Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Speech Representation Learning via Speech-level and Phoneme-level Masking Approach
Paper and Code
Oct 25, 2022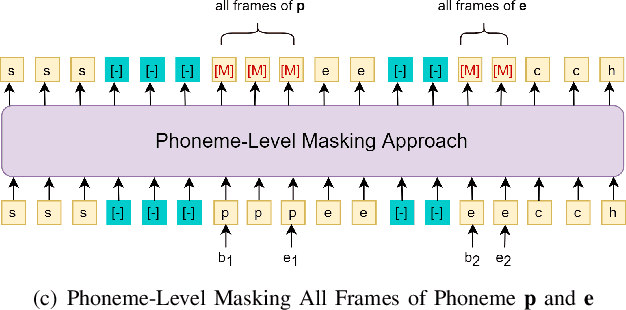
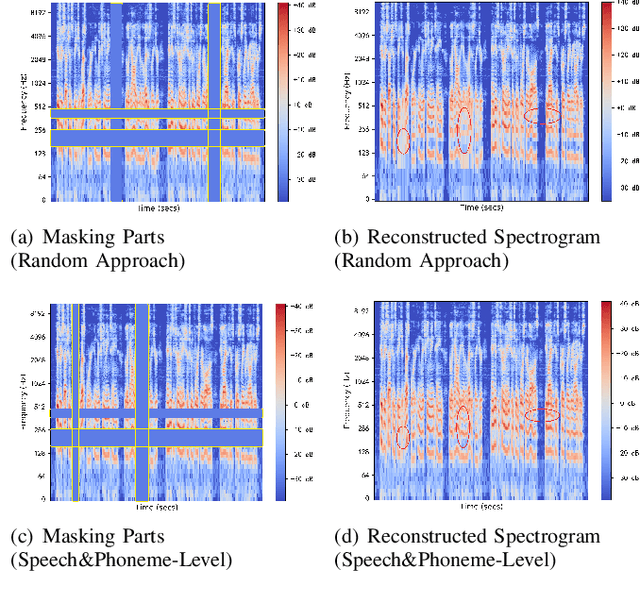

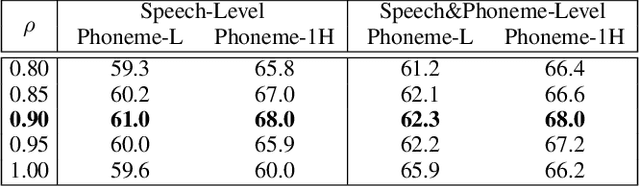
Recovering the masked speech frames is widely applied in speech representation learning. However, most of these models use random masking in the pre-training. In this work, we proposed two kinds of masking approaches: (1) speech-level masking, making the model to mask more speech segments than silence segments, (2) phoneme-level masking, forcing the model to mask the whole frames of the phoneme, instead of phoneme pieces. We pre-trained the model via these two approaches, and evaluated on two downstream tasks, phoneme classification and speaker recognition. The experiments demonstrated that the proposed masking approaches are beneficial to improve the performance of speech representation.
* Accepted by MSN2022, The 18th International Conference on Mobility,
Sensing and Networking
View paper on