 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolarization-driven Semantic Segmentation via Efficient Attention-bridged Fusion
Nov 26, 2020
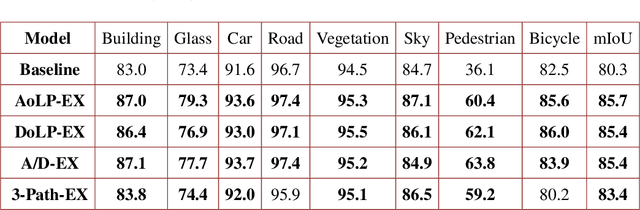

Semantic Segmentation (SS) is promising for outdoor scene perception in safety-critical applications like autonomous vehicles, assisted navigation and so on. However, traditional SS is primarily based on RGB images, which limits the reliability of SS in complex outdoor scenes, where RGB images lack necessary information dimensions to fully perceive unconstrained environments. As preliminary investigation, we examine SS in an unexpected obstacle detection scenario, which demonstrates the necessity of multimodal fusion. Thereby, in this work, we present EAFNet, an Efficient Attention-bridged Fusion Network to exploit complementary information coming from different optical sensors. Specifically, we incorporate polarization sensing to obtain supplementary information, considering its optical characteristics for robust representation of diverse materials. By using a single-shot polarization sensor, we build the first RGB-P dataset which consists of 394 annotated pixel-aligned RGB-Polarization images. A comprehensive variety of experiments shows the effectiveness of EAFNet to fuse polarization and RGB information, as well as the flexibility to be adapted to other sensor combination scenarios.
Universal Semantic Segmentation for Fisheye Urban Driving Images
Jan 31, 2020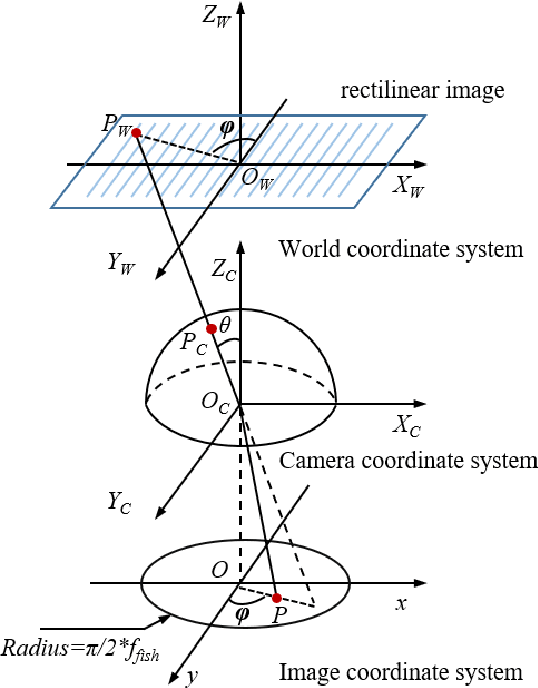

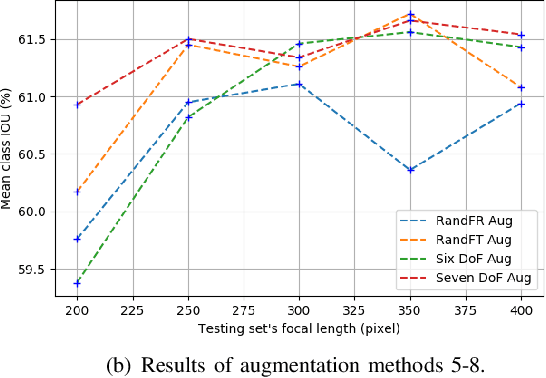
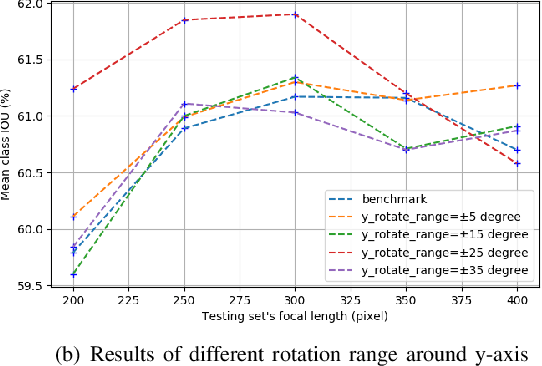
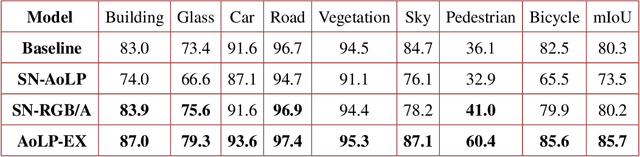
Semantic segmentation is a critical method in the field of autonomous driving. When performing semantic image segmentation, a wider field of view (FoV) helps to obtain more information about the surrounding environment, making automatic driving safer and more reliable, which could be offered by fisheye cameras. However, large public fisheye data sets are not available, and the fisheye images captured by the fisheye camera with large FoV comes with large distortion, so commonly-used semantic segmentation model cannot be directly utilized. In this paper, a seven degrees of freedom (DoF) augmentation method is