 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarks and Challenges in Pose Estimation for Egocentric Hand Interactions with Objects
Mar 25, 2024
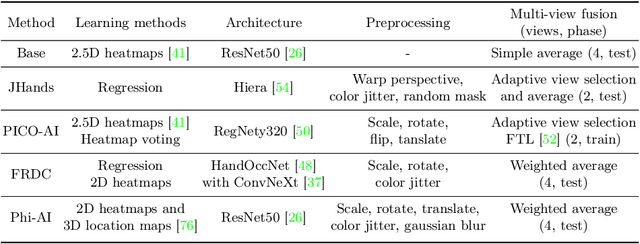
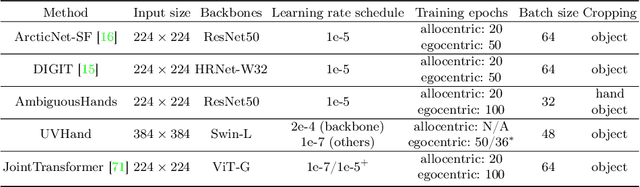
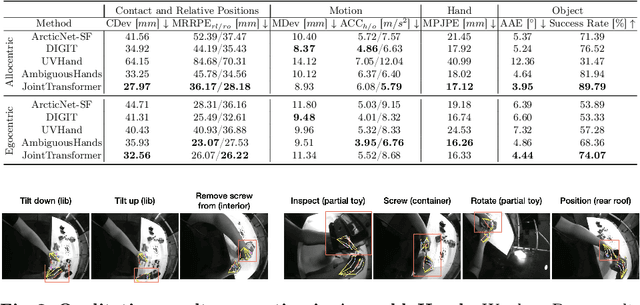
We interact with the world with our hands and see it through our own (egocentric) perspective. A holistic 3D understanding of such interactions from egocentric views is important for tasks in robotics, AR/VR, action recognition and motion generation. Accurately reconstructing such interactions in 3D is challenging due to heavy occlusion, viewpoint bias, camera distortion, and motion blur from the head movement. To this end, we designed the HANDS23 challenge based on the AssemblyHands and ARCTIC datasets with carefully designed training and testing splits. Based on the results of the top submitted methods and more recent baselines on the leaderboards, we perform a thorough analysis on 3D hand(-object) reconstruction tasks. Our analysis demonstrates the effectiveness of addressing distortion specific to egocentric cameras, adopting high-capacity transformers to learn complex hand-object interactions, and fusing predictions from different views. Our study further reveals challenging scenarios intractable with state-of-the-art methods, such as fast hand motion, object reconstruction from narrow egocentric views, and close contact between two hands and objects. Our efforts will enrich the community's knowledge foundation and facilitate future hand studies on egocentric hand-object interactions.
A Simple Baseline for Efficient Hand Mesh Reconstruction
Mar 04, 2024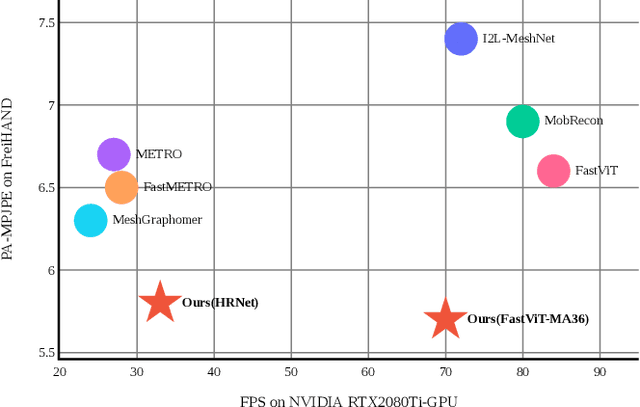
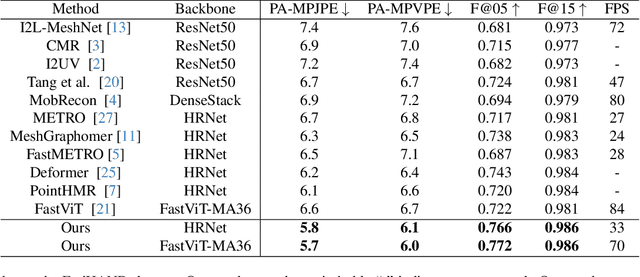
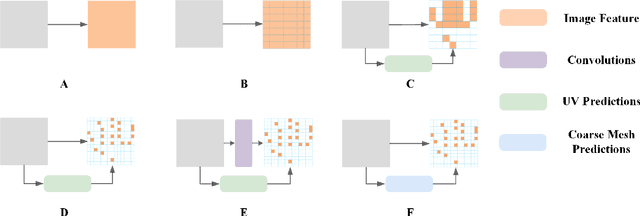
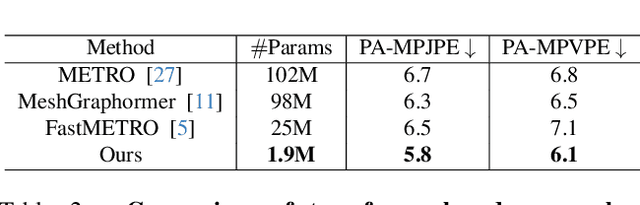
3D hand pose estimation has found broad application in areas such as gesture recognition and human-machine interaction tasks. As performance improves, the complexity of the systems also increases, which can limit the comparative analysis and practical implementation of these methods. In this paper, we propose a simple yet effective baseline that not only surpasses state-of-the-art (SOTA) methods but also demonstrates computational efficiency. To establish this baseline, we abstract existing work into two components: a token generator and a mesh regressor, and then examine their core structures. A core structure, in this context, is one that fulfills intrinsic functions, brings about significant improvements, and achieves excellent performance without unnecessary complexities. Our proposed approach is decoupled from any modifications to the backbone, making it adaptable to any modern models. Our method outperforms existing solutions, achieving state-of-the-art (SOTA) results across multiple datasets. On the FreiHAND dataset, our approach produced a PA-MPJPE of 5.7mm and a PA-MPVPE of 6.0mm. Similarly, on the Dexycb dataset, we observed a PA-MPJPE of 5.5mm and a PA-MPVPE of 5.0mm. As for performance speed, our method reached up to 33 frames per second (fps) when using HRNet and up to 70 fps when employing FastViT-MA36
1st Place Solution of Egocentric 3D Hand Pose Estimation Challenge 2023 Technical Report:A Concise Pipeline for Egocentric Hand Pose Reconstruction
Oct 10, 2023

This report introduce our work on Egocentric 3D Hand Pose Estimation workshop. Using AssemblyHands, this challenge focuses on egocentric 3D hand pose estimation from a single-view image. In the competition, we adopt ViT based backbones and a simple regressor for 3D keypoints prediction, which provides strong model baselines. We noticed that Hand-objects occlusions and self-occlusions lead to performance degradation, thus proposed a non-model method to merge multi-view results in the post-process stage. Moreover, We utilized test time augmentation and model ensemble to make further improvement. We also found that public dataset and rational preprocess are beneficial. Our method achieved 12.21mm MPJPE on test dataset, achieve the first place in Egocentric 3D Hand Pose Estimation challenge.