 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Representations of Entities in Auto-regressive Large Language Models
Oct 10, 2025Named entities are fundamental building blocks of knowledge in text, grounding factual information and structuring relationships within language. Despite their importance, it remains unclear how Large Language Models (LLMs) internally represent entities. Prior research has primarily examined explicit relationships, but little is known about entity representations themselves. We introduce entity mention reconstruction as a novel framework for studying how LLMs encode and manipulate entities. We investigate whether entity mentions can be generated from internal representations, how multi-token entities are encoded beyond last-token embeddings, and whether these representations capture relational knowledge. Our proposed method, leveraging _task vectors_, allows to consistently generate multi-token mentions from various entity representations derived from the LLMs hidden states. We thus introduce the _Entity Lens_, extending the _logit-lens_ to predict multi-token mentions. Our results bring new evidence that LLMs develop entity-specific mechanisms to represent and manipulate any multi-token entities, including those unseen during training. Our code is avalable at https://github.com/VictorMorand/EntityRepresentations .
Curriculum Multi-Task Self-Supervision Improves Lightweight Architectures for Onboard Satellite Hyperspectral Image Segmentation
Sep 16, 2025



Hyperspectral imaging (HSI) captures detailed spectral signatures across hundreds of contiguous bands per pixel, being indispensable for remote sensing applications such as land-cover classification, change detection, and environmental monitoring. Due to the high dimensionality of HSI data and the slow rate of data transfer in satellite-based systems, compact and efficient models are required to support onboard processing and minimize the transmission of redundant or low-value data, e.g. cloud-covered areas. To this end, we introduce a novel curriculum multi-task self-supervised learning (CMTSSL) framework designed for lightweight architectures for HSI analysis. CMTSSL integrates masked image modeling with decoupled spatial and spectral jigsaw puzzle solving, guided by a curriculum learning strategy that progressively increases data complexity during self-supervision. This enables the encoder to jointly capture fine-grained spectral continuity, spatial structure, and global semantic features. Unlike prior dual-task SSL methods, CMTSSL simultaneously addresses spatial and spectral reasoning within a unified and computationally efficient design, being particularly suitable for training lightweight models for onboard satellite deployment. We validate our approach on four public benchmark datasets, demonstrating consistent gains in downstream segmentation tasks, using architectures that are over 16,000x lighter than some state-of-the-art models. These results highlight the potential of CMTSSL in generalizable representation learning with lightweight architectures for real-world HSI applications. Our code is publicly available at https://github.com/hugocarlesso/CMTSSL.
AgriPotential: A Novel Multi-Spectral and Multi-Temporal Remote Sensing Dataset for Agricultural Potentials
Jun 13, 2025Remote sensing has emerged as a critical tool for large-scale Earth monitoring and land management. In this paper, we introduce AgriPotential, a novel benchmark dataset composed of Sentinel-2 satellite imagery spanning multiple months. The dataset provides pixel-level annotations of agricultural potentials for three major crop types - viticulture, market gardening, and field crops - across five ordinal classes. AgriPotential supports a broad range of machine learning tasks, including ordinal regression, multi-label classification, and spatio-temporal modeling. The data covers diverse areas in Southern France, offering rich spectral information. AgriPotential is the first public dataset designed specifically for agricultural potential prediction, aiming to improve data-driven approaches to sustainable land use planning. The dataset and the code are freely accessible at: https://zenodo.org/records/15556484
Uncovering the Limitations of Query Performance Prediction: Failures, Insights, and Implications for Selective Query Processing
Apr 01, 2025Query Performance Prediction (QPP) estimates retrieval systems effectiveness for a given query, offering valuable insights for search effectiveness and query processing. Despite extensive research, QPPs face critical challenges in generalizing across diverse retrieval paradigms and collections. This paper provides a comprehensive evaluation of state-of-the-art QPPs (e.g. NQC, UQC), LETOR-based features, and newly explored dense-based predictors. Using diverse sparse rankers (BM25, DFree without and with query expansion) and hybrid or dense (SPLADE and ColBert) rankers and diverse test collections ROBUST, GOV2, WT10G, and MS MARCO; we investigate the relationships between predicted and actual performance, with a focus on generalization and robustness. Results show significant variability in predictors accuracy, with collections as the main factor and rankers next. Some sparse predictors perform somehow on some collections (TREC ROBUST and GOV2) but do not generalise to other collections (WT10G and MS-MARCO). While some predictors show promise in specific scenarios, their overall limitations constrain their utility for applications. We show that QPP-driven selective query processing offers only marginal gains, emphasizing the need for improved predictors that generalize across collections, align with dense retrieval architectures and are useful for downstream applications.
