 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOPTIAGENT: A Physics-Driven Agentic Framework for Automated Optical Design
Feb 27, 2026Optical design is the process of configuring optical elements to precisely manipulate light for high-fidelity imaging. It is inherently a highly non-convex optimization problem that relies heavily on human heuristic expertise and domain-specific knowledge. While Large Language Models (LLMs) possess extensive optical knowledge, their capabilities in leveraging the knowledge in designing lens system remain significantly constrained. This work represents the first attempt to employ LLMs in the field of optical design. We bridge the expertise gap by enabling users without formal optical training to successfully develop functional lens systems. Concretely, we curate a comprehensive dataset, named OptiDesignQA, which encompasses both classical lens systems sourced from standard optical textbooks and novel configurations generated by automated design algorithms for training and evaluation. Furthermore, we inject domain-specific optical expertise into the LLM through a hybrid objective of full-system synthesis and lens completion. To align the model with optical principles, we employ Group Relative Policy Optimization Done Right (DrGRPO) guided by Optical Lexicographic Reward for physics-driven policy alignment. This reward system incorporates structural format rewards, physical feasibility rewards, light-manipulation accuracy, and LLM-based heuristics. Finally, our model integrates with specialized optical optimization routines for end-to-end fine-tuning and precision refinement. We benchmark our proposed method against both traditional optimization-based automated design algorithms and LLM counterparts, and experimental results show the superiority of our method.
GAT-COBO: Cost-Sensitive Graph Neural Network for Telecom Fraud Detection
Mar 29, 2023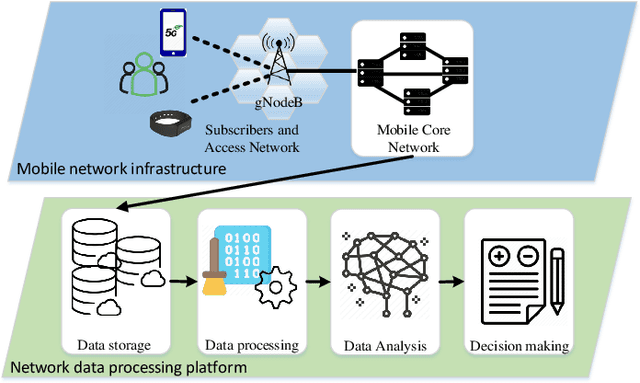



Along with the rapid evolution of mobile communication technologies, such as 5G, there has been a drastically increase in telecom fraud, which significantly dissipates individual fortune and social wealth. In recent years, graph mining techniques are gradually becoming a mainstream solution for detecting telecom fraud. However, the graph imbalance problem, caused by the Pareto principle, brings severe challenges to graph data mining. This is a new and challenging problem, but little previous work has been noticed. In this paper, we propose a Graph ATtention network with COst-sensitive BOosting (GAT-COBO) for the graph imbalance problem. First, we design a GAT-based base classifier to learn the embeddings of all nodes in the graph. Then, we feed the embeddings into a well-designed cost-sensitive learner for imbalanced learning. Next, we update the weights according to the misclassification cost to make the model focus more on the minority class. Finally, we sum the node embeddings obtained by multiple cost-sensitive learners to obtain a comprehensive node representation, which is used for the downstream anomaly detection task. Extensive experiments on two real-world telecom fraud detection datasets demonstrate that our proposed method is effective for the graph imbalance problem, outperforming the state-of-the-art GNNs and GNN-based fraud detectors. In addition, our model is also helpful for solving the widespread over-smoothing problem in GNNs. The GAT-COBO code and datasets are available at https://github.com/xxhu94/GAT-COBO.
