 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Human Pose Estimation for Autonomous Driving with 3D Event Representations
Nov 09, 2023Human pose estimation is a critical component in autonomous driving and parking, enhancing safety by predicting human actions. Traditional frame-based cameras and videos are commonly applied, yet, they become less reliable in scenarios under high dynamic range or heavy motion blur. In contrast, event cameras offer a robust solution for navigating these challenging contexts. Predominant methodologies incorporate event cameras into learning frameworks by accumulating events into event frames. However, such methods tend to marginalize the intrinsic asynchronous and high temporal resolution characteristics of events. This disregard leads to a loss in essential temporal dimension data, crucial for safety-critical tasks associated with dynamic human activities. To address this issue and to unlock the 3D potential of event information, we introduce two 3D event representations: the Rasterized Event Point Cloud (RasEPC) and the Decoupled Event Voxel (DEV). The RasEPC collates events within concise temporal slices at identical positions, preserving 3D attributes with statistical cues and markedly mitigating memory and computational demands. Meanwhile, the DEV representation discretizes events into voxels and projects them across three orthogonal planes, utilizing decoupled event attention to retrieve 3D cues from the 2D planes. Furthermore, we develop and release EV-3DPW, a synthetic event-based dataset crafted to facilitate training and quantitative analysis in outdoor scenes. On the public real-world DHP19 dataset, our event point cloud technique excels in real-time mobile predictions, while the decoupled event voxel method achieves the highest accuracy. Experiments reveal our proposed 3D representation methods' superior generalization capacities against traditional RGB images and event frame techniques. Our code and dataset are available at https://github.com/MasterHow/EventPointPose.
FocusFlow: Boosting Key-Points Optical Flow Estimation for Autonomous Driving
Aug 14, 2023Key-point-based scene understanding is fundamental for autonomous driving applications. At the same time, optical flow plays an important role in many vision tasks. However, due to the implicit bias of equal attention on all points, classic data-driven optical flow estimation methods yield less satisfactory performance on key points, limiting their implementations in key-point-critical safety-relevant scenarios. To address these issues, we introduce a points-based modeling method that requires the model to learn key-point-related priors explicitly. Based on the modeling method, we present FocusFlow, a framework consisting of 1) a mix loss function combined with a classic photometric loss function and our proposed Conditional Point Control Loss (CPCL) function for diverse point-wise supervision; 2) a conditioned controlling model which substitutes the conventional feature encoder by our proposed Condition Control Encoder (CCE). CCE incorporates a Frame Feature Encoder (FFE) that extracts features from frames, a Condition Feature Encoder (CFE) that learns to control the feature extraction behavior of FFE from input masks containing information of key points, and fusion modules that transfer the controlling information between FFE and CFE. Our FocusFlow framework shows outstanding performance with up to +44.5% precision improvement on various key points such as ORB, SIFT, and even learning-based SiLK, along with exceptional scalability for most existing data-driven optical flow methods like PWC-Net, RAFT, and FlowFormer. Notably, FocusFlow yields competitive or superior performances rivaling the original models on the whole frame. The source code will be available at https://github.com/ZhonghuaYi/FocusFlow_official.
Towards Anytime Optical Flow Estimation with Event Cameras
Jul 11, 2023