proposed to transform rectilinear image to fisheye image in a more comprehensive way. In the training process, rectilinear images are transformed into fisheye images in seven DoF, which simulates the fisheye images taken by cameras of different positions, orientations and focal lengths. The result shows that training with the seven-DoF augmentation can evidently improve the model's accuracy and robustness against different distorted fisheye data. This seven-DoF augmentation provides an universal semantic segmentation solution for fisheye cameras in different autonomous driving applications. Also, we provide specific parameter settings of the augmentation for autonomous driving. At last, we tested our universal semantic segmentation model on real fisheye images and obtained satisfactory results. The code and configurations are released at \url{https://github.com/Yaozhuwa/FisheyeSeg}.
DS-PASS: Detail-Sensitive Panoramic Annular Semantic Segmentation through SwaftNet for Surrounding Sensing
Sep 17, 2019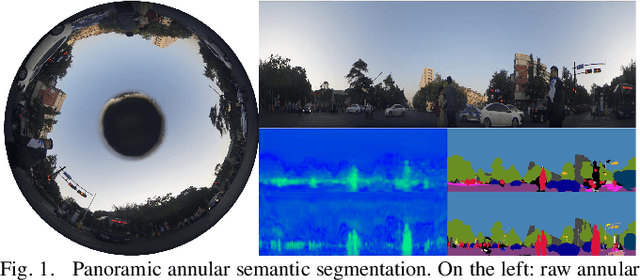
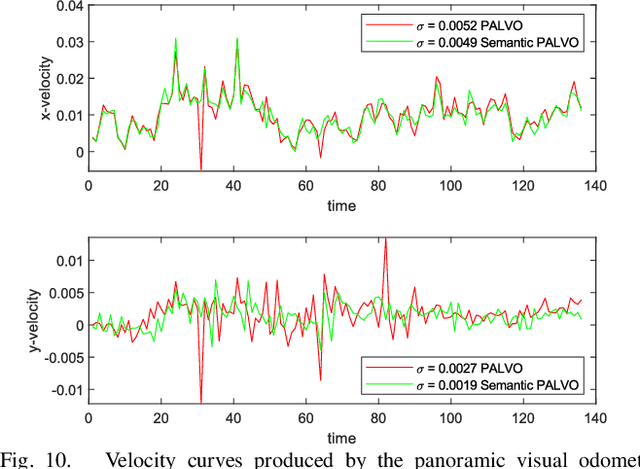
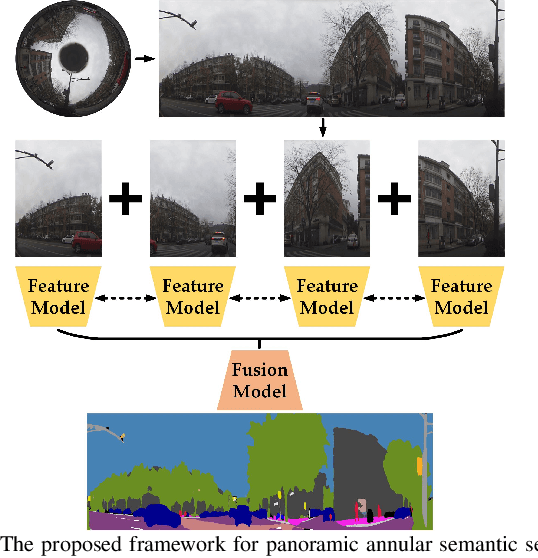
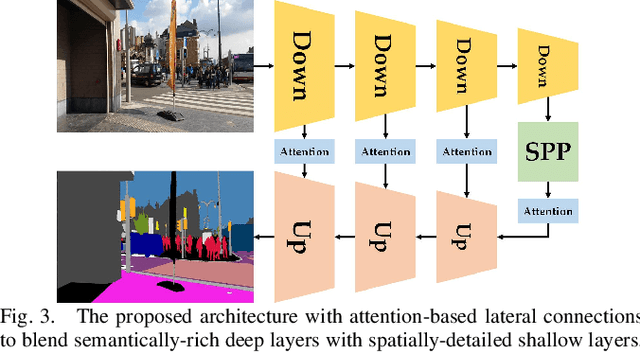
Semantically interpreting the traffic scene is crucial for autonomous transportation and robotics. However, state-of-the-art semantic segmentation pipelines are dominantly designed to work with pinhole cameras and train with narrow Field-of-View (FoV) images. In this sense, the perception capacity is severely limited to offer higher-level of confidence for upstream navigation tasks. In this paper, we propose a network adaptation framework to achieve Panoramic Annular Semantic Segmentation (PASS), which allows to re-use conventional pinhole-view image datasets, enabling modern segmentation networks to comfortably adapt to panoramic images. Specifically, we adapt our proposed SwaftNet to enhance the sensitivity to details by implementing attention-based lateral connections between the detail-critical encoder layers and the context-critical decoder layers. We benchmark the performance of efficient segmenters on panoramic segmentation with our extended PASS dataset, demonstrating that the proposed real-time SwaftNet outperforms state-of-the-art efficient networks. Furthermore, we assess real-world performance when deploying the Detail-Sensitive PASS (DS-PASS) system on a mobile robot and an instrumented vehicle, as well as the benefit of panoramic semantics for visual odometry, showing the robustness and potential to support diverse navigational applications.