Cost Sensitive GNN-based Imbalanced Learning for Mobile Social Network Fraud Detection
Mar 28, 2023



With the rapid development of mobile networks, the people's social contacts have been considerably facilitated. However, the rise of mobile social network fraud upon those networks, has caused a great deal of distress, in case of depleting personal and social wealth, then potentially doing significant economic harm. To detect fraudulent users, call detail record (CDR) data, which portrays the social behavior of users in mobile networks, has been widely utilized. But the imbalance problem in the aforementioned data, which could severely hinder the effectiveness of fraud detectors based on graph neural networks(GNN), has hardly been addressed in previous work. In this paper, we are going to present a novel Cost-Sensitive Graph Neural Network (CSGNN) by creatively combining cost-sensitive learning and graph neural networks. We conduct extensive experiments on two open-source realworld mobile network fraud datasets. The results show that CSGNN can effectively solve the graph imbalance problem and then achieve better detection performance than the state-of-the-art algorithms. We believe that our research can be applied to solve the graph imbalance problems in other fields. The CSGNN code and datasets are publicly available at https://github.com/xxhu94/CSGNN.
CMX: Cross-Modal Fusion for RGB-X Semantic Segmentation with Transformers
Apr 12, 2022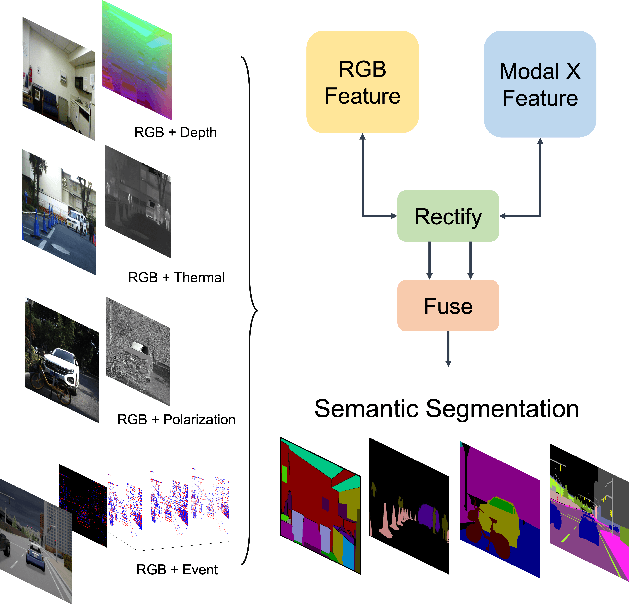
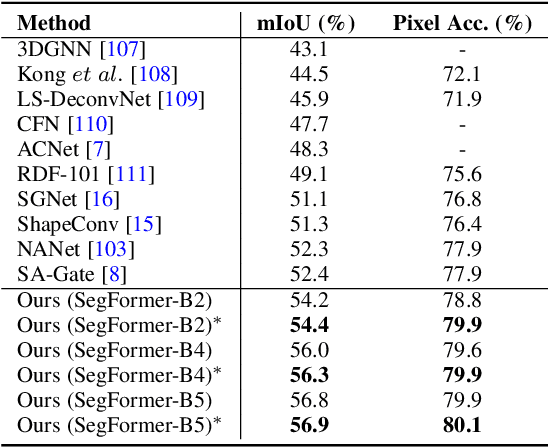
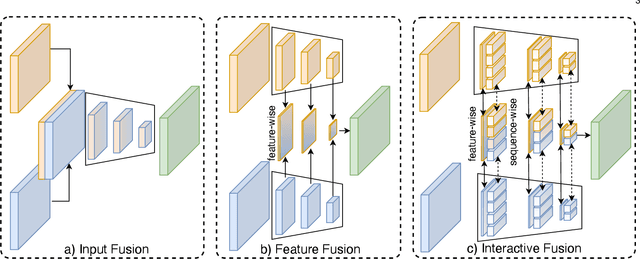
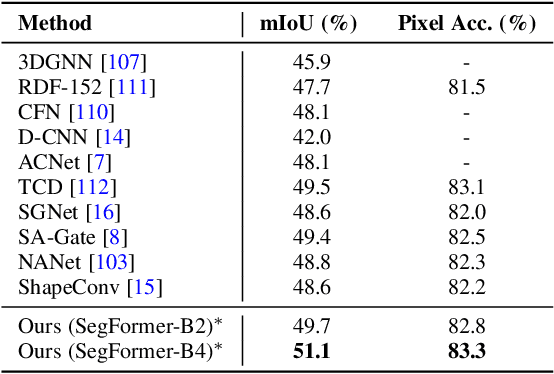
Pixel-wise semantic segmentation of RGB images can be advanced by exploiting informative features from supplementary modalities. In this work, we propose CMX, a vision-transformer-based cross-modal fusion framework for RGB-X semantic segmentation. To generalize to different sensing modalities encompassing various supplements and uncertainties, we consider that comprehensive cross-modal interactions should be provided. CMX is built with two streams to extract features from RGB images and the complementary modality (X-modality). In each feature extraction stage, we design a Cross-Modal Feature Rectification Module (CM-FRM) to calibrate the feature of the current modality by combining the feature from the other modality, in spatial- and channel-wise dimensions. With rectified feature