 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogics-Parsing-Omni Technical Report
Mar 12, 2026Addressing the challenges of fragmented task definitions and the heterogeneity of unstructured data in multimodal parsing, this paper proposes the Omni Parsing framework. This framework establishes a Unified Taxonomy covering documents, images, and audio-visual streams, introducing a progressive parsing paradigm that bridges perception and cognition. Specifically, the framework integrates three hierarchical levels: 1) Holistic Detection, which achieves precise spatial-temporal grounding of objects or events to establish a geometric baseline for perception; 2) Fine-grained Recognition, which performs symbolization (e.g., OCR/ASR) and attribute extraction on localized objects to complete structured entity parsing; and 3) Multi-level Interpreting, which constructs a reasoning chain from local semantics to global logic. A pivotal advantage of this framework is its evidence anchoring mechanism, which enforces a strict alignment between high-level semantic descriptions and low-level facts. This enables ``evidence-based'' logical induction, transforming unstructured signals into standardized knowledge that is locatable, enumerable, and traceable. Building on this foundation, we constructed a standardized dataset and released the Logics-Parsing-Omni model, which successfully converts complex audio-visual signals into machine-readable structured knowledge. Experiments demonstrate that fine-grained perception and high-level cognition are synergistic, effectively enhancing model reliability. Furthermore, to quantitatively evaluate these capabilities, we introduce OmniParsingBench. Code, models and the benchmark are released at https://github.com/alibaba/Logics-Parsing/tree/master/Logics-Parsing-Omni.
CMX: Cross-Modal Fusion for RGB-X Semantic Segmentation with Transformers
Apr 12, 2022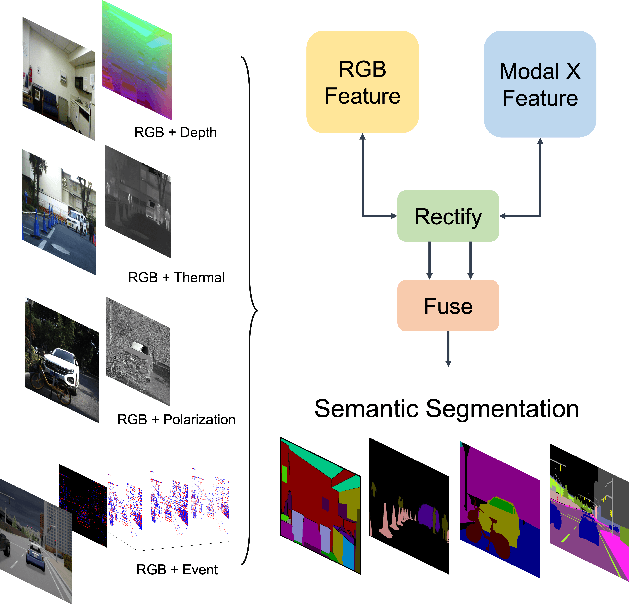
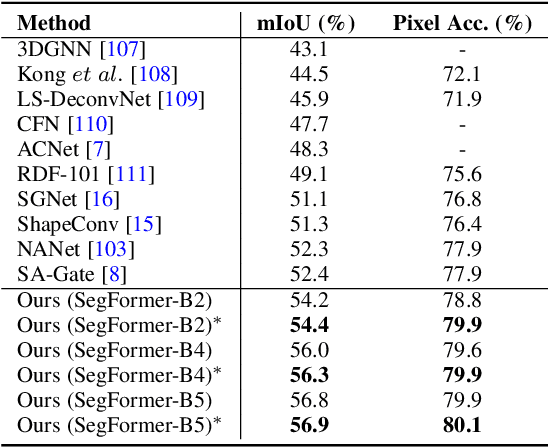
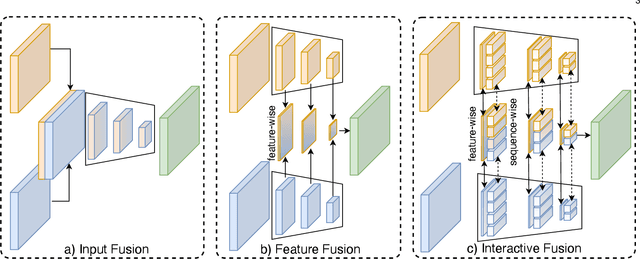
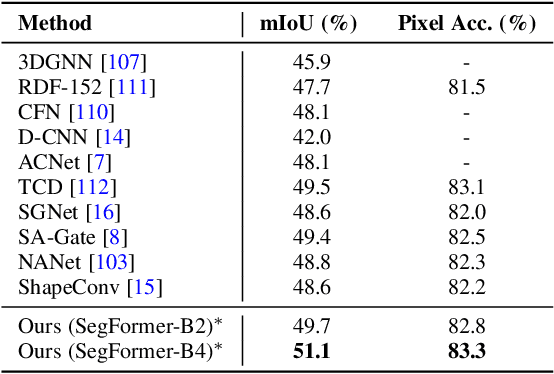
Pixel-wise semantic segmentation of RGB images can be advanced by exploiting informative features from supplementary modalities. In this work, we propose CMX, a vision-transformer-based cross-modal fusion framework for RGB-X semantic segmentation. To generalize to different sensing modalities encompassing various supplements and uncertainties, we consider that comprehensive cross-modal interactions should be provided. CMX is built with two streams to extract features from RGB images and the complementary modality (X-modality). In each feature extraction stage, we design a Cross-Modal Feature Rectification Module (CM-FRM) to calibrate the feature of the current modality by combining the feature from the other modality, in spatial- and channel-wise dimensions. With rectified feature pairs, we deploy a Feature Fusion Module (FFM) to mix them for the final semantic prediction. FFM is constructed with a cross-attention mechanism, which enables exchange of long-range contexts, enhancing both modalities' features at a global level. Extensive experiments show that CMX generalizes to diverse multi-modal combinations, achieving state-of-the-art performances on five RGB-Depth benchmarks, as well as RGB-Thermal and RGB-Polarization datasets. Besides, to investigate the generalizability to dense-sparse data fusion, we establish an RGB-Event semantic segmentation benchmark based on the EventScape dataset, on which CMX sets the new state-of-the-art. Code is available at https://github.com/huaaaliu/RGBX_Semantic_Segmentation.
