 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Universal Computational Aberration Correction in Photographic Cameras: A Comprehensive Benchmark Analysis
Mar 12, 2026Prevalent Computational Aberration Correction (CAC) methods are typically tailored to specific optical systems, leading to poor generalization and labor-intensive re-training for new lenses. Developing CAC paradigms capable of generalizing across diverse photographic lenses offers a promising solution to these challenges. However, efforts to achieve such cross-lens universality within consumer photography are still in their early stages due to the lack of a comprehensive benchmark that encompasses a sufficiently wide range of optical aberrations. Furthermore, it remains unclear which specific factors influence existing CAC methods and how these factors affect their performance. In this paper, we present comprehensive experiments and evaluations involving 24 image restoration and CAC algorithms, utilizing our newly proposed UniCAC, a large-scale benchmark for photographic cameras constructed via automatic optical design. The Optical Degradation Evaluator (ODE) is introduced as a novel framework to objectively assess the difficulty of CAC tasks, offering credible quantification of optical aberrations and enabling reliable evaluation. Drawing on our comparative analysis, we identify three key factors -- prior utilization, network architecture, and training strategy -- that most significantly influence CAC performance, and further investigate their respective effects. We believe that our benchmark, dataset, and observations contribute foundational insights to related areas and lay the groundwork for future investigations. Benchmarks, codes, and Zemax files will be available at https://github.com/XiaolongQian/UniCAC.
OPTIAGENT: A Physics-Driven Agentic Framework for Automated Optical Design
Feb 27, 2026Optical design is the process of configuring optical elements to precisely manipulate light for high-fidelity imaging. It is inherently a highly non-convex optimization problem that relies heavily on human heuristic expertise and domain-specific knowledge. While Large Language Models (LLMs) possess extensive optical knowledge, their capabilities in leveraging the knowledge in designing lens system remain significantly constrained. This work represents the first attempt to employ LLMs in the field of optical design. We bridge the expertise gap by enabling users without formal optical training to successfully develop functional lens systems. Concretely, we curate a comprehensive dataset, named OptiDesignQA, which encompasses both classical lens systems sourced from standard optical textbooks and novel configurations generated by automated design algorithms for training and evaluation. Furthermore, we inject domain-specific optical expertise into the LLM through a hybrid objective of full-system synthesis and lens completion. To align the model with optical principles, we employ Group Relative Policy Optimization Done Right (DrGRPO) guided by Optical Lexicographic Reward for physics-driven policy alignment. This reward system incorporates structural format rewards, physical feasibility rewards, light-manipulation accuracy, and LLM-based heuristics. Finally, our model integrates with specialized optical optimization routines for end-to-end fine-tuning and precision refinement. We benchmark our proposed method against both traditional optimization-based automated design algorithms and LLM counterparts, and experimental results show the superiority of our method.
Semiotic Reconstruction of Destination Expectation Constructs An LLM-Driven Computational Paradigm for Social Media Tourism Analytics
May 22, 2025



Social media's rise establishes user-generated content (UGC) as pivotal for travel decisions, yet analytical methods lack scalability. This study introduces a dual-method LLM framework: unsupervised expectation extraction from UGC paired with survey-informed supervised fine-tuning. Findings reveal leisure/social expectations drive engagement more than foundational natural/emotional factors. By establishing LLMs as precision tools for expectation quantification, we advance tourism analytics methodology and propose targeted strategies for experience personalization and social travel promotion. The framework's adaptability extends to consumer behavior research, demonstrating computational social science's transformative potential in marketing optimization.