pairs, we deploy a Feature Fusion Module (FFM) to mix them for the final semantic prediction. FFM is constructed with a cross-attention mechanism, which enables exchange of long-range contexts, enhancing both modalities' features at a global level. Extensive experiments show that CMX generalizes to diverse multi-modal combinations, achieving state-of-the-art performances on five RGB-Depth benchmarks, as well as RGB-Thermal and RGB-Polarization datasets. Besides, to investigate the generalizability to dense-sparse data fusion, we establish an RGB-Event semantic segmentation benchmark based on the EventScape dataset, on which CMX sets the new state-of-the-art. Code is available at https://github.com/huaaaliu/RGBX_Semantic_Segmentation.
Capturing Omni-Range Context for Omnidirectional Segmentation
Mar 09, 2021
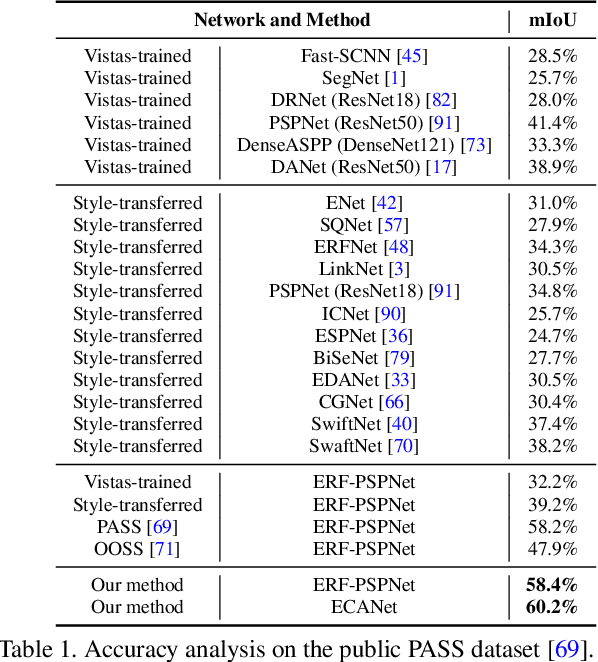

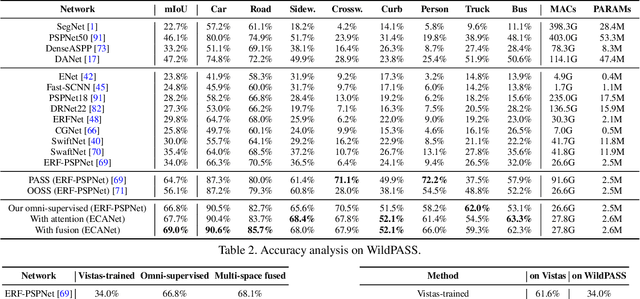
Convolutional Networks (ConvNets) excel at semantic segmentation and have become a vital component for perception in autonomous driving. Enabling an all-encompassing view of street-scenes, omnidirectional cameras present themselves as a perfect fit in such systems. Most segmentation models for parsing urban environments operate on common, narrow Field of View (FoV) images. Transferring these models from the domain they were designed for to 360-degree perception, their performance drops dramatically, e.g., by an absolute 30.0% (mIoU) on established test-beds. To bridge the gap in terms of FoV and structural distribution between the imaging domains, we introduce Efficient Concurrent Attention Networks (ECANets), directly capturing the inherent long-range dependencies in omnidirectional imagery. In addition to the learned attention-based contextual priors that can stretch across 360-degree images, we upgrade model training by leveraging multi-source and omni-supervised learning, taking advantage of both: Densely labeled and unlabeled data originating from multiple datasets. To foster progress in panoramic image segmentation, we put forward and extensively evaluate models on Wild PAnoramic Semantic Segmentation (WildPASS), a dataset designed to capture diverse scenes from all around the globe. Our novel model, training regimen and multi-source prediction fusion elevate the performance (mIoU) to new state-of-the-art results on the public PASS (60.2%) and the fresh WildPASS (69.0%) benchmarks.
