 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Domain Knowledge Distillation for Low-Resolution Human Pose Estimation
May 19, 2024



In practical applications of human pose estimation, low-resolution inputs frequently occur, and existing state-of-the-art models perform poorly with low-resolution images. This work focuses on boosting the performance of low-resolution models by distilling knowledge from a high-resolution model. However, we face the challenge of feature size mismatch and class number mismatch when applying knowledge distillation to networks with different input resolutions. To address this issue, we propose a novel cross-domain knowledge distillation (CDKD) framework. In this framework, we construct a scale-adaptive projector ensemble (SAPE) module to spatially align feature maps between models of varying input resolutions. It adopts a projector ensemble to map low-resolution features into multiple common spaces and adaptively merges them based on multi-scale information to match high-resolution features. Additionally, we construct a cross-class alignment (CCA) module to solve the problem of the mismatch of class numbers. By combining an easy-to-hard training (ETHT) strategy, the CCA module further enhances the distillation performance. The effectiveness and efficiency of our approach are demonstrated by extensive experiments on two common benchmark datasets: MPII and COCO. The code is made available in supplementary material.
Attention Deep Model with Multi-Scale Deep Supervision for Person Re-Identification
Nov 27, 2019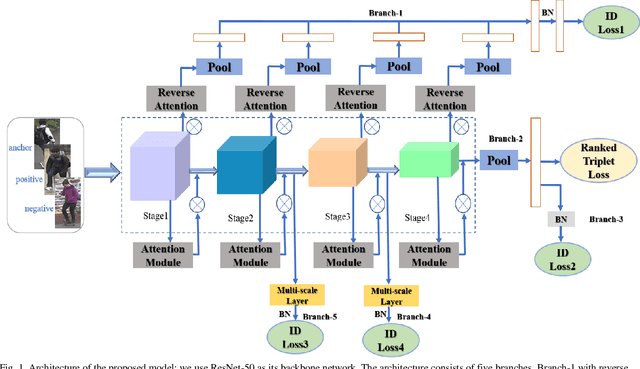
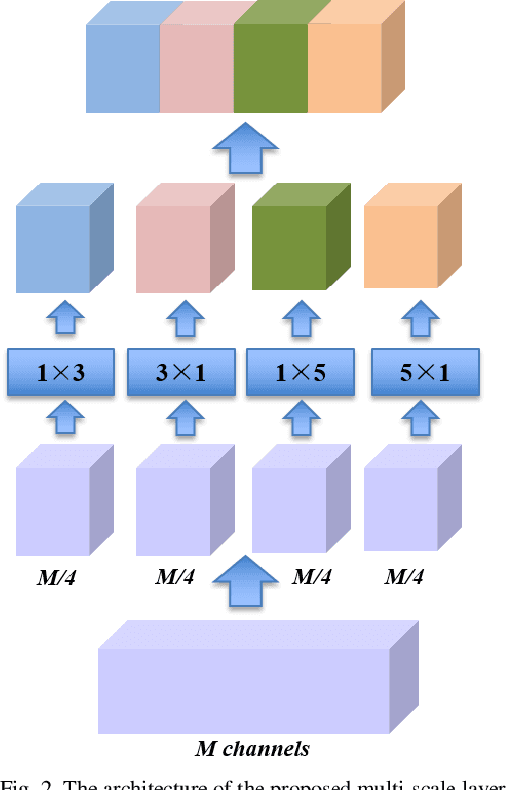
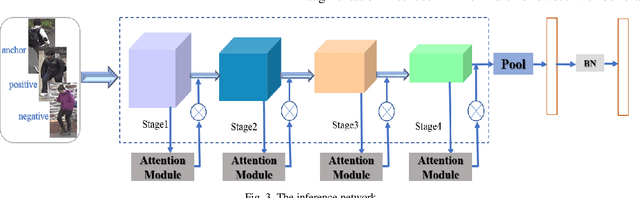
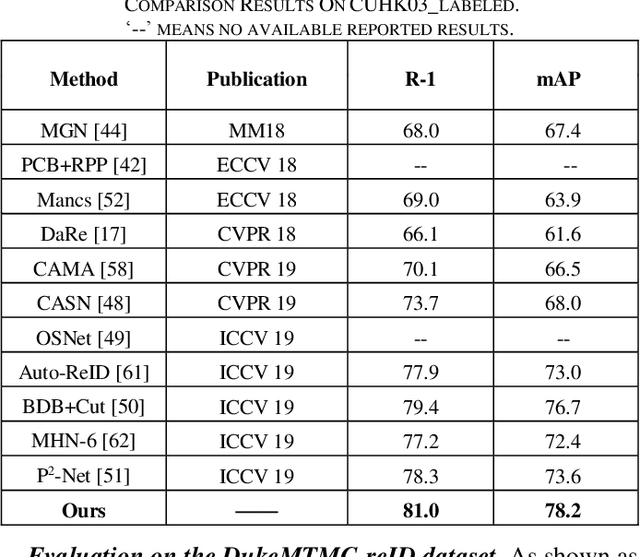