See Clearer at Night: Towards Robust Nighttime Semantic Segmentation through Day-Night Image Conversion
Aug 16, 2019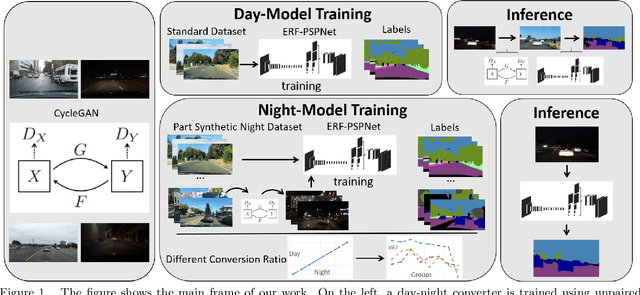
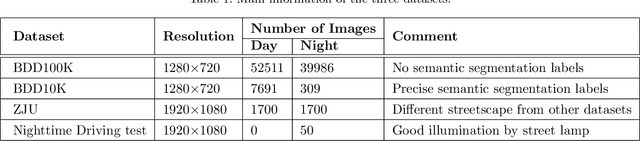


Currently, semantic segmentation shows remarkable efficiency and reliability in standard scenarios such as daytime scenes with favorable illumination conditions. However, in face of adverse conditions such as the nighttime, semantic segmentation loses its accuracy significantly. One of the main causes of the problem is the lack of sufficient annotated segmentation datasets of nighttime scenes. In this paper, we propose a framework to alleviate the accuracy decline when semantic segmentation is taken to adverse conditions by using Generative Adversarial Networks (GANs). To bridge the daytime and nighttime image domains, we made key observation that compared to datasets in adverse conditions, there are considerable amount of segmentation datasets in standard conditions such as BDD and our collected ZJU datasets. Our GAN-based nighttime semantic segmentation framework includes two methods. In the first method, GANs were used to translate nighttime images to the daytime, thus semantic segmentation can be performed using robust models already trained on daytime datasets. In another method, we use GANs to translate different ratio of daytime images in the dataset to the nighttime but still with their labels. In this sense, synthetic nighttime segmentation datasets can be generated to yield models prepared to operate at nighttime conditions robustly. In our experiment, the later method significantly boosts the performance at the nighttime evidenced by quantitative results using Intersection over Union (IoU) and Pixel Accuracy (Acc). We show that the performance varies with respect to the proportion of synthetic nighttime images in the dataset, where the sweet spot corresponds to most robust performance across the day and night.