Real-time Fusion Network for RGB-D Semantic Segmentation Incorporating Unexpected Obstacle Detection for Road-driving Images
Feb 24, 2020
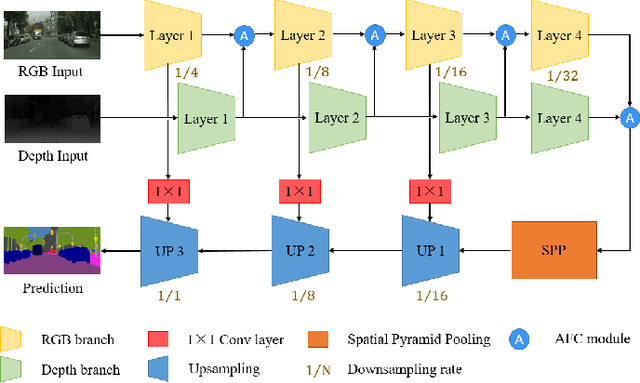

Semantic segmentation has made striking progress due to the success of deep convolutional neural networks. Considering the demand of autonomous driving, real-time semantic segmentation has become a research hotspot these years. However, few real-time RGB-D fusion semantic segmentation studies are carried out despite readily accessible depth information nowadays. In this paper, we propose a real-time fusion semantic segmentation network termed RFNet that efficiently exploits complementary features from depth information to enhance the performance in an attention-augmented way, while running swiftly that is a necessity for autonomous vehicles applications. Multi-dataset training is leveraged to incorporate unexpected small obstacle detection, enriching the recognizable classes required to face unforeseen hazards in the real world. A comprehensive set of experiments demonstrates the effectiveness of our framework. On \textit{Cityscapes}, Our method outperforms previous state-of-the-art semantic segmenters, with excellent accuracy and 22Hz inference speed at the full 2048$\times$1024 resolution, outperforming most existing RGB-D networks.