Event cameras are capable of responding to log-brightness changes in microseconds. Its characteristic of producing responses only to the changing region is particularly suitable for optical flow estimation. In contrast to the super low-latency response speed of event cameras, existing datasets collected via event cameras, however, only provide limited frame rate optical flow ground truth, (e.g., at 10Hz), greatly restricting the potential of event-driven optical flow. To address this challenge, we put forward a high-frame-rate, low-latency event representation Unified Voxel Grid, sequentially fed into the network bin by bin. We then propose EVA-Flow, an EVent-based Anytime Flow estimation network to produce high-frame-rate event optical flow with only low-frame-rate optical flow ground truth for supervision. The key component of our EVA-Flow is the stacked Spatiotemporal Motion Refinement (SMR) module, which predicts temporally-dense optical flow and enhances the accuracy via spatial-temporal motion refinement. The time-dense feature warping utilized in the SMR module provides implicit supervision for the intermediate optical flow. Additionally, we introduce the Rectified Flow Warp Loss (RFWL) for the unsupervised evaluation of intermediate optical flow in the absence of ground truth. This is, to the best of our knowledge, the first work focusing on anytime optical flow estimation via event cameras. A comprehensive variety of experiments on MVSEC, DESC, and our EVA-FlowSet demonstrates that EVA-Flow achieves competitive performance, super-low-latency (5ms), fastest inference (9.2ms), time-dense motion estimation (200Hz), and strong generalization. Our code will be available at https://github.com/Yaozhuwa/EVA-Flow.
FishDreamer: Towards Fisheye Semantic Completion via Unified Image Outpainting and Segmentation
Mar 24, 2023



This paper raises the new task of Fisheye Semantic Completion (FSC), where dense texture, structure, and semantics of a fisheye image are inferred even beyond the sensor field-of-view (FoV). Fisheye cameras have larger FoV than ordinary pinhole cameras, yet its unique special imaging model naturally leads to a blind area at the edge of the image plane. This is suboptimal for safety-critical applications since important perception tasks, such as semantic segmentation, become very challenging within the blind zone. Previous works considered the out-FoV outpainting and in-FoV segmentation separately. However, we observe that these two tasks are actually closely coupled. To jointly estimate the tightly intertwined complete fisheye image and scene semantics, we introduce the new FishDreamer which relies on successful ViTs enhanced with a novel Polar-aware Cross Attention module (PCA) to leverage dense context and guide semantically-consistent content generation while considering different polar distributions. In addition to the contribution of the novel task and architecture, we also derive Cityscapes-BF and KITTI360-BF datasets to facilitate training and evaluation of this new track. Our experiments demonstrate that the proposed FishDreamer outperforms methods solving each task in isolation and surpasses alternative approaches on the Fisheye Semantic Completion. Code and datasets will be available at https://github.com/MasterHow/FishDreamer.
Efficient Human Pose Estimation via 3D Event Point Cloud
Jun 09, 2022



Human Pose Estimation (HPE) based on RGB images has experienced a rapid development benefiting from deep learning. However, event-based HPE has not been fully studied, which remains great potential for applications in extreme scenes and efficiency-critical conditions. In this paper, we are the first to estimate 2D human pose directly from 3D event point cloud. We propose a novel representation of events, the rasterized event point cloud, aggregating events on the same position of a small time slice. It maintains the 3D features from multiple statistical cues and significantly reduces memory consumption and computation complexity, proved to be efficient in our work. We then leverage the rasterized event point cloud as input to three different backbones, PointNet, DGCNN, and Point Transformer, with two linear layer decoders to predict the location of human keypoints. We find that based on our method, PointNet achieves promising results with much faster speed, whereas Point Transfomer reaches much higher accuracy, even close to previous event-frame-based methods. A comprehensive set of results demonstrates that our proposed method is consistently effective for these 3D backbone models in event-driven human pose estimation. Our method based on PointNet with 2048 points input achieves 82.46mm in MPJPE3D on the DHP19 dataset, while only has a latency of 12.29ms on an NVIDIA Jetson Xavier NX edge computing platform, which is ideally suitable for real-time detection with event cameras. Code will be made publicly at https://github.com/MasterHow/EventPointPose.
PanoFlow: Learning Optical Flow for Panoramic Images
Feb 27, 2022
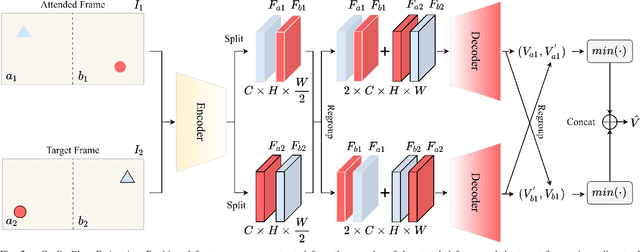