Investigating the Duality of Interpretability and Explainability in Machine Learning
Mar 27, 2025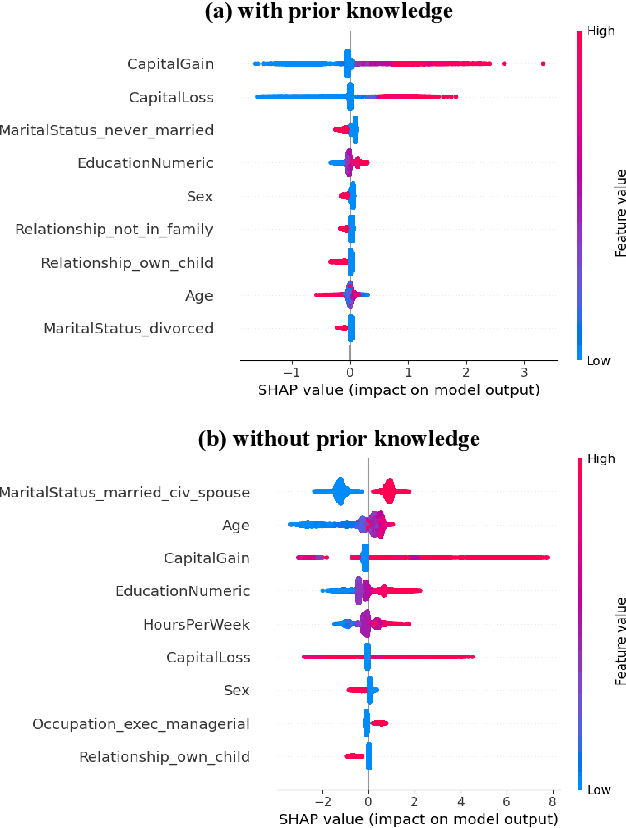
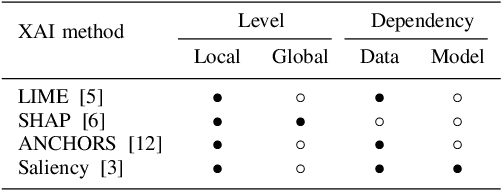
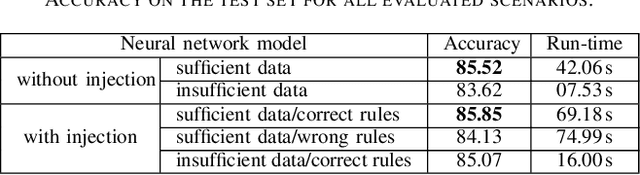

The rapid evolution of machine learning (ML) has led to the widespread adoption of complex "black box" models, such as deep neural networks and ensemble methods. These models exhibit exceptional predictive performance, making them invaluable for critical decision-making across diverse domains within society. However, their inherently opaque nature raises concerns about transparency and interpretability, making them untrustworthy decision support systems. To alleviate such a barrier to high-stakes adoption, research community focus has been on developing methods to explain black box models as a means to address the challenges they pose. Efforts are focused on explaining these models instead of developing ones that are inherently interpretable. Designing inherently interpretable models from the outset, however, can pave the path towards responsible and beneficial applications in the field of ML. In this position paper, we clarify the chasm between explaining black boxes and adopting inherently interpretable models. We emphasize the imperative need for model interpretability and, following the purpose of attaining better (i.e., more effective or efficient w.r.t. predictive performance) and trustworthy predictors, provide an experimental evaluation of latest hybrid learning methods that integrates symbolic knowledge into neural network predictors. We demonstrate how interpretable hybrid models could potentially supplant black box ones in different domains.