DS-PASS: Detail-Sensitive Panoramic Annular Semantic Segmentation through SwaftNet for Surrounding Sensing
Sep 17, 2019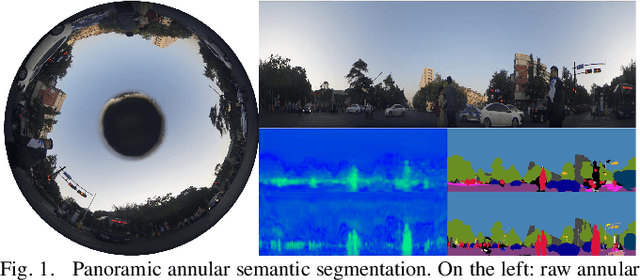
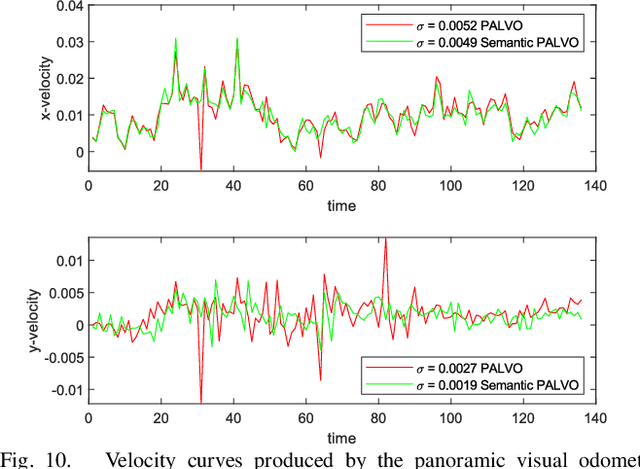
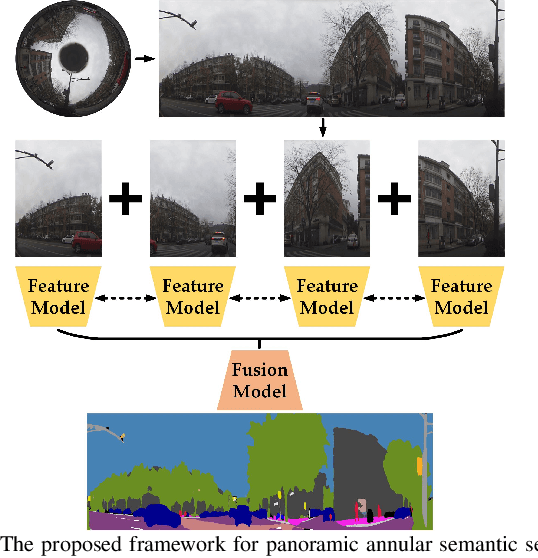
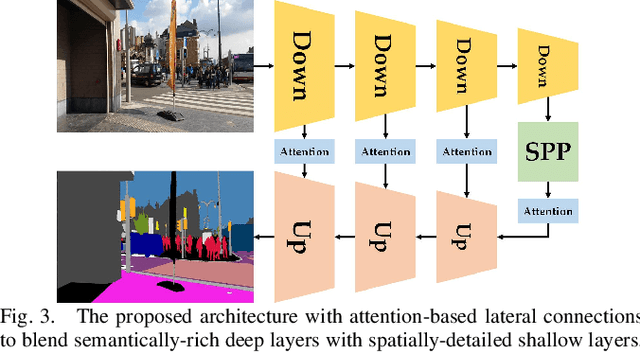
Semantically interpreting the traffic scene is crucial for autonomous transportation and robotics. However, state-of-the-art semantic segmentation pipelines are dominantly designed to work with pinhole cameras and train with narrow Field-of-View (FoV) images. In this sense, the perception capacity is severely limited to offer higher-level of confidence for upstream navigation tasks. In this paper, we propose a network adaptation framework to achieve Panoramic Annular Semantic Segmentation (PASS), which allows to re-use conventional pinhole-view image datasets, enabling modern segmentation networks to comfortably adapt to panoramic images. Specifically, we adapt our proposed SwaftNet to enhance the sensitivity to details by implementing attention-based lateral connections between the detail-critical encoder layers and the context-critical decoder layers. We benchmark the performance of efficient segmenters on panoramic segmentation with our extended PASS dataset, demonstrating that the proposed real-time SwaftNet outperforms state-of-the-art efficient networks. Furthermore, we assess real-world performance when deploying the Detail-Sensitive PASS (DS-PASS) system on a mobile robot and an instrumented vehicle, as well as the benefit of panoramic semantics for visual odometry, showing the robustness and potential to support diverse navigational applications.