In recent years, person re-identification (PReID) has become a hot topic in computer vision duo to it is an important part in intelligent surveillance. Many state-of-the-art PReID methods are attention-based or multi-scale feature learning deep models. However, introducing attention mechanism may lead to some important feature information losing issue. Besides, most of the multi-scale models embedding the multi-scale feature learning block into the feature extraction deep network, which reduces the efficiency of inference network. To address these issue, in this study, we introduce an attention deep architecture with multi-scale deep supervision for PReID. Technically, we contribute a reverse attention block to complement the attention block, and a novel multi-scale layer with deep supervision operator for training the backbone network. The proposed block and operator are only used for training, and discard in test phase. Experiments have been performed on Market-1501, DukeMTMC-reID and CUHK03 datasets. All the experiment results show that the proposed model significantly outperforms the other competitive state-of-the-art methods.
Omni-directional Feature Learning for Person Re-identification
Dec 13, 2018
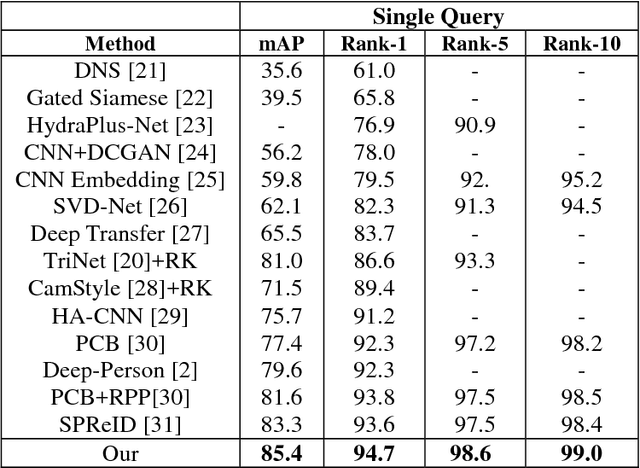
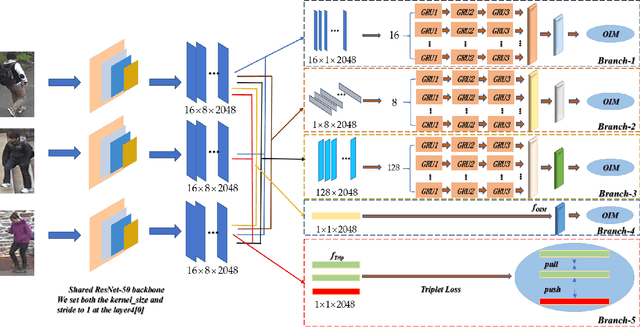
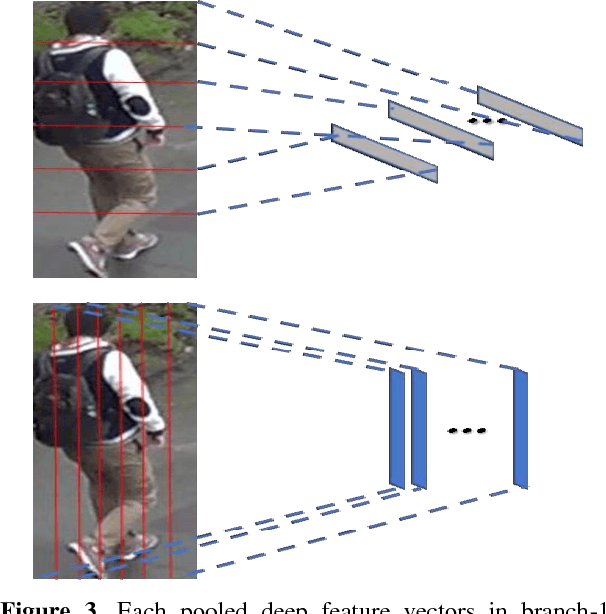
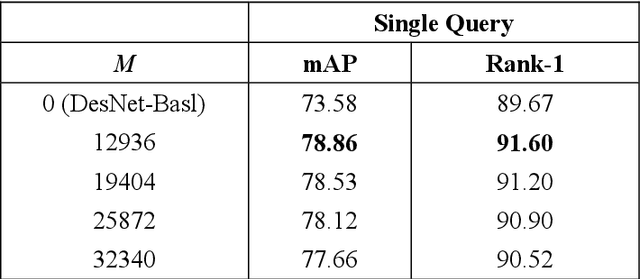
Person re-identification (PReID) has received increasing attention due to it is an important part in intelligent surveillance. Recently, many state-of-the-art methods on PReID are part-based deep models. Most of them focus on learning the part feature representation of person body in horizontal direction. However, the feature representation of body in vertical direction is usually ignored. Besides, the spatial information between these part features and the different feature channels is not considered. In this study, we introduce a multi-branches deep model for PReID. Specifically, the model consists of five branches. Among the five branches, two of them learn the local feature with spatial information from horizontal or vertical orientations, respectively. The other