Optical flow estimation is a basic task in self-driving and robotics systems, which enables to temporally interpret the traffic scene. Autonomous vehicles clearly benefit from the ultra-wide Field of View (FoV) offered by 360-degree panoramic sensors. However, due to the unique imaging process of panoramic images, models designed for pinhole images do not directly generalize satisfactorily to 360-degree panoramic images. In this paper, we put forward a novel network framework--PanoFlow, to learn optical flow for panoramic images. To overcome the distortions introduced by equirectangular projection in panoramic transformation, we design a Flow Distortion Augmentation (FDA) method. We further propose a Cyclic Flow Estimation (CFE) method by leveraging the cyclicity of spherical images to infer 360-degree optical flow and converting large displacement to relatively small displacement. PanoFlow is applicable to any existing flow estimation method and benefit from the progress of narrow-FoV flow estimation. In addition, we create and release a synthetic panoramic dataset Flow360 based on CARLA to facilitate training and quantitative analysis. PanoFlow achieves state-of-the-art performance. Our proposed approach reduces the End-Point-Error (EPE) on the established Flow360 dataset by 26%. On the public OmniFlowNet dataset, PanoFlow achieves an EPE of 3.34 pixels, a 53.1% error reduction from the best published result (7.12 pixels). We also validate our method via an outdoor collection vehicle, indicating strong potential and robustness for real-world navigation applications. Code and dataset are publicly available at https://github.com/MasterHow/PanoFlow.
MEFNet: Multi-scale Event Fusion Network for Motion Deblurring
Nov 30, 2021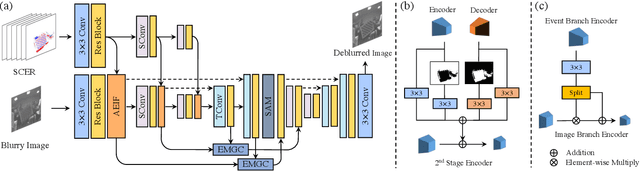

