 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarks and Challenges in Pose Estimation for Egocentric Hand Interactions with Objects
Mar 25, 2024
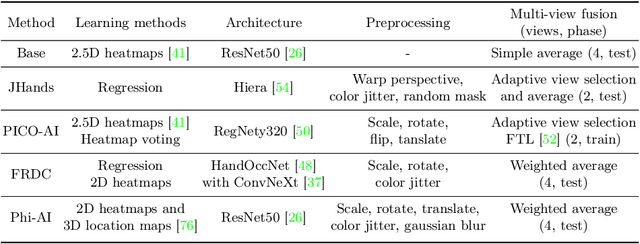
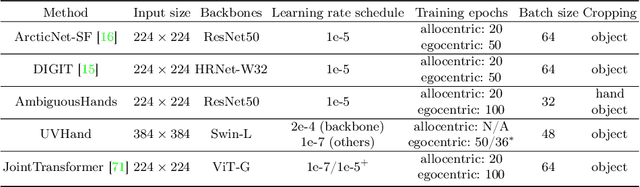
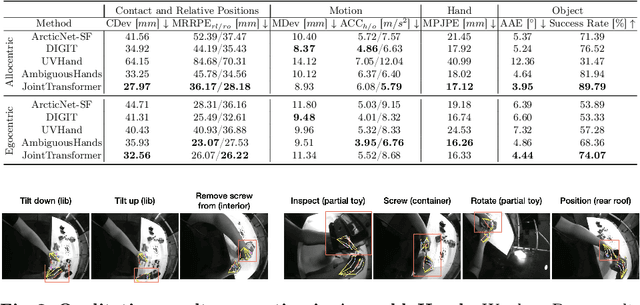
We interact with the world with our hands and see it through our own (egocentric) perspective. A holistic 3D understanding of such interactions from egocentric views is important for tasks in robotics, AR/VR, action recognition and motion generation. Accurately reconstructing such interactions in 3D is challenging due to heavy occlusion, viewpoint bias, camera distortion, and motion blur from the head movement. To this end, we designed the HANDS23 challenge based on the AssemblyHands and ARCTIC datasets with carefully designed training and testing splits. Based on the results of the top submitted methods and more recent baselines on the leaderboards, we perform a thorough analysis on 3D hand(-object) reconstruction tasks. Our analysis demonstrates the effectiveness of addressing distortion specific to egocentric cameras, adopting high-capacity transformers to learn complex hand-object interactions, and fusing predictions from different views. Our study further reveals challenging scenarios intractable with state-of-the-art methods, such as fast hand motion, object reconstruction from narrow egocentric views, and close contact between two hands and objects. Our efforts will enrich the community's knowledge foundation and facilitate future hand studies on egocentric hand-object interactions.
MonoRUn: Monocular 3D Object Detection by Reconstruction and Uncertainty Propagation
Mar 24, 2021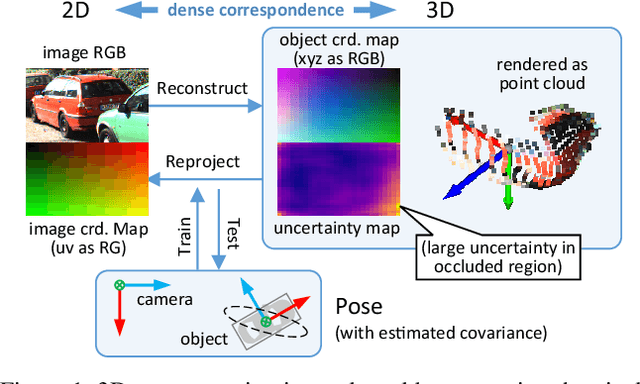
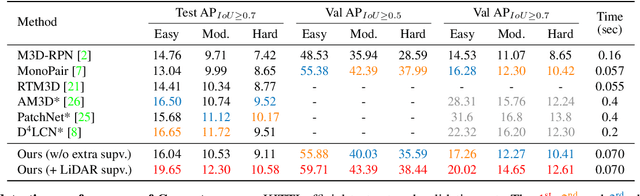
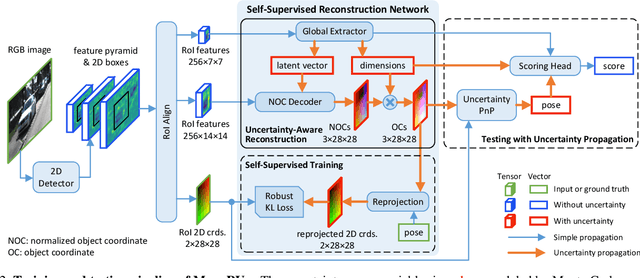
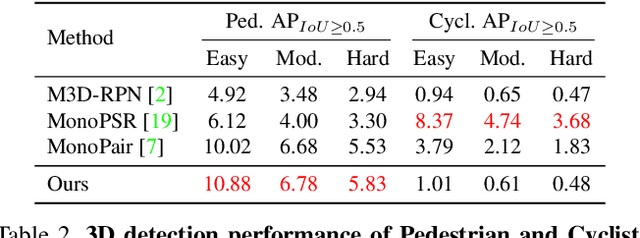
Object localization in 3D space is a challenging aspect in monocular 3D object detection. Recent advances in 6DoF pose estimation have shown that predicting dense 2D-3D correspondence maps between image and object 3D model and then estimating object pose via Perspective-n-Point (PnP) algorithm can achieve remarkable localization accuracy. Yet these methods rely on training with ground truth of object geometry, which is difficult to acquire in real outdoor scenes. To address this issue, we propose MonoRUn, a novel detection framework that learns dense correspondences and geometry in a self-supervised manner, with simple 3D bounding box annotations. To regress the pixel-related 3D object coordinates, we employ a regional reconstruction network with uncertainty awareness. For self-supervised training, the predicted 3D coordinates are projected back to the image plane. A Robust KL loss is proposed to minimize the uncertainty-weighted reprojection error. During testing phase, we exploit the network uncertainty by propagating it through all downstream modules. More specifically, the uncertainty-driven PnP algorithm is leveraged to estimate object pose and its covariance. Extensive experiments demonstrate that our proposed approach outperforms current state-of-the-art methods on KITTI benchmark.
