 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonoProb: Self-Supervised Monocular Depth Estimation with Interpretable Uncertainty
Nov 10, 2023



Self-supervised monocular depth estimation methods aim to be used in critical applications such as autonomous vehicles for environment analysis. To circumvent the potential imperfections of these approaches, a quantification of the prediction confidence is crucial to guide decision-making systems that rely on depth estimation. In this paper, we propose MonoProb, a new unsupervised monocular depth estimation method that returns an interpretable uncertainty, which means that the uncertainty reflects the expected error of the network in its depth predictions. We rethink the stereo or the structure-from-motion paradigms used to train unsupervised monocular depth models as a probabilistic problem. Within a single forward pass inference, this model provides a depth prediction and a measure of its confidence, without increasing the inference time. We then improve the performance on depth and uncertainty with a novel self-distillation loss for which a student is supervised by a pseudo ground truth that is a probability distribution on depth output by a teacher. To quantify the performance of our models we design new metrics that, unlike traditional ones, measure the absolute performance of uncertainty predictions. Our experiments highlight enhancements achieved by our method on standard depth and uncertainty metrics as well as on our tailored metrics. https://github.com/CEA-LIST/MonoProb
End-to-end Person Search Sequentially Trained on Aggregated Dataset
Jan 24, 2022

In video surveillance applications, person search is a challenging task consisting in detecting people and extracting features from their silhouette for re-identification (re-ID) purpose. We propose a new end-to-end model that jointly computes detection and feature extraction steps through a single deep Convolutional Neural Network architecture. Sharing feature maps between the two tasks for jointly describing people commonalities and specificities allows faster runtime, which is valuable in real-world applications. In addition to reaching state-of-the-art accuracy, this multi-task model can be sequentially trained task-by-task, which results in a broader acceptance of input dataset types. Indeed, we show that aggregating more pedestrian detection datasets without costly identity annotations makes the shared feature maps more generic, and improves re-ID precision. Moreover, these boosted shared feature maps result in re-ID features more robust to a cross-dataset scenario.
* 5 pages
Describe me if you can! Characterized Instance-level Human Parsing
Jan 24, 2022

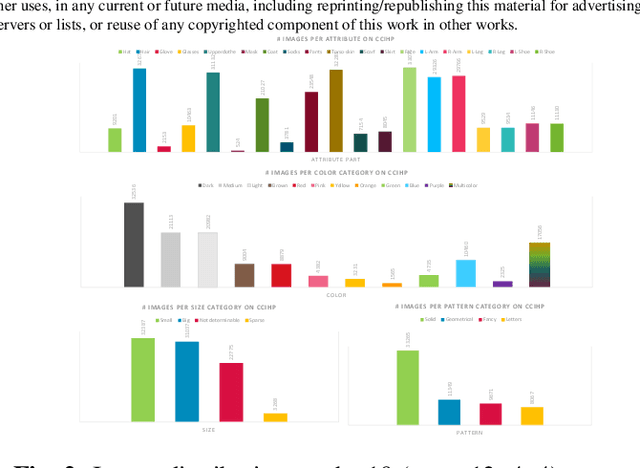
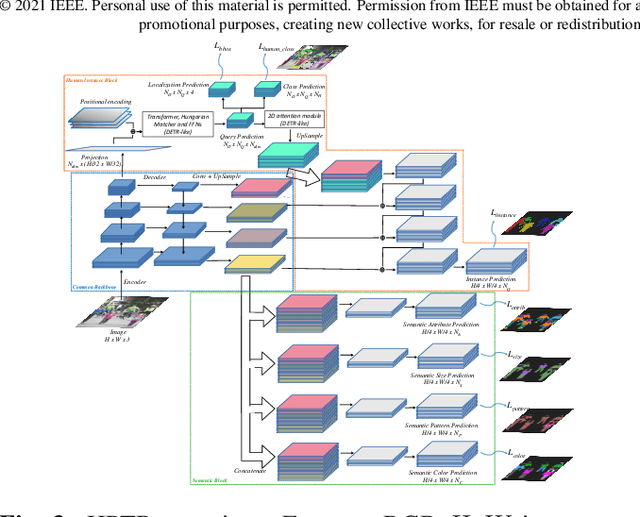
Several computer vision applications such as person search or online fashion rely on human description. The use of instance-level human parsing (HP) is therefore relevant since it localizes semantic attributes and body parts within a person. But how to characterize these attributes? To our knowledge, only some single-HP datasets describe attributes with some color, size and/or pattern characteristics. There is a lack of dataset for multi-HP in the wild with such characteristics. In this article, we propose the dataset CCIHP based on the multi-HP dataset CIHP, with 20 new labels covering these 3 kinds of characteristics. In addition, we propose HPTR, a new bottom-up multi-task method based on transformers as a fast and scalable baseline. It is the fastest method of multi-HP state of the art while having precision comparable to the most precise bottom-up method. We hope this will encourage research for fast and accurate methods of precise human descriptions.
* 5 pages
PaDiM: a Patch Distribution Modeling Framework for Anomaly Detection and Localization
Nov 17, 2020

