 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Method for Building Large Language Models with Predefined KV Cache Capacity
Nov 24, 2024
This paper proposes a method for building large language models with predefined Key-Value (KV) cache capacity, particularly suitable for the attention layers in Transformer decode-only architectures. This method introduces fixed-length KV caches to address the issue of excessive memory consumption in traditional KV caches when handling infinite contexts. By dynamically updating the key-value vector sequences, it achieves efficient inference within limited cache capacity, significantly reducing memory usage while maintaining model performance and system throughput. Experimental results show that this method significantly reduces memory usage while maintaining the model's inference quality.
Benchmarking the Robustness of Optical Flow Estimation to Corruptions
Nov 22, 2024



Optical flow estimation is extensively used in autonomous driving and video editing. While existing models demonstrate state-of-the-art performance across various benchmarks, the robustness of these methods has been infrequently investigated. Despite some research focusing on the robustness of optical flow models against adversarial attacks, there has been a lack of studies investigating their robustness to common corruptions. Taking into account the unique temporal characteristics of optical flow, we introduce 7 temporal corruptions specifically designed for benchmarking the robustness of optical flow models, in addition to 17 classical single-image corruptions, in which advanced PSF Blur simulation method is performed. Two robustness benchmarks, KITTI-FC and GoPro-FC, are subsequently established as the first corruption robustness benchmark for optical flow estimation, with Out-Of-Domain (OOD) and In-Domain (ID) settings to facilitate comprehensive studies. Robustness metrics, Corruption Robustness Error (CRE), Corruption Robustness Error ratio (CREr), and Relative Corruption Robustness Error (RCRE) are further introduced to quantify the optical flow estimation robustness. 29 model variants from 15 optical flow methods are evaluated, yielding 10 intriguing observations, such as 1) the absolute robustness of the model is heavily dependent on the estimation performance; 2) the corruptions that diminish local information are more serious than that reduce visual effects. We also give suggestions for the design and application of optical flow models. We anticipate that our benchmark will serve as a foundational resource for advancing research in robust optical flow estimation. The benchmarks and source code will be released at https://github.com/ZhonghuaYi/optical_flow_robustness_benchmark.
EI-Nexus: Towards Unmediated and Flexible Inter-Modality Local Feature Extraction and Matching for Event-Image Data
Oct 29, 2024



Event cameras, with high temporal resolution and high dynamic range, have limited research on the inter-modality local feature extraction and matching of event-image data. We propose EI-Nexus, an unmediated and flexible framework that integrates two modality-specific keypoint extractors and a feature matcher. To achieve keypoint extraction across viewpoint and modality changes, we bring Local Feature Distillation (LFD), which transfers the viewpoint consistency from a well-learned image extractor to the event extractor, ensuring robust feature correspondence. Furthermore, with the help of Context Aggregation (CA), a remarkable enhancement is observed in feature matching. We further establish the first two inter-modality feature matching benchmarks, MVSEC-RPE and EC-RPE, to assess relative pose estimation on event-image data. Our approach outperforms traditional methods that rely on explicit modal transformation, offering more unmediated and adaptable feature extraction and matching, achieving better keypoint similarity and state-of-the-art results on the MVSEC-RPE and EC-RPE benchmarks. The source code and benchmarks will be made publicly available at https://github.com/ZhonghuaYi/EI-Nexus_official.
Towards Single-Lens Controllable Depth-of-Field Imaging via All-in-Focus Aberration Correction and Monocular Depth Estimation
Sep 15, 2024



Controllable Depth-of-Field (DoF) imaging commonly produces amazing visual effects based on heavy and expensive high-end lenses. However, confronted with the increasing demand for mobile scenarios, it is desirable to achieve a lightweight solution with Minimalist Optical Systems (MOS). This work centers around two major limitations of MOS, i.e., the severe optical aberrations and uncontrollable DoF, for achieving single-lens controllable DoF imaging via computational methods. A Depth-aware Controllable DoF Imaging (DCDI) framework is proposed equipped with All-in-Focus (AiF) aberration correction and monocular depth estimation, where the recovered image and corresponding depth map are utilized to produce imaging results under diverse DoFs of any high-end lens via patch-wise convolution. To address the depth-varying optical degradation, we introduce a Depth-aware Degradation-adaptive Training (DA2T) scheme. At the dataset level, a Depth-aware Aberration MOS (DAMOS) dataset is established based on the simulation of Point Spread Functions (PSFs) under different object distances. Additionally, we design two plug-and-play depth-aware mechanisms to embed depth information into the aberration image recovery for better tackling depth-aware degradation. Furthermore, we propose a storage-efficient Omni-Lens-Field model to represent the 4D PSF library of various lenses. With the predicted depth map, recovered image, and depth-aware PSF map inferred by Omni-Lens-Field, single-lens controllable DoF imaging is achieved. Comprehensive experimental results demonstrate that the proposed framework enhances the recovery performance, and attains impressive single-lens controllable DoF imaging results, providing a seminal baseline for this field. The source code and the established dataset will be publicly available at https://github.com/XiaolongQian/DCDI.
