 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal Neural Network for Fitting and Forecasting COVID-19
Mar 22, 2021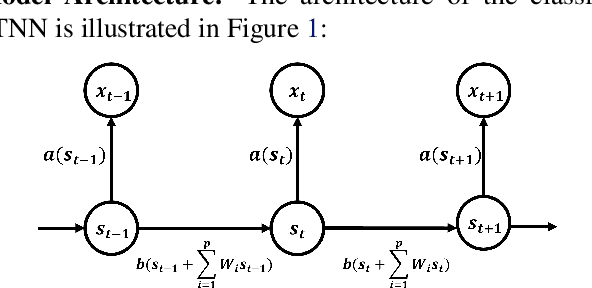

We established a Spatio-Temporal Neural Network, namely STNN, to forecast the spread of the coronavirus COVID-19 outbreak worldwide in 2020. The basic structure of STNN is similar to the Recurrent Neural Network (RNN) incorporating with not only temporal data but also spatial features. Two improved STNN architectures, namely the STNN with Augmented Spatial States (STNN-A) and the STNN with Input Gate (STNN-I), are proposed, which ensure more predictability and flexibility. STNN and its variants can be trained using Stochastic Gradient Descent (SGD) algorithm and its improved variants (e.g., Adam, AdaGrad and RMSProp). Our STNN models are compared with several classical epidemic prediction models, including the fully-connected neural network (BPNN), and the recurrent neural network (RNN), the classical curve fitting models, as well as the SEIR dynamical system model. Numerical simulations demonstrate that STNN models outperform many others by providing more accurate fitting and prediction, and by handling both spatial and temporal data.
Unsupervised Domain Adaptation for Person Re-Identification through Source-Guided Pseudo-Labeling
Sep 20, 2020
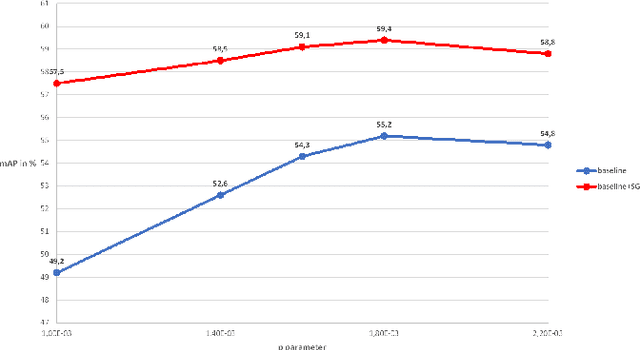
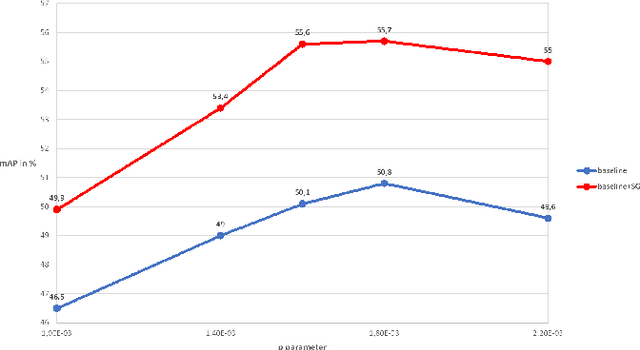
Person Re-Identification (re-ID) aims at retrieving images of the same person taken by different cameras. A challenge for re-ID is the performance preservation when a model is used on data of interest (target data) which belong to a different domain from the training data domain (source data). Unsupervised Domain Adaptation (UDA) is an interesting research direction for this challenge as it avoids a costly annotation of the target data. Pseudo-labeling methods achieve the best results in UDA-based re-ID. Surprisingly, labeled source data are discarded after this initialization step. However, we believe that pseudo-labeling could further leverage the labeled source data in order to improve the post-initialization training steps. In order to improve robustness against erroneous pseudo-labels, we advocate the exploitation of both labeled source data and pseudo-labeled target data during all training iterations. To support our guideline, we introduce a framework which relies on a two-branch architecture optimizing classification and triplet loss based metric learning in source and target domains, respectively, in order to allow \emph{adaptability to the target domain} while ensuring \emph{robustness to noisy pseudo-labels}. Indeed, shared low and mid-level parameters benefit from the source classification and triplet loss signal while high-level parameters of the target branch learn domain-specific features. Our method is simple enough to be easily combined with existing pseudo-labeling UDA approaches. We show experimentally that it is efficient and improves performance when the base method has no mechanism to deal with pseudo-label noise or for hard adaptation tasks. Our approach reaches state-of-the-art performance when evaluated on commonly used datasets, Market-1501 and DukeMTMC-reID, and outperforms the state of the art when targeting the bigger and more challenging dataset MSMT.