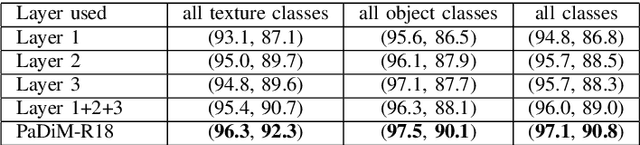
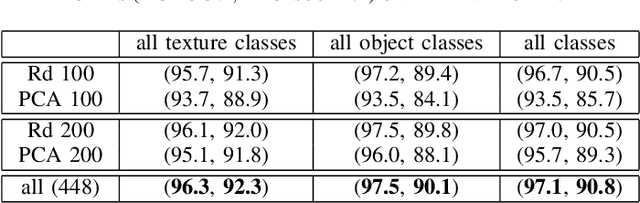
We present a new framework for Patch Distribution Modeling, PaDiM, to concurrently detect and localize anomalies in images in a one-class learning setting. PaDiM makes use of a pretrained convolutional neural network (CNN) for patch embedding, and of multivariate Gaussian distributions to get a probabilistic representation of the normal class. It also exploits correlations between the different semantic levels of CNN to better localize anomalies. PaDiM outperforms current state-of-the-art approaches for both anomaly detection and localization on the MVTec AD and STC datasets. To match real-world visual industrial inspection, we extend the evaluation protocol to assess performance of anomaly localization algorithms on non-aligned dataset. The state-of-the-art performance and low complexity of PaDiM make it a good candidate for many industrial applications.
Unsupervised Domain Adaptation for Person Re-Identification through Source-Guided Pseudo-Labeling
Sep 20, 2020
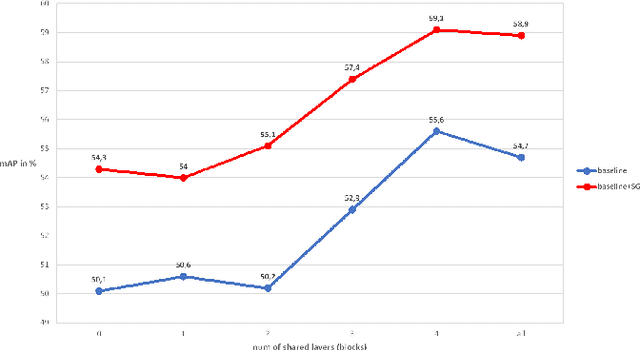
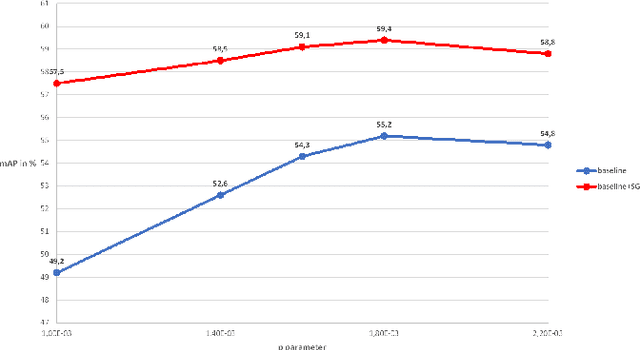
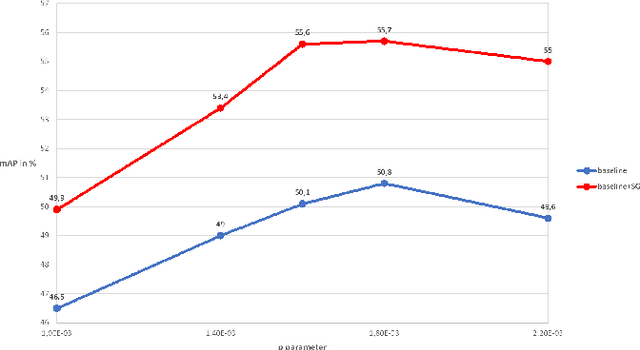
Person Re-Identification (re-ID) aims at retrieving images of the same person taken by different cameras. A challenge for re-ID is the performance preservation when a model is used on data of interest (target data) which belong to a different domain from the training data domain (source data). Unsupervised Domain Adaptation (UDA) is an interesting research direction for this challenge as it avoids a costly annotation of the target data. Pseudo-labeling methods achieve the best results in UDA-based re-ID. Surprisingly, labeled source data are discarded after this initialization step. However, we believe that pseudo-labeling could further leverage the labeled source data in order to improve the post-initialization training steps. In order to improve robustness against erroneous pseudo-labels, we advocate the exploitation of both labeled source data and pseudo-labeled target data during all training iterations. To support our guideline, we introduce a framework which relies on a two-branch architecture optimizing classification and triplet loss based metric learning in source and target domains, respectively, in order to allow \emph{adaptability to the target domain} while ensuring \emph{robustness to noisy pseudo-labels}. Indeed, shared low and mid-level parameters benefit from the source classification and triplet loss signal while high-level parameters of the target branch learn domain-specific features. Our method is simple enough to be easily combined with existing pseudo-labeling UDA approaches. We show experimentally that it is efficient and improves performance when the base method has no mechanism to deal with pseudo-label noise or for hard adaptation tasks. Our approach reaches state-of-the-art performance when evaluated on commonly used datasets, Market-1501 and DukeMTMC-reID, and outperforms the state of the art when targeting the bigger and more challenging dataset MSMT.