Benchmarking the Robustness of Optical Flow Estimation to Corruptions
Nov 22, 2024



Optical flow estimation is extensively used in autonomous driving and video editing. While existing models demonstrate state-of-the-art performance across various benchmarks, the robustness of these methods has been infrequently investigated. Despite some research focusing on the robustness of optical flow models against adversarial attacks, there has been a lack of studies investigating their robustness to common corruptions. Taking into account the unique temporal characteristics of optical flow, we introduce 7 temporal corruptions specifically designed for benchmarking the robustness of optical flow models, in addition to 17 classical single-image corruptions, in which advanced PSF Blur simulation method is performed. Two robustness benchmarks, KITTI-FC and GoPro-FC, are subsequently established as the first corruption robustness benchmark for optical flow estimation, with Out-Of-Domain (OOD) and In-Domain (ID) settings to facilitate comprehensive studies. Robustness metrics, Corruption Robustness Error (CRE), Corruption Robustness Error ratio (CREr), and Relative Corruption Robustness Error (RCRE) are further introduced to quantify the optical flow estimation robustness. 29 model variants from 15 optical flow methods are evaluated, yielding 10 intriguing observations, such as 1) the absolute robustness of the model is heavily dependent on the estimation performance; 2) the corruptions that diminish local information are more serious than that reduce visual effects. We also give suggestions for the design and application of optical flow models. We anticipate that our benchmark will serve as a foundational resource for advancing research in robust optical flow estimation. The benchmarks and source code will be released at https://github.com/ZhonghuaYi/optical_flow_robustness_benchmark.
Towards Single-Lens Controllable Depth-of-Field Imaging via All-in-Focus Aberration Correction and Monocular Depth Estimation
Sep 15, 2024



Controllable Depth-of-Field (DoF) imaging commonly produces amazing visual effects based on heavy and expensive high-end lenses. However, confronted with the increasing demand for mobile scenarios, it is desirable to achieve a lightweight solution with Minimalist Optical Systems (MOS). This work centers around two major limitations of MOS, i.e., the severe optical aberrations and uncontrollable DoF, for achieving single-lens controllable DoF imaging via computational methods. A Depth-aware Controllable DoF Imaging (DCDI) framework is proposed equipped with All-in-Focus (AiF) aberration correction and monocular depth estimation, where the recovered image and corresponding depth map are utilized to produce imaging results under diverse DoFs of any high-end lens via patch-wise convolution. To address the depth-varying optical degradation, we introduce a Depth-aware Degradation-adaptive Training (DA2T) scheme. At the dataset level, a Depth-aware Aberration MOS (DAMOS) dataset is established based on the simulation of Point Spread Functions (PSFs) under different object distances. Additionally, we design two plug-and-play depth-aware mechanisms to embed depth information into the aberration image recovery for better tackling depth-aware degradation. Furthermore, we propose a storage-efficient Omni-Lens-Field model to represent the 4D PSF library of various lenses. With the predicted depth map, recovered image, and depth-aware PSF map inferred by Omni-Lens-Field, single-lens controllable DoF imaging is achieved. Comprehensive experimental results demonstrate that the proposed framework enhances the recovery performance, and attains impressive single-lens controllable DoF imaging results, providing a seminal baseline for this field. The source code and the established dataset will be publicly available at https://github.com/XiaolongQian/DCDI.
