 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNano-EmoX: Unifying Multimodal Emotional Intelligence from Perception to Empathy
Mar 03, 2026The development of affective multimodal language models (MLMs) has long been constrained by a gap between low-level perception and high-level interaction, leading to fragmented affective capabilities and limited generalization. To bridge this gap, we propose a cognitively inspired three-level hierarchy that organizes affective tasks according to their cognitive depth-perception, understanding, and interaction-and provides a unified conceptual foundation for advancing affective modeling. Guided by this hierarchy, we introduce Nano-EmoX, a small-scale multitask MLM, and P2E (Perception-to-Empathy), a curriculum-based training framework. Nano-EmoX integrates a suite of omni-modal encoders, including an enhanced facial encoder and a fusion encoder, to capture key multimodal affective cues and improve cross-task transferability. The outputs are projected into a unified language space via heterogeneous adapters, empowering a lightweight language model to tackle diverse affective tasks. Concurrently, P2E progressively cultivates emotional intelligence by aligning rapid perception with chain-of-thought-driven empathy. To the best of our knowledge, Nano-EmoX is the first compact MLM (2.2B) to unify six core affective tasks across all three hierarchy levels, achieving state-of-the-art or highly competitive performance across multiple benchmarks, demonstrating excellent efficiency and generalization.
Unlabeled Action Quality Assessment Based on Multi-dimensional Adaptive Constrained Dynamic Time Warping
Oct 18, 2024
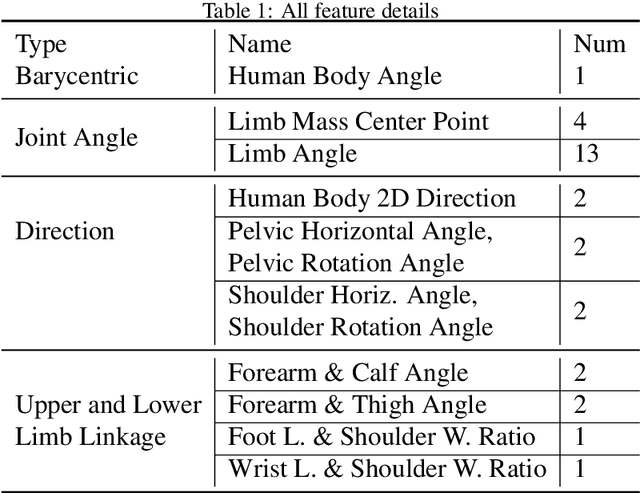
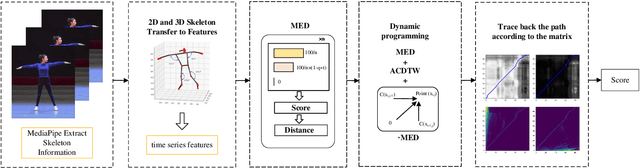
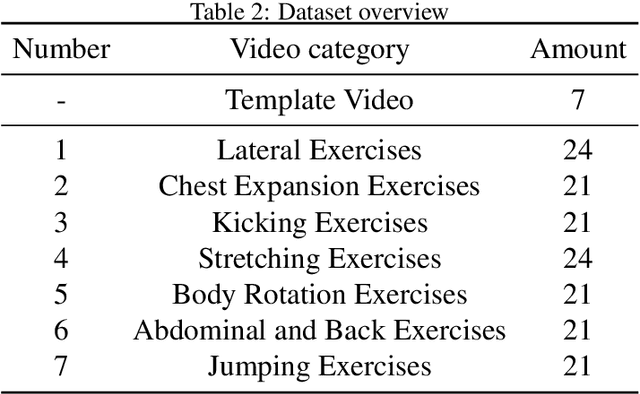
The growing popularity of online sports and exercise necessitates effective methods for evaluating the quality of online exercise executions. Previous action quality assessment methods, which relied on labeled scores from motion videos, exhibited slightly lower accuracy and discriminability. This limitation hindered their rapid application to newly added exercises. To address this problem, this paper presents an unlabeled Multi-Dimensional Exercise Distance Adaptive Constrained Dynamic Time Warping (MED-ACDTW) method for action quality assessment. Our approach uses an athletic version of DTW to compare features from template and test videos, eliminating the need for score labels during training. The result shows that utilizing both 2D and 3D spatial dimensions, along with multiple human body features, improves the accuracy by 2-3% compared to using either 2D or 3D pose estimation alone. Additionally, employing MED for score calculation enhances the precision of frame distance matching, which significantly boosts overall discriminability. The adaptive constraint scheme enhances the discriminability of action quality assessment by approximately 30%. Furthermore, to address the absence of a standardized perspective in sports class evaluations, we introduce a new dataset called BGym.
Boosting Generalization with Adaptive Style Techniques for Fingerprint Liveness Detection
Oct 24, 2023



We introduce a high-performance fingerprint liveness feature extraction technique that secured first place in LivDet 2023 Fingerprint Representation Challenge. Additionally, we developed a practical fingerprint recognition system with 94.68% accuracy, earning second place in LivDet 2023 Liveness Detection in Action. By investigating various methods, particularly style transfer, we demonstrate improvements in accuracy and generalization when faced with limited training data. As a result, our approach achieved state-of-the-art performance in LivDet 2023 Challenges.
Symbolic & Acoustic: Multi-domain Music Emotion Modeling for Instrumental Music
Aug 28, 2023



