks are provided to serve as guidelines for future work in both object detection and relevant neural network based learning systems.
Robust and Efficient Subspace Segmentation via Least Squares Regression
Apr 27, 2014
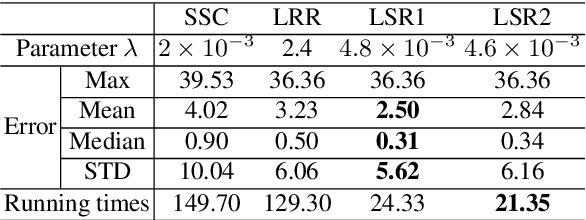
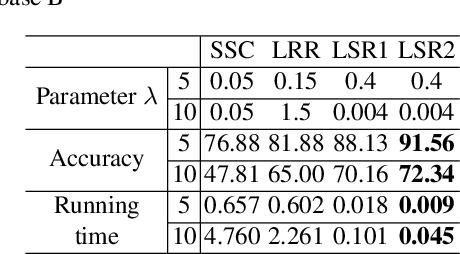
This paper studies the subspace segmentation problem which aims to segment data drawn from a union of multiple linear subspaces. Recent works by using sparse representation, low rank representation and their extensions attract much attention. If the subspaces from which the data drawn are independent or orthogonal, they are able to obtain a block diagonal affinity matrix, which usually leads to a correct segmentation. The main differences among them are their objective functions. We theoretically show that if the objective function satisfies some conditions, and the data are sufficiently drawn from independent subspaces, the obtained affinity matrix is always block diagonal. Furthermore, the data sampling can be insufficient if the subspaces are orthogonal. Some existing methods are all special cases. Then we present the Least Squares Regression (LSR) method for subspace segmentation. It takes advantage of data correlation, which is common in real data. LSR encourages a grouping effect which tends to group highly correlated data together. Experimental results on the Hopkins 155 database and Extended Yale Database B show that our method significantly outperforms state-of-the-art methods. Beyond segmentation accuracy, all experiments demonstrate that LSR is much more efficient.