A Flexible Framework for Universal Computational Aberration Correction via Automatic Lens Library Generation and Domain Adaptation
Sep 09, 2024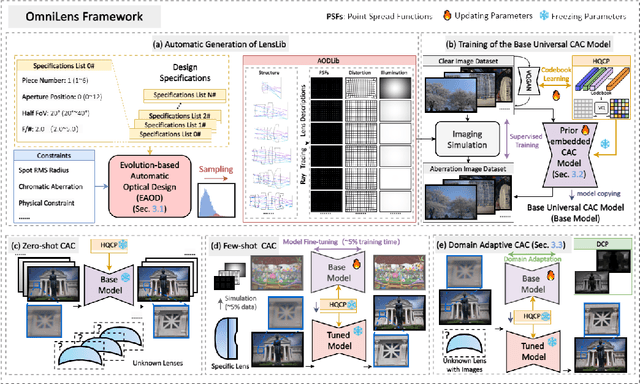
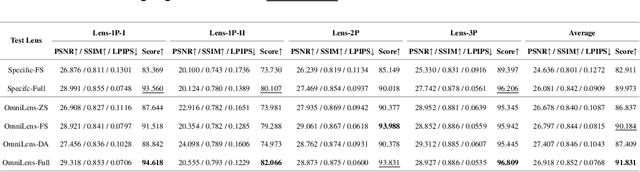

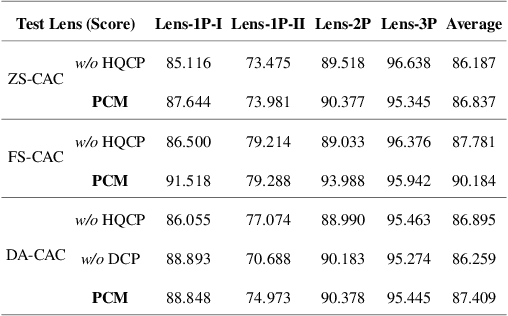
Emerging universal Computational Aberration Correction (CAC) paradigms provide an inspiring solution to light-weight and high-quality imaging without repeated data preparation and model training to accommodate new lens designs. However, the training databases in these approaches, i.e., the lens libraries (LensLibs), suffer from their limited coverage of real-world aberration behaviors. In this work, we set up an OmniLens framework for universal CAC, considering both the generalization ability and flexibility. OmniLens extends the idea of universal CAC to a broader concept, where a base model is trained for three cases, including zero-shot CAC with the pre-trained model, few-shot CAC with a little lens-specific data for fine-tuning, and domain adaptive CAC using domain adaptation for lens-descriptions-unknown lens. In terms of OmniLens's data foundation, we first propose an Evolution-based Automatic Optical Design (EAOD) pipeline to construct LensLib automatically, coined AODLib, whose diversity is enriched by an evolution framework, with comprehensive constraints and a hybrid optimization strategy for achieving realistic aberration behaviors. For network design, we introduce the guidance of high-quality codebook priors to facilitate zero-shot CAC and few-shot CAC, which enhances the model's generalization ability, while also boosting its convergence in a few-shot case. Furthermore, based on the statistical observation of dark channel priors in optical degradation, we design an unsupervised regularization term to adapt the base model to the target descriptions-unknown lens using its aberration images without ground truth. We validate OmniLens on 4 manually designed low-end lenses with various structures and aberration behaviors. Remarkably, the base model trained on AODLib exhibits strong generalization capabilities, achieving 97% of the lens-specific performance in a zero-shot setting.
Global Search Optics: Automatically Exploring Optimal Solutions to Compact Computational Imaging Systems
Apr 30, 2024



The popularity of mobile vision creates a demand for advanced compact computational imaging systems, which call for the development of both a lightweight optical system and an effective image reconstruction model. Recently, joint design pipelines come to the research forefront, where the two significant components are simultaneously optimized via data-driven learning to realize the optimal system design. However, the effectiveness of these designs largely depends on the initial setup of the optical system, complicated by a non-convex solution space that impedes reaching a globally optimal solution. In this work, we present Global Search Optics (GSO) to automatically design compact computational imaging systems through two parts: (i) Fused Optimization Method for Automatic Optical Design (OptiFusion), which searches for diverse initial optical systems under certain design specifications; and (ii) Efficient Physic-aware Joint Optimization (EPJO), which conducts parallel joint optimization of initial optical systems and image reconstruction networks with the consideration of physical constraints, culminating in the selection of the optimal solution. Extensive experimental results on the design of three-piece (3P) sphere computational imaging systems illustrate that the GSO serves as a transformative end-to-end lens design paradigm for superior global optimal structure searching ability, which provides compact computational imaging systems with higher imaging quality compared to traditional methods. The source code will be made publicly available at https://github.com/wumengshenyou/GSO.