one aims to learn interdependencies knowledge between different feature channels generated by the last convolution layer. The remains of two other branches are identification and triplet sub-networks, in which the discriminative global feature and a corresponding measurement can be learned simultaneously. All the five branches can improve the representation learning. We conduct extensive comparative experiments on three PReID benchmarks including CUHK03, Market-1501 and DukeMTMC-reID. The proposed deep framework outperforms many state-of-the-art in most cases.
Random Occlusion-recovery for Person Re-identification
Oct 15, 2018
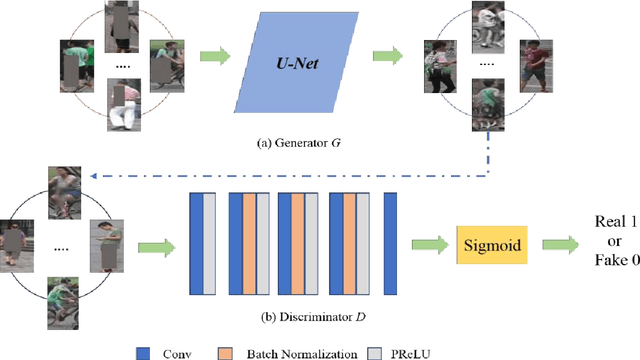
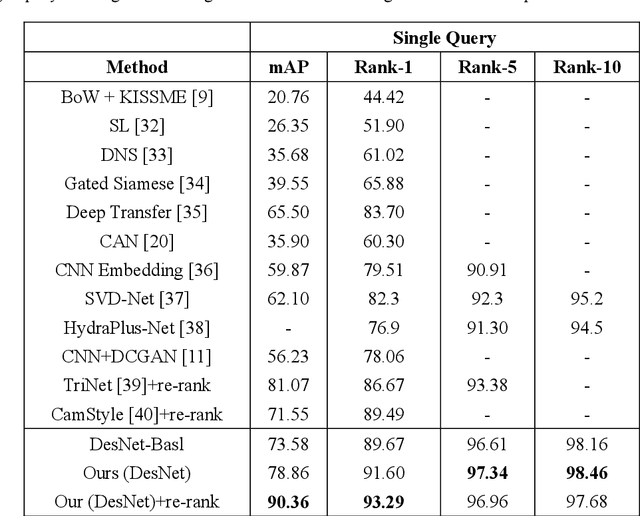
As a basic task of multi-camera surveillance system, person re-identification aims to re-identify a query pedestrian observed from non-overlapping cameras or across different time with a single camera. Recently, Deep learning based person re-identification models have achieved great success in many benchmarks. However, these supervised models require a large amount of labeled image data and the process of manual labeling spends much manpower and time. In this study, we introduce a method to automatically synthesize labeled person images and adopt them to increase the sample number for per identity in datasets. Specifically, we use the block rectangles to occlude the random parts of the persons in the images. Then, a generative adversarial network (GAN) model is proposed to use paired occlusion and original images to synthesize the de-occluded images that similar but not identical to the original images. Afterwards, we annotate the de-occluded images with the same labels of their corresponding raw image and use them to augment the training samples. We use the augmented datasets to train baseline model. The experiment results on Market-1501 and CUHK03 datasets show that the effectiveness of the proposed method.