Importance-Aware Semantic Segmentation with Efficient Pyramidal Context Network for Navigational Assistant Systems
Jul 27, 2019
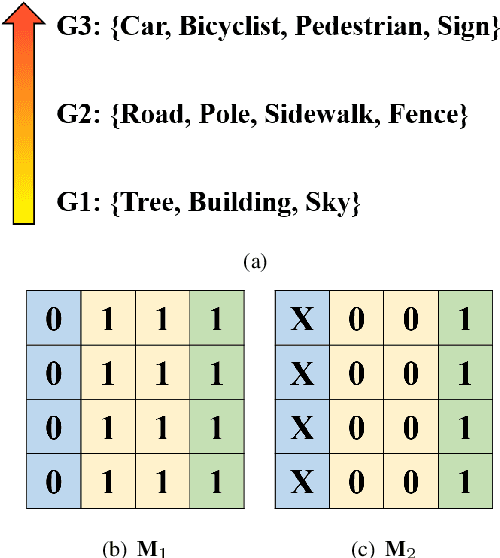
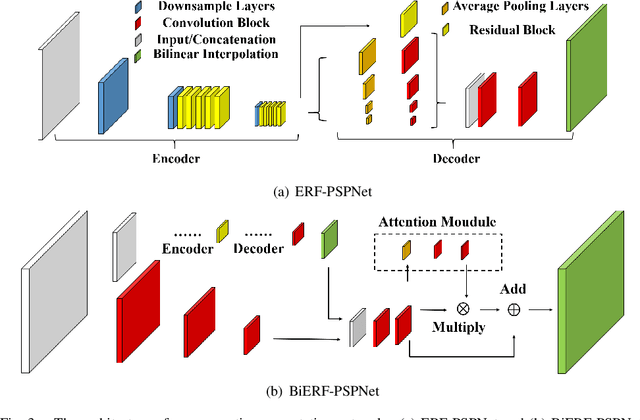

Semantic Segmentation (SS) is a task to assign semantic label to each pixel of the images, which is of immense significance for autonomous vehicles, robotics and assisted navigation of vulnerable road users. It is obvious that in different application scenarios, different objects possess hierarchical importance and safety-relevance, but conventional loss functions like cross entropy have not taken the different levels of importance of diverse traffic elements into consideration. To address this dilemma, we leverage and re-design an importance-aware loss function, throwing insightful hints on how importance of semantics are assigned for real-world applications. To customize semantic segmentation networks for different navigational tasks, we extend ERF-PSPNet, a real-time segmenter designed for wearable device aiding visually impaired pedestrians, and propose BiERF-PSPNet, which can yield high-quality segmentation maps with finer spatial details exceptionally suitable for autonomous vehicles. A comprehensive variety of experiments with these efficient pyramidal context networks on CamVid and Cityscapes datasets demonstrates the effectiveness of our proposal to support diverse navigational assistant systems.