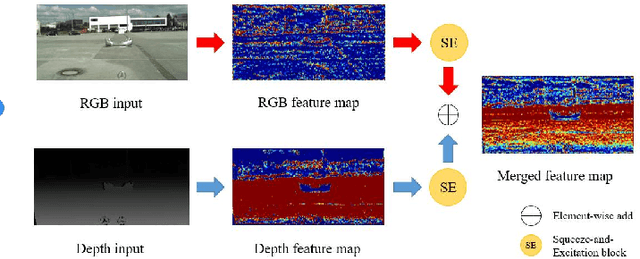
ACNet: Attention Based Network to Exploit Complementary Features for RGBD Semantic Segmentation
May 24, 2019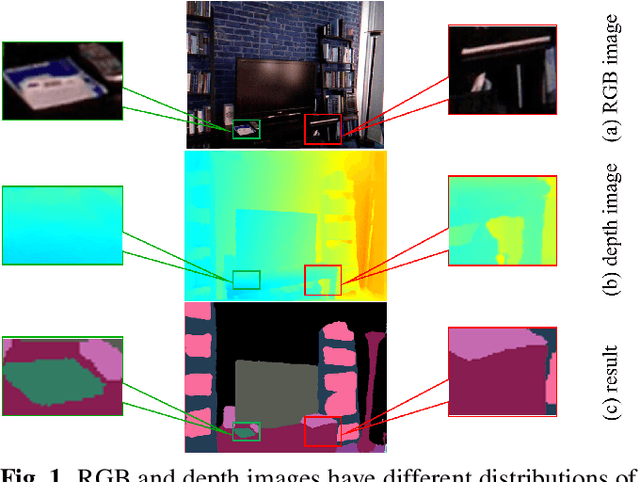
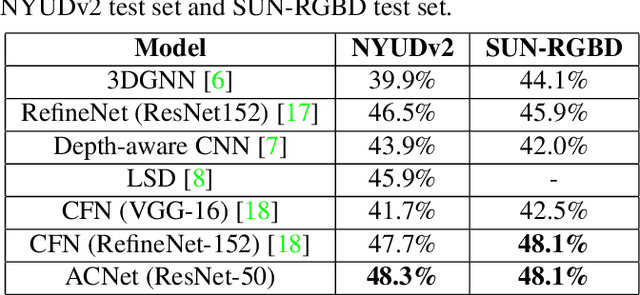
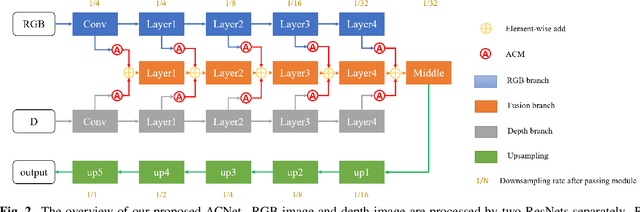
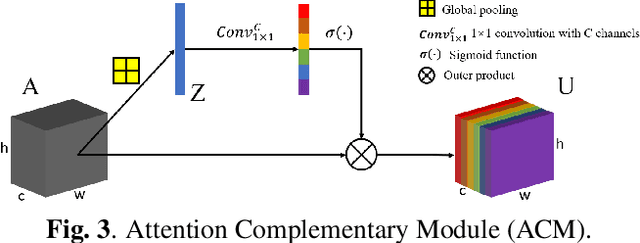
Compared to RGB semantic segmentation, RGBD semantic segmentation can achieve better performance by taking depth information into consideration. However, it is still problematic for contemporary segmenters to effectively exploit RGBD information since the feature distributions of RGB and depth (D) images vary significantly in different scenes. In this paper, we propose an Attention Complementary Network (ACNet) that selectively gathers features from RGB and depth branches. The main contributions lie in the Attention Complementary Module (ACM) and the architecture with three parallel branches. More precisely, ACM is a channel attention-based module that extracts weighted features from RGB and depth branches. The architecture preserves the inference of the original RGB and depth branches, and enables the fusion branch at the same time. Based on the above structures, ACNet is capable of exploiting more high-quality features from different channels. We evaluate our model on SUN-RGBD and NYUDv2 datasets, and prove that our model outperforms state-of-the-art methods. In particular, a mIoU score of 48.3\% on NYUDv2 test set is achieved with ResNet50. We will release our source code based on PyTorch and the trained segmentation model at https://github.com/anheidelonghu/ACNet.