 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA General Lie-Group Framework for Continuum Soft Robot Modeling
Mar 09, 2026This paper introduces a general Lie group framework for modeling continuum soft robots, employing Cosserat rod theory combined with cumulative parameterization on the Lie group SE(3). This novel approach addresses limitations present in current strain-based and configuration-based methods by providing geometric local control and eliminating unit quaternion constraints. The paper derives unified analytical expressions for kinematics, statics, and dynamics, including recursive Jacobian computations and an energy-conserving integrator suitable for real-time simulation and control. Additionally, the framework is extended to handle complex robotic structures, including segmented, branched, nested, and rigid-soft composite configurations, facilitating a modular and unified modeling strategy. The effectiveness, generality, and computational efficiency of the proposed methodology are demonstrated through various scenarios, including large-deformation rods, concentric tube robots, parallel robots, cable-driven robots, and articulated fingers. This work enhances modeling flexibility and numerical performance, providing an improved toolset for designing, simulating, and controlling soft robotic systems.
Constraint-Free Static Modeling of Continuum Parallel Robot
Mar 05, 2026Continuum parallel robots (CPR) combine rigid actuation mechanisms with multiple elastic rods in a closed-loop topology, making forward statics challenging when rigid--continuum junctions are enforced by explicit kinematic constraints. Such constraint-based formulations typically introduce additional algebraic variables and complicate both numerical solution and downstream control. This paper presents a geometric exact, configuration-based and constraint-free static model of CPR that remains valid under geometrically nonlinear, large-deformation and large-rotation conditions. Connectivity constraints are eliminated by kinematic embedding, yielding a reduced unconstrained problem. Each rod of CPR is discretized by nodal poses on SE(3), while the element-wise strain field is reconstructed through a linear strain parameterization. A fourth-order Magnus approximation yields an explicit and geometrically consistent mapping between element end poses and the strain. Rigid attachments at the motor-driven base and the end-effector platforms are handled through kinematic embeddings. Based on total potential energy and virtual work, we derive assembly-ready residuals and explicit Newton tangents, and solve the resulting nonlinear equilibrium equations using a Riemannian Newton iteration on the product manifold. Experiments on a three-servomotor, six-rod prototype validate the model by showing good agreement between simulation and measurements for both unloaded motions and externally loaded cases.
iMatcher: Improve matching in point cloud registration via local-to-global geometric consistency learning
Sep 10, 2025This paper presents iMatcher, a fully differentiable framework for feature matching in point cloud registration. The proposed method leverages learned features to predict a geometrically consistent confidence matrix, incorporating both local and global consistency. First, a local graph embedding module leads to an initialization of the score matrix. A subsequent repositioning step refines this matrix by considering bilateral source-to-target and target-to-source matching via nearest neighbor search in 3D space. The paired point features are then stacked together to be refined through global geometric consistency learning to predict a point-wise matching probability. Extensive experiments on real-world outdoor (KITTI, KITTI-360) and indoor (3DMatch) datasets, as well as on 6-DoF pose estimation (TUD-L) and partial-to-partial matching (MVP-RG), demonstrate that iMatcher significantly improves rigid registration performance. The method achieves state-of-the-art inlier ratios, scoring 95% - 97% on KITTI, 94% - 97% on KITTI-360, and up to 81.1% on 3DMatch, highlighting its robustness across diverse settings.
Geometrically-Aware One-Shot Skill Transfer of Category-Level Objects
Mar 19, 2025Robotic manipulation of unfamiliar objects in new environments is challenging and requires extensive training or laborious pre-programming. We propose a new skill transfer framework, which enables a robot to transfer complex object manipulation skills and constraints from a single human demonstration. Our approach addresses the challenge of skill acquisition and task execution by deriving geometric representations from demonstrations focusing on object-centric interactions. By leveraging the Functional Maps (FM) framework, we efficiently map interaction functions between objects and their environments, allowing the robot to replicate task operations across objects of similar topologies or categories, even when they have significantly different shapes. Additionally, our method incorporates a Task-Space Imitation Algorithm (TSIA) which generates smooth, geometrically-aware robot paths to ensure the transferred skills adhere to the demonstrated task constraints. We validate the effectiveness and adaptability of our approach through extensive experiments, demonstrating successful skill transfer and task execution in diverse real-world environments without requiring additional training.