Transformer-based Knowledge Distillation for Efficient Semantic Segmentation of Road-driving Scenes
Feb 27, 2022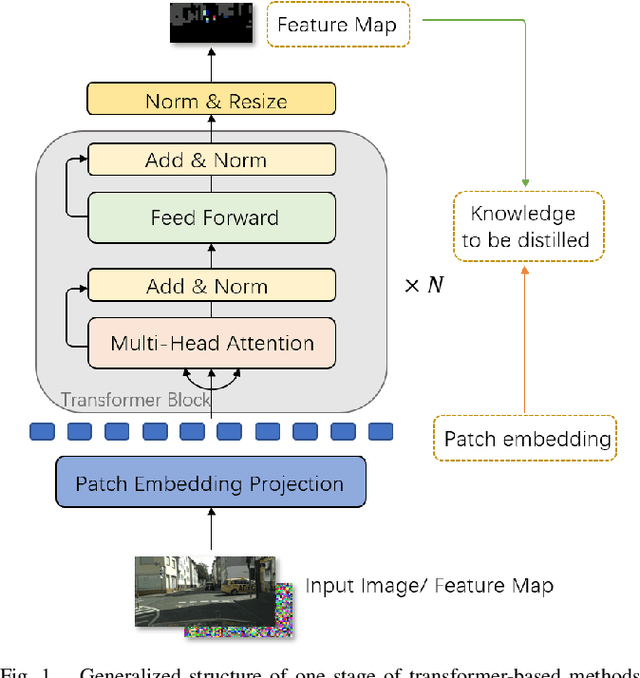
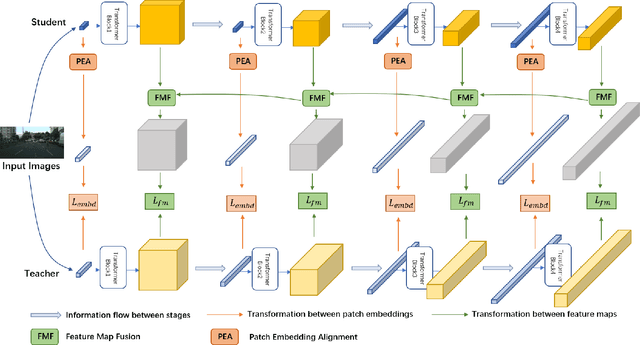
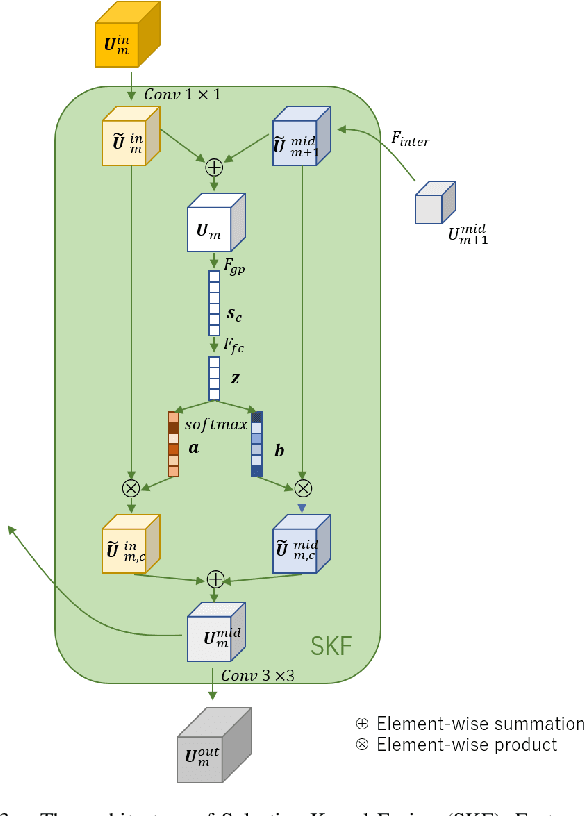
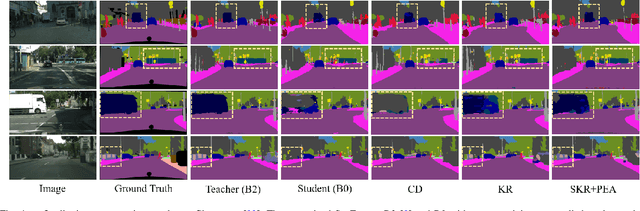
For scene understanding in robotics and automated driving, there is a growing interest in solving semantic segmentation tasks with transformer-based methods. However, effective transformers are always too cumbersome and computationally expensive to solve semantic segmentation in real time, which is desired for robotic systems. Moreover, due to the lack of inductive biases compared to Convolutional Neural Networks (CNNs), pre-training on a large dataset is essential but it takes a long time. Knowledge Distillation (KD) speeds up inference and maintains accuracy while transferring knowledge from a pre-trained cumbersome teacher model to a compact student model. Most traditional KD methods for CNNs focus on response-based knowledge and feature-based knowledge. In contrast, we present a novel KD framework according to the nature of transformers, i.e., training compact transformers by transferring the knowledge from feature maps and patch embeddings of large transformers. To this purpose, two modules are proposed: (1) the Selective Kernel Fusion (SKF) module, which helps to construct an efficient relation-based KD framework, Selective Kernel Review (SKR); (2) the Patch Embedding Alignment (PEA) module, which performs the dimensional transformation of patch embeddings. The combined KD framework is called SKR+PEA. Through comprehensive experiments on Cityscapes and ACDC datasets, it indicates that our proposed approach outperforms recent state-of-the-art KD frameworks and rivals the time-consuming pre-training method. Code will be made publicly available at https://github.com/RuipingL/SKR_PEA.git