A Flexible Framework for Universal Computational Aberration Correction via Automatic Lens Library Generation and Domain Adaptation
Sep 09, 2024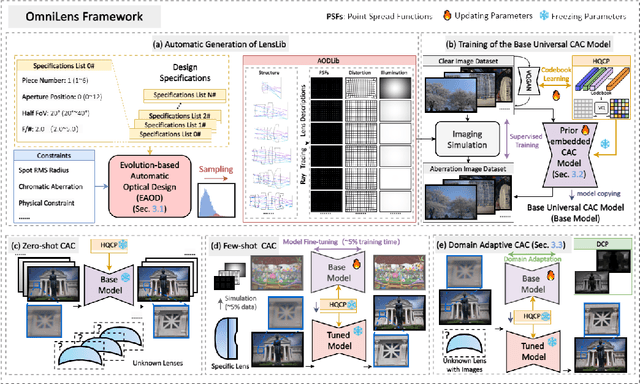
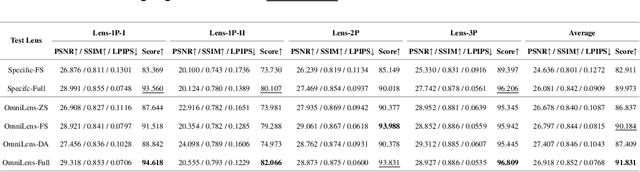

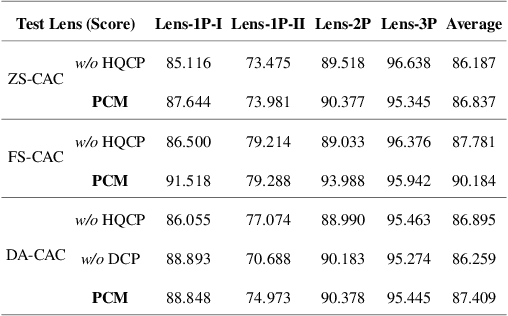
Emerging universal Computational Aberration Correction (CAC) paradigms provide an inspiring solution to light-weight and high-quality imaging without repeated data preparation and model training to accommodate new lens designs. However, the training databases in these approaches, i.e., the lens libraries (LensLibs), suffer from their limited coverage of real-world aberration behaviors. In this work, we set up an OmniLens framework for universal CAC, considering both the generalization ability and flexibility. OmniLens extends the idea of universal CAC to a broader concept, where a base model is trained for three cases, including zero-shot CAC with the pre-trained model, few-shot CAC with a little lens-specific data for fine-tuning, and domain adaptive CAC using domain adaptation for lens-descriptions-unknown lens. In terms of OmniLens's data foundation, we first propose an Evolution-based Automatic Optical Design (EAOD) pipeline to construct LensLib automatically, coined AODLib, whose diversity is enriched by an evolution framework, with comprehensive constraints and a hybrid optimization strategy for achieving realistic aberration behaviors. For network design, we introduce the guidance of high-quality codebook priors to facilitate zero-shot CAC and few-shot CAC, which enhances the model's generalization ability, while also boosting its convergence in a few-shot case. Furthermore, based on the statistical observation of dark channel priors in optical degradation, we design an unsupervised regularization term to adapt the base model to the target descriptions-unknown lens using its aberration images without ground truth. We validate OmniLens on 4 manually designed low-end lenses with various structures and aberration behaviors. Remarkably, the base model trained on AODLib exhibits strong generalization capabilities, achieving 97% of the lens-specific performance in a zero-shot setting.