LoGDesc: Local geometric features aggregation for robust point cloud registration
Oct 03, 2024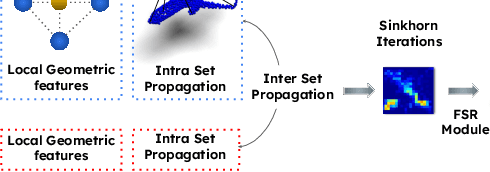
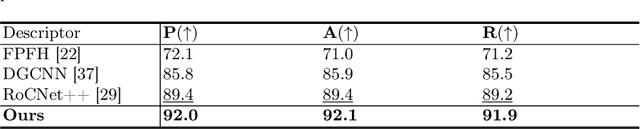
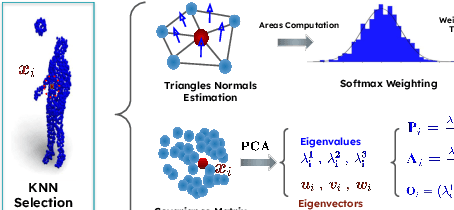
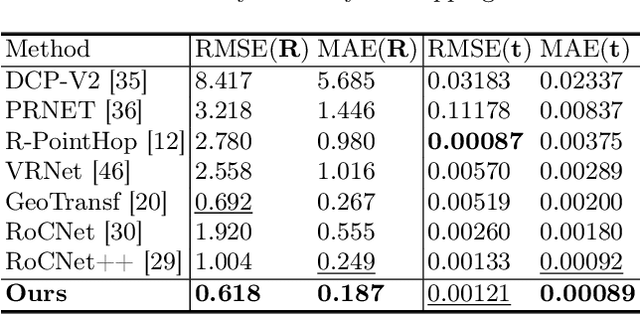
This paper introduces a new hybrid descriptor for 3D point matching and point cloud registration, combining local geometrical properties and learning-based feature propagation for each point's neighborhood structure description. The proposed architecture first extracts prior geometrical information by computing each point's planarity, anisotropy, and omnivariance using a Principal Components Analysis (PCA). This prior information is completed by a descriptor based on the normal vectors estimated thanks to constructing a neighborhood based on triangles. The final geometrical descriptor is propagated between the points using local graph convolutions and attention mechanisms. The new feature extractor is evaluated on ModelNet40, Bunny Stanford dataset, KITTI and MVP (Multi-View Partial)-RG for point cloud registration and shows interesting results, particularly on noisy and low overlapping point clouds.
Asservissement visuel 3D direct dans le domaine spectral
Apr 03, 2023This paper presents a direct 3D visual servo scheme for the automatic alignment of point clouds (respectively, objects) using visual information in the spectral domain. Specifically, we propose an alignment method for 3D models/point clouds that works by estimating the global transformation between a reference point cloud and a target point cloud using harmonic domain data analysis. A 3D discrete Fourier transform (DFT) in $\mathbb{R}^3$ is used for translation estimation and real spherical harmonics in $SO(3)$ are used for rotation estimation. This approach allows us to derive a decoupled visual servo controller with 6 degrees of freedom. We then show how this approach can be used as a controller for a robotic arm to perform a positioning task. Unlike existing 3D visual servo methods, our method works well with partial point clouds and in cases of large initial transformations between the initial and desired position. Additionally, using spectral data (instead of spatial data) for the transformation estimation makes our method robust to sensor-induced noise and partial occlusions. Our method has been successfully validated experimentally on point clouds obtained with a depth camera mounted on a robotic arm.