HIDA: Towards Holistic Indoor Understanding for the Visually Impaired via Semantic Instance Segmentation with a Wearable Solid-State LiDAR Sensor
Jul 07, 2021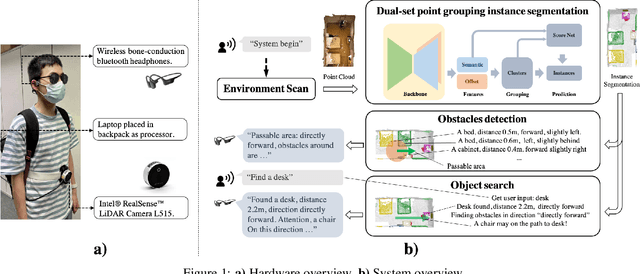
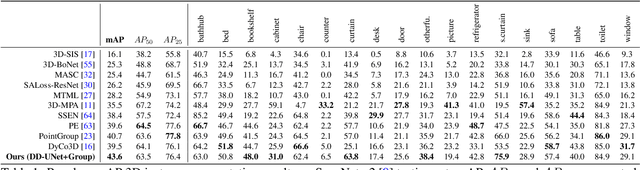

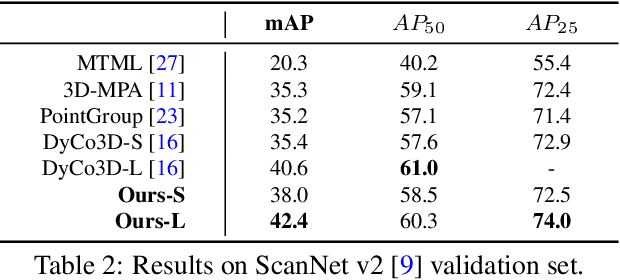
Independently exploring unknown spaces or finding objects in an indoor environment is a daily but challenging task for visually impaired people. However, common 2D assistive systems lack depth relationships between various objects, resulting in difficulty to obtain accurate spatial layout and relative positions of objects. To tackle these issues, we propose HIDA, a lightweight assistive system based on 3D point cloud instance segmentation with a solid-state LiDAR sensor, for holistic indoor detection and avoidance. Our entire system consists of three hardware components, two interactive functions~(obstacle avoidance and object finding) and a voice user interface. Based on voice guidance, the point cloud from the most recent state of the changing indoor environment is captured through an on-site scanning performed by the user. In addition, we design a point cloud segmentation model with dual lightweight decoders for semantic and offset predictions, which satisfies the efficiency of the whole system. After the 3D instance segmentation, we post-process the segmented point cloud by removing outliers and projecting all points onto a top-view 2D map representation. The system integrates the information above and interacts with users intuitively by acoustic feedback. The proposed 3D instance segmentation model has achieved state-of-the-art performance on ScanNet v2 dataset. Comprehensive field tests with various tasks in a user study verify the usability and effectiveness of our system for assisting visually impaired people in holistic indoor understanding, obstacle avoidance and object search.