Music Emotion Recognition involves the automatic identification of emotional elements within music tracks, and it has garnered significant attention due to its broad applicability in the field of Music Information Retrieval. It can also be used as the upstream task of many other human-related tasks such as emotional music generation and music recommendation. Due to existing psychology research, music emotion is determined by multiple factors such as the Timbre, Velocity, and Structure of the music. Incorporating multiple factors in MER helps achieve more interpretable and finer-grained methods. However, most prior works were uni-domain and showed weak consistency between arousal modeling performance and valence modeling performance. Based on this background, we designed a multi-domain emotion modeling method for instrumental music that combines symbolic analysis and acoustic analysis. At the same time, because of the rarity of music data and the difficulty of labeling, our multi-domain approach can make full use of limited data. Our approach was implemented and assessed using the publicly available piano dataset EMOPIA, resulting in a notable improvement over our baseline model with a 2.4% increase in overall accuracy, establishing its state-of-the-art performance.
Improving EEG-based Emotion Recognition by Fusing Time-frequency And Spatial Representations
Mar 14, 2023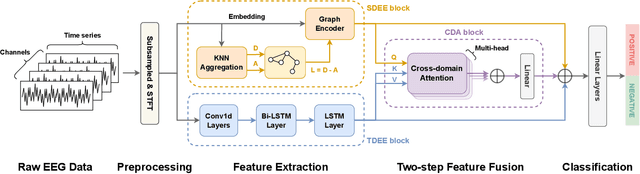
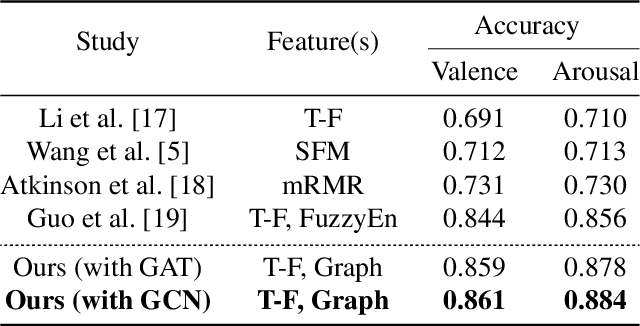

Using deep learning methods to classify EEG signals can accurately identify people's emotions. However, existing studies have rarely considered the application of the information in another domain's representations to feature selection in the time-frequency domain. We propose a classification network of EEG signals based on the cross-domain feature fusion method, which makes the network more focused on the features most related to brain activities and thinking changes by using the multi-domain attention mechanism. In addition, we propose a two-step fusion method and apply these methods to the EEG emotion recognition network. Experimental results show that our proposed network, which combines multiple representations in the time-frequency domain and spatial domain, outperforms previous methods on public datasets and achieves state-of-the-art at present.
Improving Speech Representation Learning via Speech-level and Phoneme-level Masking Approach
Oct 25, 2022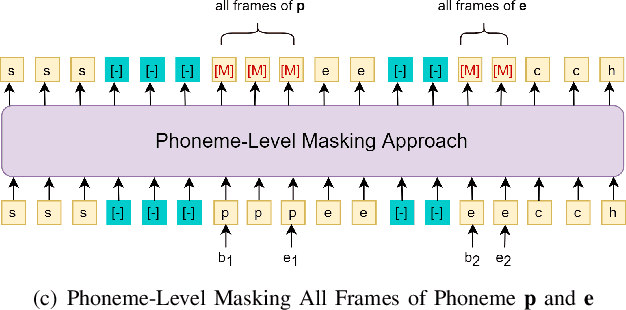
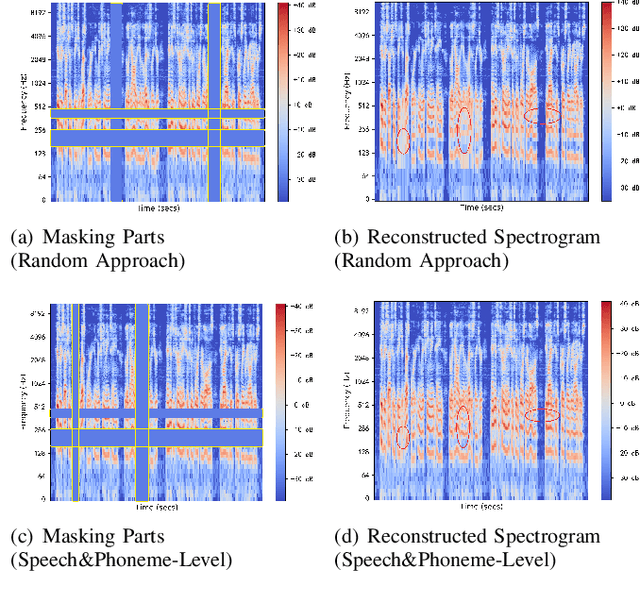

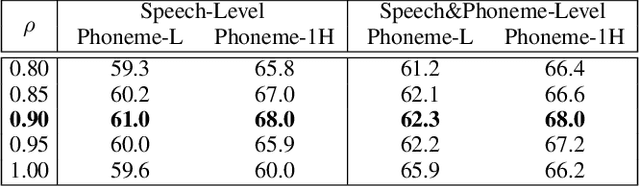
Recovering the masked speech frames is widely applied in speech representation learning. However, most of these models use random masking in the pre-training. In this work, we proposed two kinds of masking approaches: (1) speech-level masking, making the model to mask more speech segments than silence segments, (2) phoneme-level masking, forcing the model to mask the whole frames of the phoneme, instead of phoneme pieces. We pre-trained the model via these two approaches, and evaluated on two downstream tasks, phoneme classification and speaker recognition. The experiments demonstrated that the proposed masking approaches are beneficial to improve the performance of speech representation.