Brain tumor segmentation with missing modalities via latent multi-source correlation representation
Mar 19, 2020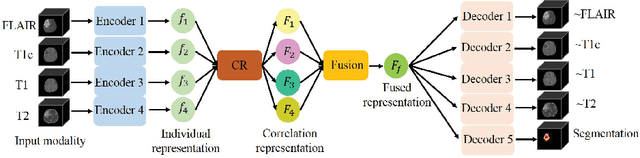
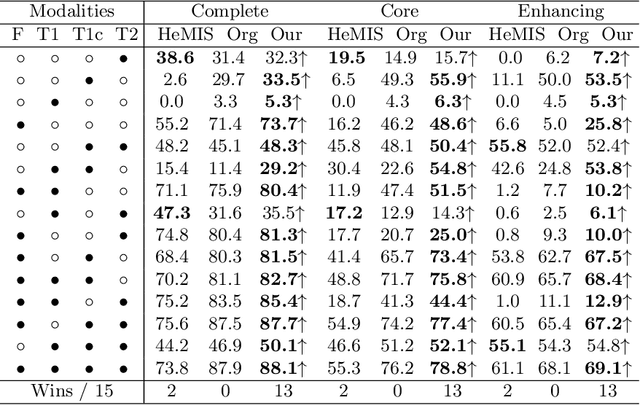
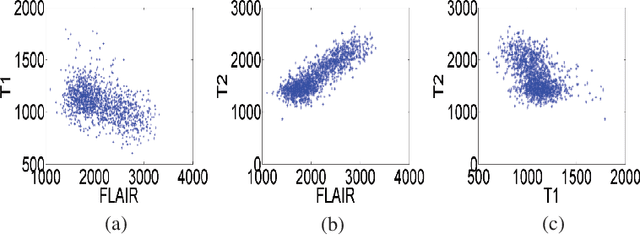
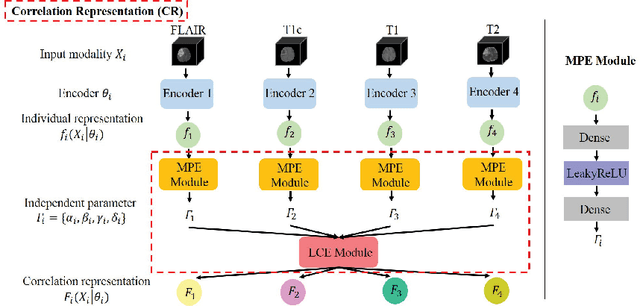
Multimodal MR images can provide complementary information for accurate brain tumor segmentation. However, it's common to have missing imaging modalities in clinical practice. Since it exists a strong correlation between multi modalities, a novel correlation representation block is proposed to specially discover the latent multi-source correlation. Thanks to the obtained correlation representation, the segmentation becomes more robust in the case of missing modality. The model parameter estimation module first maps the individual representation produced by each encoder to obtain independent parameters, then, under these parameters, correlation expression module transforms all the individual representations to form a latent multi-source correlation representation. Finally, the correlation representations across modalities are fused via attention mechanism into a shared representation to emphasize the most important features for segmentation. We evaluate our model on BraTS 2018 datasets, it outperforms the current state-of-the-art method and produces robust results when one or more modalities are missing.
L 1-norm double backpropagation adversarial defense
Mar 05, 2019



Adversarial examples are a challenging open problem for deep neural networks. We propose in this paper to add a penalization term that forces the decision function to be at in some regions of the input space, such that it becomes, at least locally, less sensitive to attacks. Our proposition is theoretically motivated and shows on a first set of carefully conducted experiments that it behaves as expected when used alone, and seems promising when coupled with adversarial training.