Optimized Projection for Sparse Representation Based Classification
Jan 31, 2015
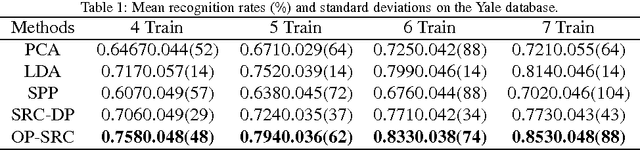
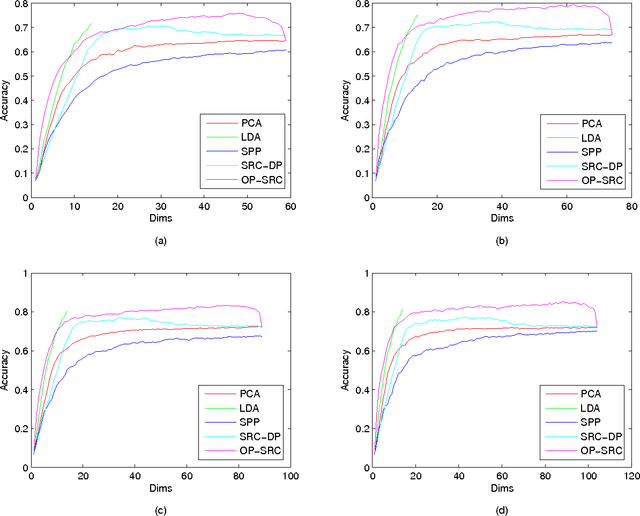
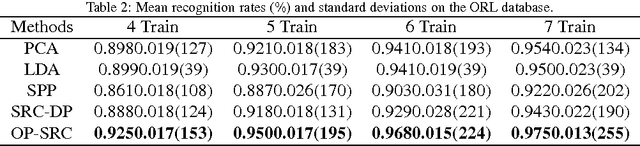
Dimensionality reduction (DR) methods have been commonly used as a principled way to understand the high-dimensional data such as facial images. In this paper, we propose a new supervised DR method called Optimized Projection for Sparse Representation based Classification (OP-SRC), which is based on the recent face recognition method, Sparse Representation based Classification (SRC). SRC seeks a sparse linear combination on all the training data for a given query image, and make the decision by the minimal reconstruction residual. OP-SRC is designed on the decision rule of SRC, it aims to reduce the within-class reconstruction residual and simultaneously increase the between-class reconstruction residual on the training data. The projections are optimized and match well with the mechanism of SRC. Therefore, SRC performs well in the OP-SRC transformed space. The feasibility and effectiveness of the proposed method is verified on the Yale, ORL and UMIST databases with promising results.
Robust and Efficient Subspace Segmentation via Least Squares Regression
Apr 27, 2014
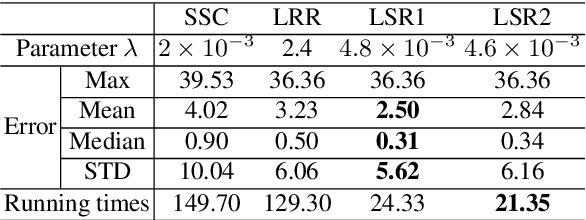
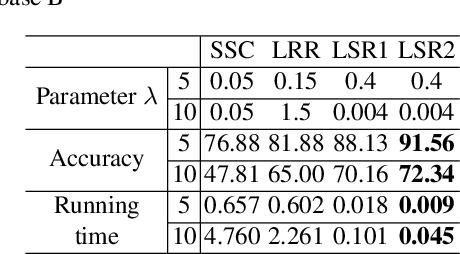
This paper studies the subspace segmentation problem which aims to segment data drawn from a union of multiple linear subspaces. Recent works by using sparse representation, low rank representation and their extensions attract much attention. If the subspaces from which the data drawn are independent or orthogonal, they are able to obtain a block diagonal affinity matrix, which usually leads to a correct segmentation. The main differences among them are their objective functions. We theoretically show that if the objective function satisfies some conditions, and the data are sufficiently drawn from independent subspaces, the obtained affinity matrix is always block diagonal. Furthermore, the data sampling can be insufficient if the subspaces are orthogonal. Some existing methods are all special cases. Then we present the Least Squares Regression (LSR) method for subspace segmentation. It takes advantage of data correlation, which is common in real data. LSR encourages a grouping effect which tends to group highly correlated data together. Experimental results on the Hopkins 155 database and Extended Yale Database B show that our method significantly outperforms state-of-the-art methods. Beyond segmentation accuracy, all experiments demonstrate that LSR is much more efficient.