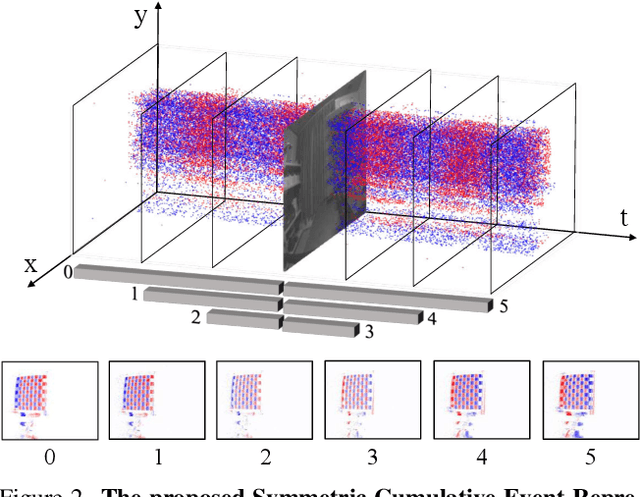

Traditional frame-based cameras inevitably suffer from motion blur due to long exposure times. As a kind of bio-inspired camera, the event camera records the intensity changes in an asynchronous way with high temporal resolution, providing valid image degradation information within the exposure time. In this paper, we rethink the event-based image deblurring problem and unfold it into an end-to-end two-stage image restoration network. To effectively utilize event information, we design (i) a novel symmetric cumulative event representation specifically for image deblurring, and (ii) an affine event-image fusion module applied at multiple levels of our network. We also propose an event mask gated connection between the two stages of the network so as to avoid information loss. At the dataset level, to foster event-based motion deblurring and to facilitate evaluation on challenging real-world images, we introduce the High-Quality Blur (HQBlur) dataset, captured with an event camera in an illumination-controlled optical laboratory. Our Multi-Scale Event Fusion Network (MEFNet) sets the new state of the art for motion deblurring, surpassing both the prior best-performing image-based method and all event-based methods with public implementations on the GoPro (by up to 2.38dB) and HQBlur datasets, even in extreme blurry conditions. Source code and dataset will be made publicly available.
Universal Semantic Segmentation for Fisheye Urban Driving Images
Jan 31, 2020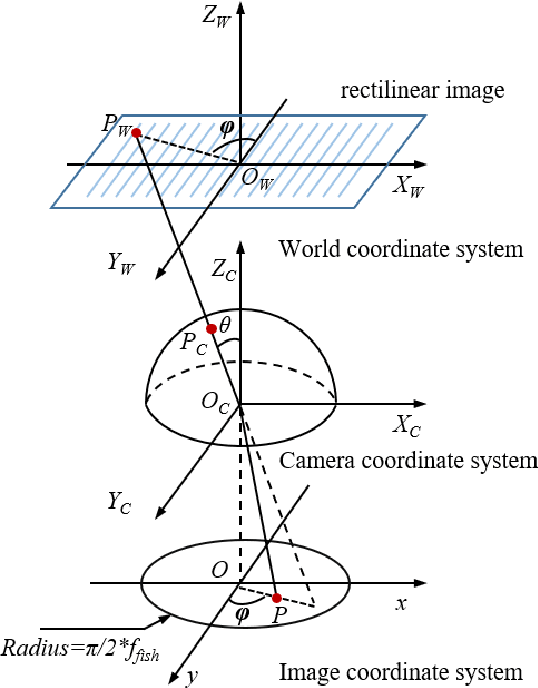

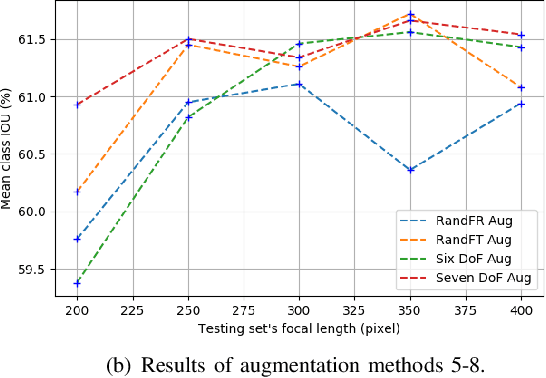
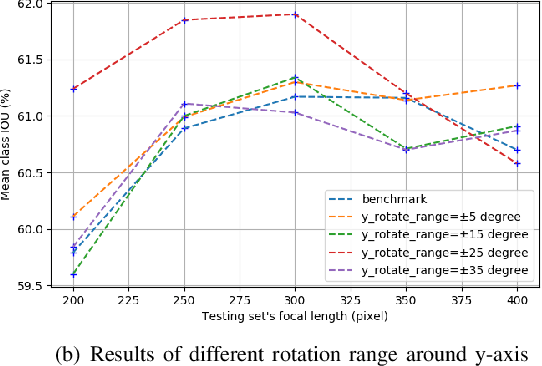
Semantic segmentation is a critical method in the field of autonomous driving. When performing semantic image segmentation, a wider field of view (FoV) helps to obtain more information about the surrounding environment, making automatic driving safer and more reliable, which could be offered by fisheye cameras. However, large public fisheye data sets are not available, and the fisheye images captured by the fisheye camera with large FoV comes with large distortion, so commonly-used semantic segmentation model cannot be directly utilized. In this paper, a seven degrees of freedom (DoF) augmentation method is proposed to transform rectilinear image to fisheye image in a more comprehensive way. In the training process, rectilinear images are transformed into fisheye images in seven DoF, which simulates the fisheye images taken by cameras of different positions, orientations and focal lengths. The result shows that training with the seven-DoF augmentation can evidently improve the model's accuracy and robustness against different distorted fisheye data. This seven-DoF augmentation provides an universal semantic segmentation solution for fisheye cameras in different autonomous driving applications. Also, we provide specific parameter settings of the augmentation for autonomous driving. At last, we tested our universal semantic segmentation model on real fisheye images and obtained satisfactory results. The code and configurations are released at \url{https://github.com/Yaozhuwa/FisheyeSeg}.