3D Spectral Domain Registration-Based Visual Servoing
Mar 28, 2023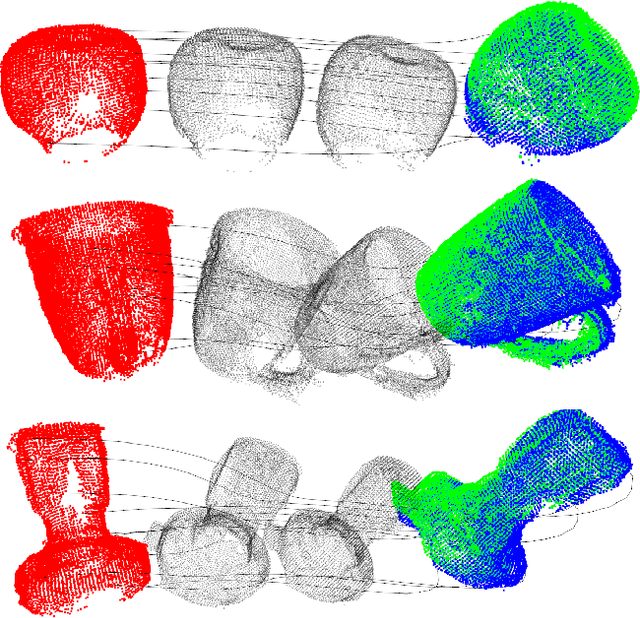
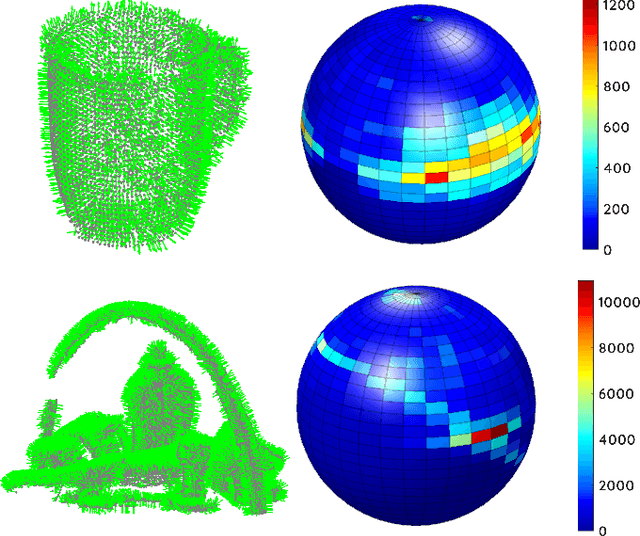
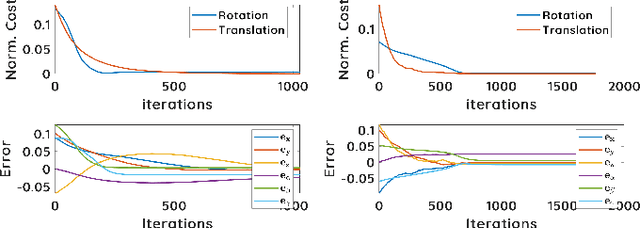
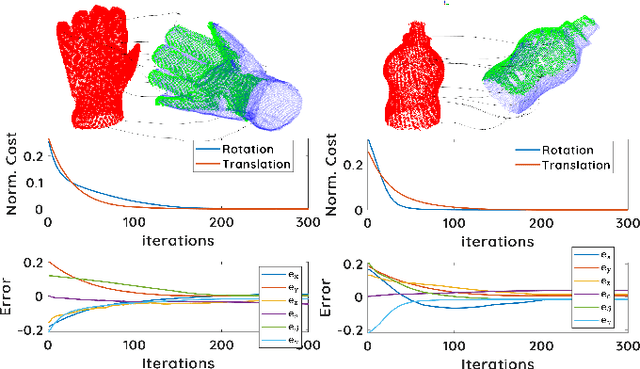
This paper presents a spectral domain registration-based visual servoing scheme that works on 3D point clouds. Specifically, we propose a 3D model/point cloud alignment method, which works by finding a global transformation between reference and target point clouds using spectral analysis. A 3D Fast Fourier Transform (FFT) in R3 is used for the translation estimation, and the real spherical harmonics in SO(3) are used for the rotations estimation. Such an approach allows us to derive a decoupled 6 degrees of freedom (DoF) controller, where we use gradient ascent optimisation to minimise translation and rotational costs. We then show how this methodology can be used to regulate a robot arm to perform a positioning task. In contrast to the existing state-of-the-art depth-based visual servoing methods that either require dense depth maps or dense point clouds, our method works well with partial point clouds and can effectively handle larger transformations between the reference and the target positions. Furthermore, the use of spectral data (instead of spatial data) for transformation estimation makes our method robust to sensor-induced noise and partial occlusions. We validate our approach by performing experiments using point clouds acquired by a robot-mounted depth camera. Obtained results demonstrate the effectiveness of our visual servoing approach.
RoCNet: 3D Robust Registration of Point-Clouds using Deep Learning
Mar 14, 2023This paper introduces a new method for 3D point cloud registration based on deep learning. The architecture is composed of three distinct blocs: (i) an encoder composed of a convolutional graph-based descriptor that encodes the immediate neighbourhood of each point and an attention mechanism that encodes the variations of the surface normals. Such descriptors are refined by highlighting attention between the points of the same set and then between the points of the two sets. (ii) a matching process that estimates a matrix of correspondences using the Sinkhorn algorithm. (iii) Finally, the rigid transformation between the two point clouds is calculated by RANSAC using the Kc best scores from the correspondence matrix. We conduct experiments on the ModelNet40 dataset, and our proposed architecture shows very promising results, outperforming state-of-the-art methods in most of the simulated configurations, including partial overlap and data augmentation with Gaussian noise.
