 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Versatile Skills with Curriculum Masking
Paper and Code
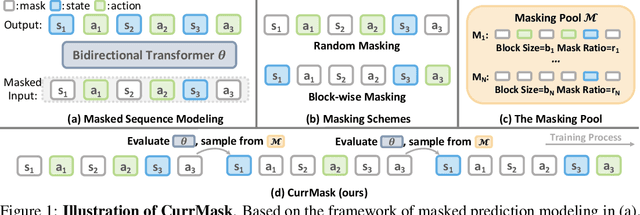
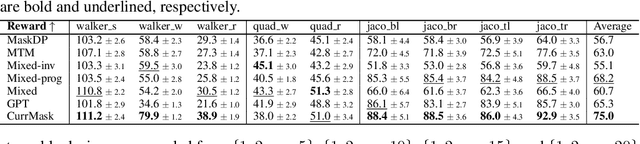
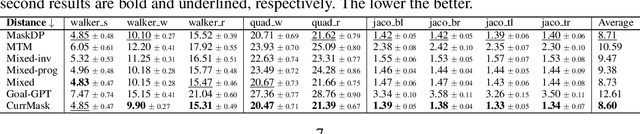
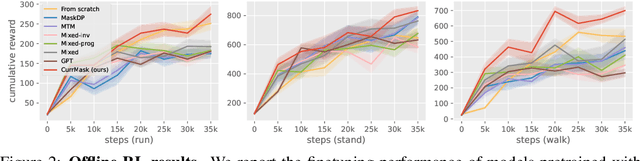
Masked prediction has emerged as a promising pretraining paradigm in offline reinforcement learning (RL) due to its versatile masking schemes, enabling flexible inference across various downstream tasks with a unified model. Despite the versatility of masked prediction, it remains unclear how to balance the learning of skills at different levels of complexity. To address this, we propose CurrMask, a curriculum masking pretraining paradigm for sequential decision making. Motivated by how humans learn by organizing knowledge in a curriculum, CurrMask adjusts its masking scheme during pretraining for learning versatile skills. Through extensive experiments, we show that CurrMask exhibits superior zero-shot performance on skill prompting tasks, goal-conditioned planning tasks, and competitive finetuning performance on offline RL tasks. Additionally, our analysis of training dynamics reveals that CurrMask gradually acquires skills of varying complexity by dynamically adjusting its masking scheme.