D4R -- Exploring and Querying Relational Graphs Using Natural Language and Large Language Models -- the Case of Historical Documents
Mar 26, 2025D4R is a digital platform designed to assist non-technical users, particularly historians, in exploring textual documents through advanced graphical tools for text analysis and knowledge extraction. By leveraging a large language model, D4R translates natural language questions into Cypher queries, enabling the retrieval of data from a Neo4J database. A user-friendly graphical interface allows for intuitive interaction, enabling users to navigate and analyse complex relational data extracted from unstructured textual documents. Originally designed to bridge the gap between AI technologies and historical research, D4R's capabilities extend to various other domains. A demonstration video and a live software demo are available.
Dense Retrieval for Low Resource Languages -- the Case of Amharic Language
Mar 24, 2025This paper reports some difficulties and some results when using dense retrievers on Amharic, one of the low-resource languages spoken by 120 millions populations. The efforts put and difficulties faced by University Addis Ababa toward Amharic Information Retrieval will be developed during the presentation.
PQPP: A Joint Benchmark for Text-to-Image Prompt and Query Performance Prediction
Jun 07, 2024



Text-to-image generation has recently emerged as a viable alternative to text-to-image retrieval, due to the visually impressive results of generative diffusion models. Although query performance prediction is an active research topic in information retrieval, to the best of our knowledge, there is no prior study that analyzes the difficulty of queries (prompts) in text-to-image generation, based on human judgments. To this end, we introduce the first dataset of prompts which are manually annotated in terms of image generation performance. In order to determine the difficulty of the same prompts in image retrieval, we also collect manual annotations that represent retrieval performance. We thus propose the first benchmark for joint text-to-image prompt and query performance prediction, comprising 10K queries. Our benchmark enables: (i) the comparative assessment of the difficulty of prompts/queries in image generation and image retrieval, and (ii) the evaluation of prompt/query performance predictors addressing both generation and retrieval. We present results with several pre-generation/retrieval and post-generation/retrieval performance predictors, thus providing competitive baselines for future research. Our benchmark and code is publicly available under the CC BY 4.0 license at https://github.com/Eduard6421/PQPP.
Adapting PromptORE for Modern History: Information Extraction from Hispanic Monarchy Documents of the XVIth Century
May 24, 2024Semantic relations among entities are a widely accepted method for relation extraction. PromptORE (Prompt-based Open Relation Extraction) was designed to improve relation extraction with Large Language Models on generalistic documents. However, it is less effective when applied to historical documents, in languages other than English. In this study, we introduce an adaptation of PromptORE to extract relations from specialized documents, namely digital transcripts of trials from the Spanish Inquisition. Our approach involves fine-tuning transformer models with their pretraining objective on the data they will perform inference. We refer to this process as "biasing". Our Biased PromptORE addresses complex entity placements and genderism that occur in Spanish texts. We solve these issues by prompt engineering. We evaluate our method using Encoder-like models, corroborating our findings with experts' assessments. Additionally, we evaluate the performance using a binomial classification benchmark. Our results show a substantial improvement in accuracy -up to a 50% improvement with our Biased PromptORE models in comparison to the baseline models using standard PromptORE.
Effectiveness and Efficiency Trade-off in Selective Query Processing
Feb 22, 2023Query processing in search engines can be optimized for use for all queries. For this, system component parameters such as the weighting function or the automatic query expansion model can be optimized or learned from past queries. However, it may be more interesting to optimize the processing thread on a query-by-query basis by adjusting the component parameters; this is what selective query processing does. Selective query processing uses one of the candidate processing threads chosen at query time. The choice is based on query features. In this paper, we examine selective query processing in different settings, both in terms of effectiveness and efficiency; this includes selective query expansion and other forms of selective query processing (e.g., when the term weighting function varies or when the expansion model varies). We found that the best trade-off between effectiveness and efficiency is obtained when using the best trained processing thread and its query expansion counter part. This seems to be also the most natural for a real-word engine since the two threads use the same core engine (e.g., same term weighting function).