A Comparative Study of High-Recall Real-Time Semantic Segmentation Based on Swift Factorized Network
Jul 26, 2019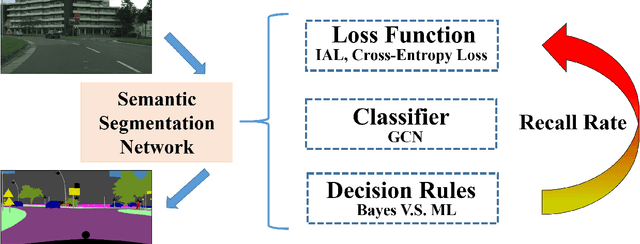
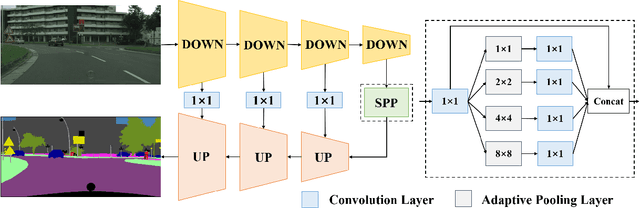
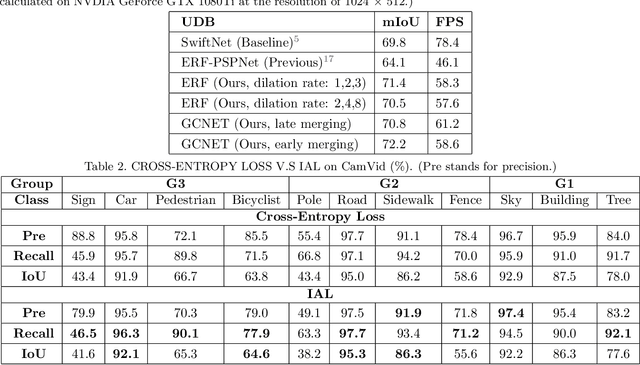
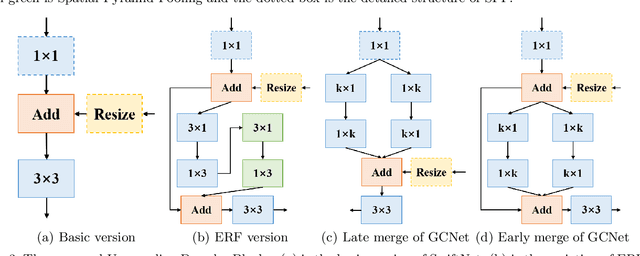
Semantic Segmentation (SS) is the task to assign a semantic label to each pixel of the observed images, which is of crucial significance for autonomous vehicles, navigation assistance systems for the visually impaired, and augmented reality devices. However, there is still a long way for SS to be put into practice as there are two essential challenges that need to be addressed: efficiency and evaluation criterions for practical application. For specific application scenarios, different criterions need to be adopted. Recall rate is an important criterion for many tasks like autonomous vehicles. For autonomous vehicles, we need to focus on the detection of the traffic objects like cars, buses, and pedestrians, which should be detected with high recall rates. In other words, it is preferable to detect it wrongly than miss it, because the other traffic objects will be dangerous if the algorithm miss them and segment them as safe roadways. In this paper, our main goal is to explore possible methods to attain high recall rate. Firstly, we propose a real-time SS network named Swift Factorized Network (SFN). The proposed network is adapted from SwiftNet, whose structure is a typical U-shape structure with lateral connections. Inspired by ERFNet and Global convolution Networks (GCNet), we propose two different blocks to enlarge valid receptive field. They do not take up too much calculation resources, but significantly enhance the performance compared with the baseline network. Secondly, we explore three ways to achieve higher recall rate, i.e. loss function, classifier and decision rules. We perform a comprehensive set of experiments on state-of-the-art datasets including CamVid and Cityscapes. We demonstrate that our SS convolutional neural networks reach excellent performance. Furthermore, we make a detailed analysis and comparison of the three proposed methods on the promotion of recall rate.