Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal generation of upper-facial and head gestures with a Transformer Network using speech and text
Paper and Code


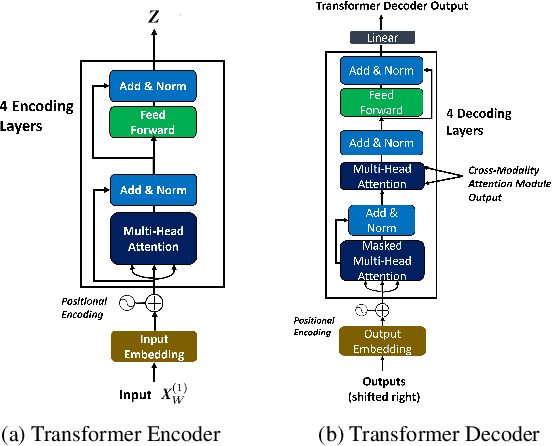
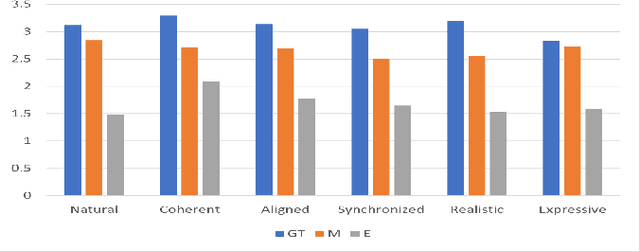
We propose a semantically-aware speech driven method to generate expressive and natural upper-facial and head motion for Embodied Conversational Agents (ECA). In this work, we tackle two key challenges: produce natural and continuous head motion and upper-facial gestures. We propose a model that generates gestures based on multimodal input features: the first modality is text, and the second one is speech prosody. Our model makes use of Transformers and Convolutions to map the multimodal features that correspond to an utterance to continuous eyebrows and head gestures. We conduct subjective and objective evaluations to validate our approach.
View paper on