Real-World Computational Aberration Correction via Quantized Domain-Mixing Representation
Mar 15, 2024Relying on paired synthetic data, existing learning-based Computational Aberration Correction (CAC) methods are confronted with the intricate and multifaceted synthetic-to-real domain gap, which leads to suboptimal performance in real-world applications. In this paper, in contrast to improving the simulation pipeline, we deliver a novel insight into real-world CAC from the perspective of Unsupervised Domain Adaptation (UDA). By incorporating readily accessible unpaired real-world data into training, we formalize the Domain Adaptive CAC (DACAC) task, and then introduce a comprehensive Real-world aberrated images (Realab) dataset to benchmark it. The setup task presents a formidable challenge due to the intricacy of understanding the target aberration domain. To this intent, we propose a novel Quntized Domain-Mixing Representation (QDMR) framework as a potent solution to the issue. QDMR adapts the CAC model to the target domain from three key aspects: (1) reconstructing aberrated images of both domains by a VQGAN to learn a Domain-Mixing Codebook (DMC) which characterizes the degradation-aware priors; (2) modulating the deep features in CAC model with DMC to transfer the target domain knowledge; and (3) leveraging the trained VQGAN to generate pseudo target aberrated images from the source ones for convincing target domain supervision. Extensive experiments on both synthetic and real-world benchmarks reveal that the models with QDMR consistently surpass the competitive methods in mitigating the synthetic-to-real gap, which produces visually pleasant real-world CAC results with fewer artifacts. Codes and datasets will be made publicly available.
Minimalist and High-Quality Panoramic Imaging with PSF-aware Transformers
Jun 22, 2023High-quality panoramic images with a Field of View (FoV) of 360-degree are essential for contemporary panoramic computer vision tasks. However, conventional imaging systems come with sophisticated lens designs and heavy optical components. This disqualifies their usage in many mobile and wearable applications where thin and portable, minimalist imaging systems are desired. In this paper, we propose a Panoramic Computational Imaging Engine (PCIE) to address minimalist and high-quality panoramic imaging. With less than three spherical lenses, a Minimalist Panoramic Imaging Prototype (MPIP) is constructed based on the design of the Panoramic Annular Lens (PAL), but with low-quality imaging results due to aberrations and small image plane size. We propose two pipelines, i.e. Aberration Correction (AC) and Super-Resolution and Aberration Correction (SR&AC), to solve the image quality problems of MPIP, with imaging sensors of small and large pixel size, respectively. To provide a universal network for the two pipelines, we leverage the information from the Point Spread Function (PSF) of the optical system and design a PSF-aware Aberration-image Recovery Transformer (PART), in which the self-attention calculation and feature extraction are guided via PSF-aware mechanisms. We train PART on synthetic image pairs from simulation and put forward the PALHQ dataset to fill the gap of real-world high-quality PAL images for low-level vision. A comprehensive variety of experiments on synthetic and real-world benchmarks demonstrates the impressive imaging results of PCIE and the effectiveness of plug-and-play PSF-aware mechanisms. We further deliver heuristic experimental findings for minimalist and high-quality panoramic imaging. Our dataset and code will be available at https://github.com/zju-jiangqi/PCIE-PART.
Mode-locking Theory for Long-Range Interaction in Artificial Neural Networks
Mar 10, 2023



Visual long-range interaction refers to modeling dependencies between distant feature points or blocks within an image, which can significantly enhance the model's robustness. Both CNN and Transformer can establish long-range interactions through layering and patch calculations. However, the underlying mechanism of long-range interaction in visual space remains unclear. We propose the mode-locking theory as the underlying mechanism, which constrains the phase and wavelength relationship between waves to achieve mode-locked interference waveform. We verify this theory through simulation experiments and demonstrate the mode-locking pattern in real-world scene models. Our proposed theory of long-range interaction provides a comprehensive understanding of the mechanism behind this phenomenon in artificial neural networks. This theory can inspire the integration of the mode-locking pattern into models to enhance their robustness.