Non-convex Regularizations for Feature Selection in Ranking With Sparse SVM
Jul 02, 2015
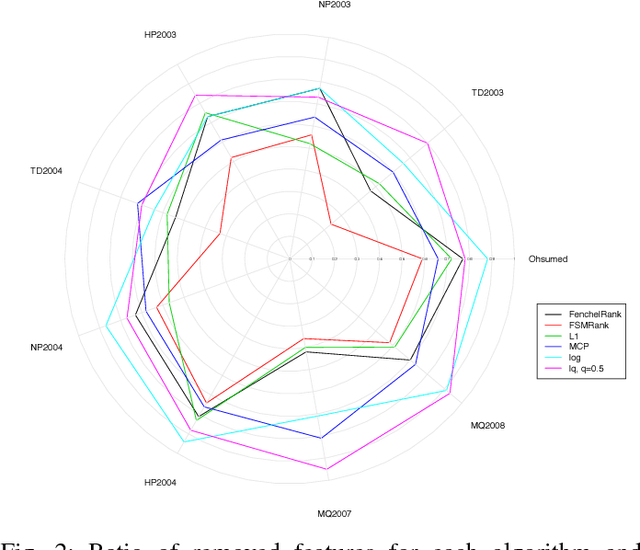
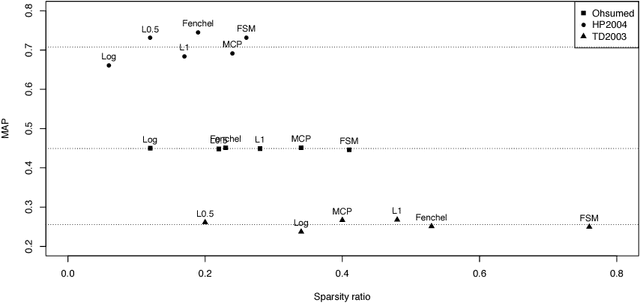

Feature selection in learning to rank has recently emerged as a crucial issue. Whereas several preprocessing approaches have been proposed, only a few works have been focused on integrating the feature selection into the learning process. In this work, we propose a general framework for feature selection in learning to rank using SVM with a sparse regularization term. We investigate both classical convex regularizations such as $\ell\_1$ or weighted $\ell\_1$ and non-convex regularization terms such as log penalty, Minimax Concave Penalty (MCP) or $\ell\_p$ pseudo norm with $p\textless{}1$. Two algorithms are proposed, first an accelerated proximal approach for solving the convex problems, second a reweighted $\ell\_1$ scheme to address the non-convex regularizations. We conduct intensive experiments on nine datasets from Letor 3.0 and Letor 4.0 corpora. Numerical results show that the use of non-convex regularizations we propose leads to more sparsity in the resulting models while prediction performance is preserved. The number of features is decreased by up to a factor of six compared to the $\ell\_1$ regularization. In addition, the software is publicly available on the web.
Functional learning through kernels
Oct 06, 2009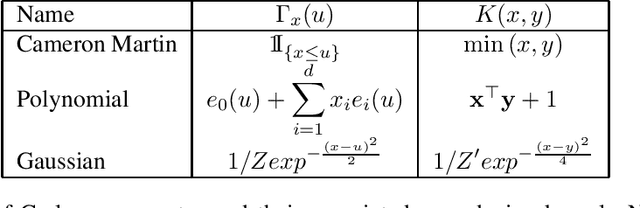

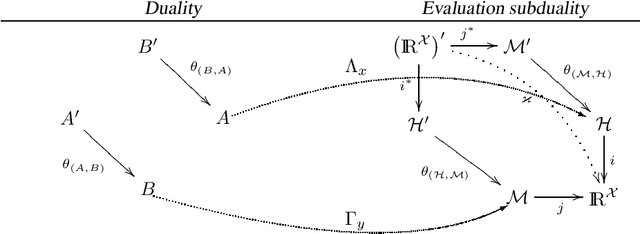
This paper reviews the functional aspects of statistical learning theory. The main point under consideration is the nature of the hypothesis set when no prior information is available but data. Within this framework we first discuss about the hypothesis set: it is a vectorial space, it is a set of pointwise defined functions, and the evaluation functional on this set is a continuous mapping. Based on these principles an original theory is developed generalizing the notion of reproduction kernel Hilbert space to non hilbertian sets. Then it is shown that the hypothesis set of any learning machine has to be a generalized reproducing set. Therefore, thanks to a general "representer theorem", the solution of the learning problem is still a linear combination of a kernel. Furthermore, a way to design these kernels is given. To illustrate this framework some examples of such reproducing sets and kernels are given.