Real-World Computational Aberration Correction via Quantized Domain-Mixing Representation
Mar 15, 2024Relying on paired synthetic data, existing learning-based Computational Aberration Correction (CAC) methods are confronted with the intricate and multifaceted synthetic-to-real domain gap, which leads to suboptimal performance in real-world applications. In this paper, in contrast to improving the simulation pipeline, we deliver a novel insight into real-world CAC from the perspective of Unsupervised Domain Adaptation (UDA). By incorporating readily accessible unpaired real-world data into training, we formalize the Domain Adaptive CAC (DACAC) task, and then introduce a comprehensive Real-world aberrated images (Realab) dataset to benchmark it. The setup task presents a formidable challenge due to the intricacy of understanding the target aberration domain. To this intent, we propose a novel Quntized Domain-Mixing Representation (QDMR) framework as a potent solution to the issue. QDMR adapts the CAC model to the target domain from three key aspects: (1) reconstructing aberrated images of both domains by a VQGAN to learn a Domain-Mixing Codebook (DMC) which characterizes the degradation-aware priors; (2) modulating the deep features in CAC model with DMC to transfer the target domain knowledge; and (3) leveraging the trained VQGAN to generate pseudo target aberrated images from the source ones for convincing target domain supervision. Extensive experiments on both synthetic and real-world benchmarks reveal that the models with QDMR consistently surpass the competitive methods in mitigating the synthetic-to-real gap, which produces visually pleasant real-world CAC results with fewer artifacts. Codes and datasets will be made publicly available.
FocusFlow: Boosting Key-Points Optical Flow Estimation for Autonomous Driving
Aug 14, 2023Key-point-based scene understanding is fundamental for autonomous driving applications. At the same time, optical flow plays an important role in many vision tasks. However, due to the implicit bias of equal attention on all points, classic data-driven optical flow estimation methods yield less satisfactory performance on key points, limiting their implementations in key-point-critical safety-relevant scenarios. To address these issues, we introduce a points-based modeling method that requires the model to learn key-point-related priors explicitly. Based on the modeling method, we present FocusFlow, a framework consisting of 1) a mix loss function combined with a classic photometric loss function and our proposed Conditional Point Control Loss (CPCL) function for diverse point-wise supervision; 2) a conditioned controlling model which substitutes the conventional feature encoder by our proposed Condition Control Encoder (CCE). CCE incorporates a Frame Feature Encoder (FFE) that extracts features from frames, a Condition Feature Encoder (CFE) that learns to control the feature extraction behavior of FFE from input masks containing information of key points, and fusion modules that transfer the controlling information between FFE and CFE. Our FocusFlow framework shows outstanding performance with up to +44.5% precision improvement on various key points such as ORB, SIFT, and even learning-based SiLK, along with exceptional scalability for most existing data-driven optical flow methods like PWC-Net, RAFT, and FlowFormer. Notably, FocusFlow yields competitive or superior performances rivaling the original models on the whole frame. The source code will be available at https://github.com/ZhonghuaYi/FocusFlow_official.
Minimalist and High-Quality Panoramic Imaging with PSF-aware Transformers
Jun 22, 2023High-quality panoramic images with a Field of View (FoV) of 360-degree are essential for contemporary panoramic computer vision tasks. However, conventional imaging systems come with sophisticated lens designs and heavy optical components. This disqualifies their usage in many mobile and wearable applications where thin and portable, minimalist imaging systems are desired. In this paper, we propose a Panoramic Computational Imaging Engine (PCIE) to address minimalist and high-quality panoramic imaging. With less than three spherical lenses, a Minimalist Panoramic Imaging Prototype (MPIP) is constructed based on the design of the Panoramic Annular Lens (PAL), but with low-quality imaging results due to aberrations and small image plane size. We propose two pipelines, i.e. Aberration Correction (AC) and Super-Resolution and Aberration Correction (SR&AC), to solve the image quality problems of MPIP, with imaging sensors of small and large pixel size, respectively. To provide a universal network for the two pipelines, we leverage the information from the Point Spread Function (PSF) of the optical system and design a PSF-aware Aberration-image Recovery Transformer (PART), in which the self-attention calculation and feature extraction are guided via PSF-aware mechanisms. We train PART on synthetic image pairs from simulation and put forward the PALHQ dataset to fill the gap of real-world high-quality PAL images for low-level vision. A comprehensive variety of experiments on synthetic and real-world benchmarks demonstrates the impressive imaging results of PCIE and the effectiveness of plug-and-play PSF-aware mechanisms. We further deliver heuristic experimental findings for minimalist and high-quality panoramic imaging. Our dataset and code will be available at https://github.com/zju-jiangqi/PCIE-PART.