Safe Path following for Middle Ear Surgery
Jan 03, 2023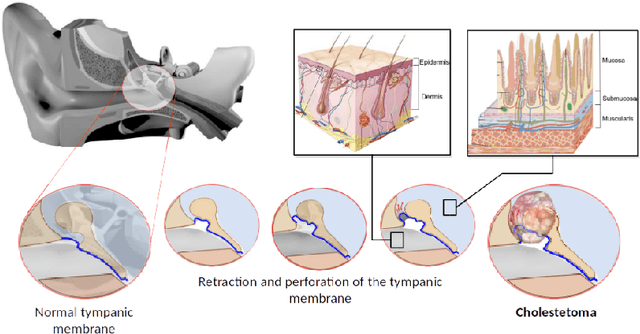


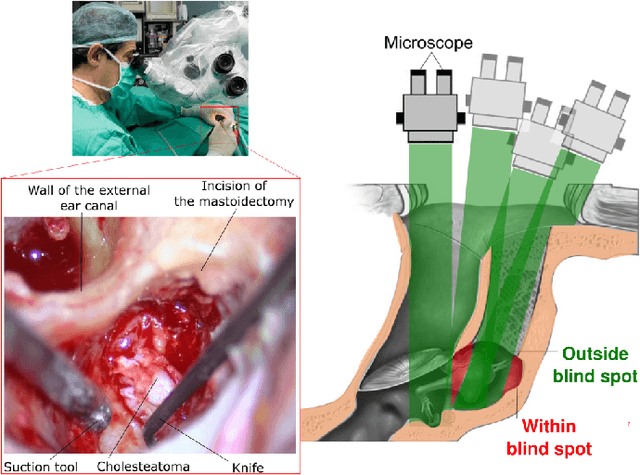
This article formulates a generic representation of a path-following controller operating under contained motion, which was developed in the context of surgical robotics. It reports two types of constrained motion: i) Bilateral Constrained Motion, also called Remote Center Motion (RCM), and ii) Unilaterally Constrained Motion (UCM). In the first case, the incision hole has almost the same diameter as the robotic tool. In contrast, in the second state, the diameter of the incision orifice is larger than the tool diameter. The second case offers more space where the surgical instrument moves freely without constraints before touching the incision wall. The proposed method combines two tasks that must operate hierarchically: i) respect the RCM or UCM constraints formulated by equality or inequality, respectively, and ii) perform a surgical assignment, e.g., scanning or ablation expressed as a 3D path-following task. The proposed methods and materials were tested first on our simulator that mimics realistic conditions of middle ear surgery, and then on an experimental platform. Different validation scenarios were carried out experimentally to assess quantitatively and qualitatively each developed approach. Although ultimate precision was not the goal of this work, our concept is validated with enough accuracy (inferior to 100 micrometres) for ear surgery.
Contributions à l'asservissement visuel et à l'imagerie en médecine
Aug 22, 2022
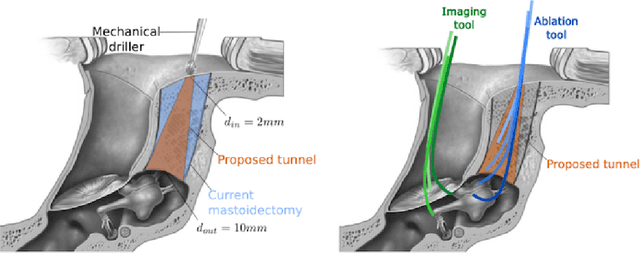
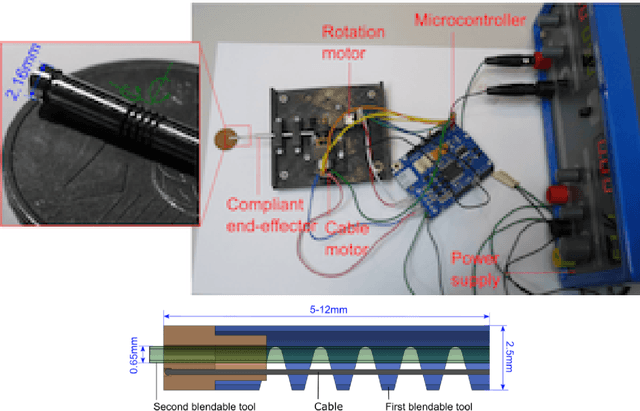
This manuscript gives an overview of my research work carried out within the FEMTO-ST institute in Besan\c{c}on, more particularly in the Automatic and Micro-Mechatronic Systems (AS2M) department. It is above all the result of my (co)-supervision of interns, PhD students and postdocs. I would like to pay tribute to them, for their major contribution to scientific research, here and elsewhere.