SPFCN: Select and Prune the Fully Convolutional Networks for Real-time Parking Slot Detection
Mar 25, 2020
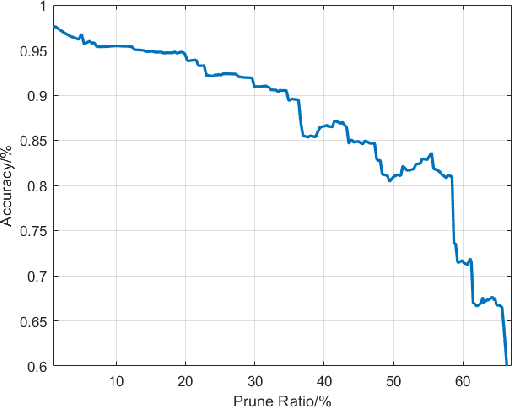
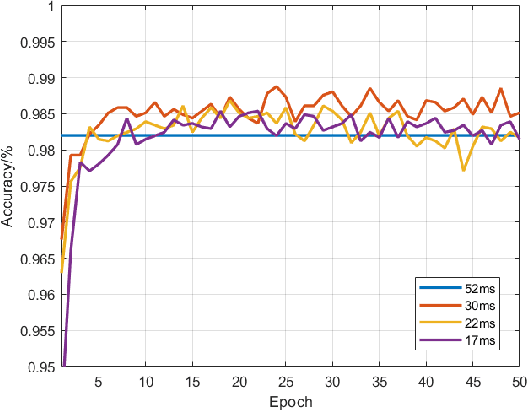
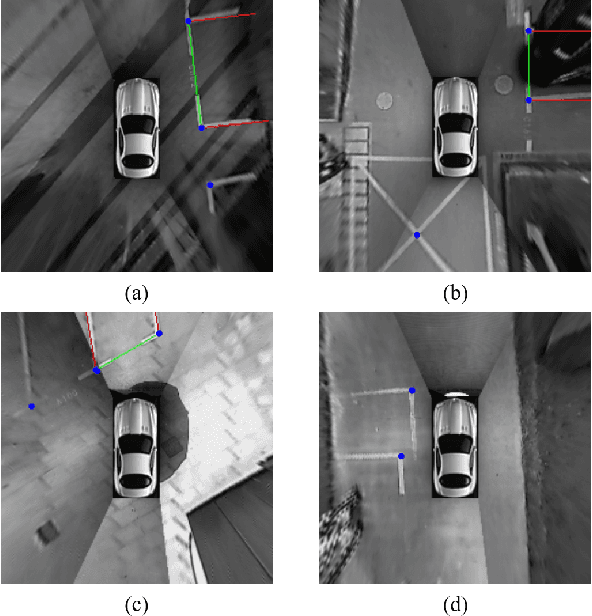
For passenger cars equipped with automatic parking function, convolutional neural networks are employed to detect parking slots on the panoramic surround view, which is an overhead image synthesized by four calibrated fish-eye images, The accuracy is obtained at the price of low speed or expensive computation equipments, which are sensitive for many car manufacturers. In this paper, the same accuracy is challenged by the proposed parking slot detector, which leverages deep convolutional networks for the faster speed and smaller model while keep the accuracy by simultaneously training and pruning it. To achieve the optimal trade-off, we developed a strategy to select the best receptive fields and prune the redundant channels automatically during training. The proposed model is capable of jointly detecting corners and line features of parking slots while running efficiently in real time on average CPU. Even without any specific computing devices, the model outperforms existing counterparts, at a frame rate of about 30 FPS on a 2.3 GHz CPU core, getting parking slot corner localization error of 1.51$\pm$2.14 cm (std. err.) and slot detection accuracy of 98\%, generally satisfying the requirements in both speed and accuracy on on-board mobile terminals.