 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCMX: Cross-Modal Fusion for RGB-X Semantic Segmentation with Transformers
Paper and Code
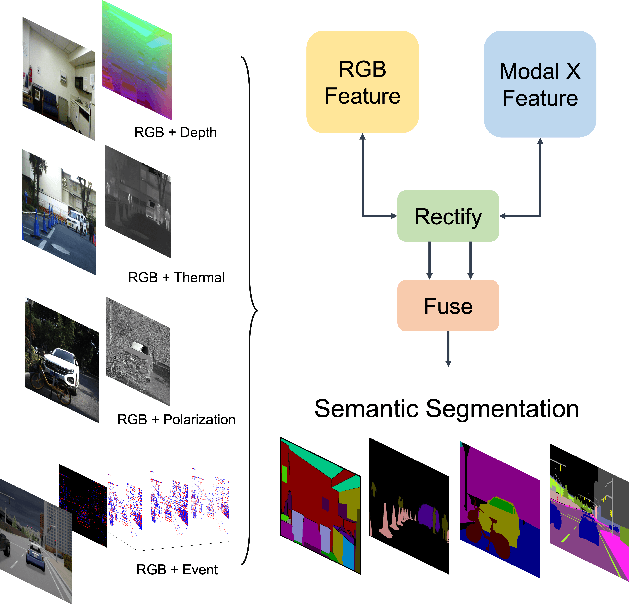
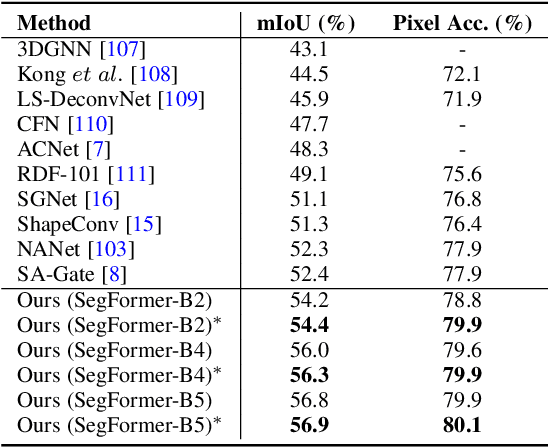
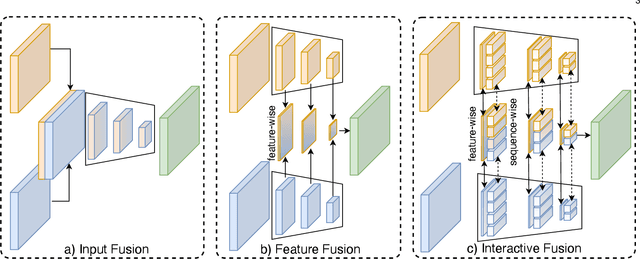
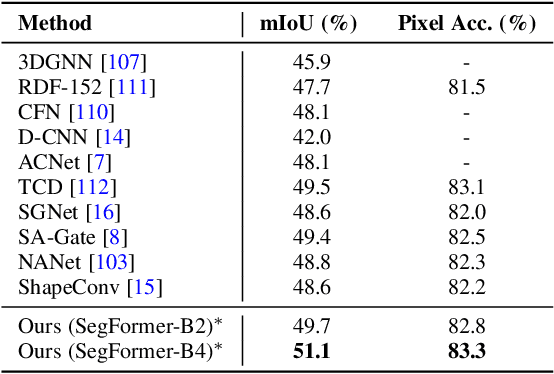
Pixel-wise semantic segmentation of RGB images can be advanced by exploiting informative features from supplementary modalities. In this work, we propose CMX, a vision-transformer-based cross-modal fusion framework for RGB-X semantic segmentation. To generalize to different sensing modalities encompassing various supplements and uncertainties, we consider that comprehensive cross-modal interactions should be provided. CMX is built with two streams to extract features from RGB images and the complementary modality (X-modality). In each feature extraction stage, we design a Cross-Modal Feature Rectification Module (CM-FRM) to calibrate the feature of the current modality by combining the feature from the other modality, in spatial- and channel-wise dimensions. With rectified feature pairs, we deploy a Feature Fusion Module (FFM) to mix them for the final semantic prediction. FFM is constructed with a cross-attention mechanism, which enables exchange of long-range contexts, enhancing both modalities' features at a global level. Extensive experiments show that CMX generalizes to diverse multi-modal combinations, achieving state-of-the-art performances on five RGB-Depth benchmarks, as well as RGB-Thermal and RGB-Polarization datasets. Besides, to investigate the generalizability to dense-sparse data fusion, we establish an RGB-Event semantic segmentation benchmark based on the EventScape dataset, on which CMX sets the new state-of-the-art. Code is available at https://github.com/huaaaliu/RGBX_Semantic_Segmentation.