 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering the Limitations of Query Performance Prediction: Failures, Insights, and Implications for Selective Query Processing
Apr 01, 2025Query Performance Prediction (QPP) estimates retrieval systems effectiveness for a given query, offering valuable insights for search effectiveness and query processing. Despite extensive research, QPPs face critical challenges in generalizing across diverse retrieval paradigms and collections. This paper provides a comprehensive evaluation of state-of-the-art QPPs (e.g. NQC, UQC), LETOR-based features, and newly explored dense-based predictors. Using diverse sparse rankers (BM25, DFree without and with query expansion) and hybrid or dense (SPLADE and ColBert) rankers and diverse test collections ROBUST, GOV2, WT10G, and MS MARCO; we investigate the relationships between predicted and actual performance, with a focus on generalization and robustness. Results show significant variability in predictors accuracy, with collections as the main factor and rankers next. Some sparse predictors perform somehow on some collections (TREC ROBUST and GOV2) but do not generalise to other collections (WT10G and MS-MARCO). While some predictors show promise in specific scenarios, their overall limitations constrain their utility for applications. We show that QPP-driven selective query processing offers only marginal gains, emphasizing the need for improved predictors that generalize across collections, align with dense retrieval architectures and are useful for downstream applications.
PQPP: A Joint Benchmark for Text-to-Image Prompt and Query Performance Prediction
Jun 07, 2024



Text-to-image generation has recently emerged as a viable alternative to text-to-image retrieval, due to the visually impressive results of generative diffusion models. Although query performance prediction is an active research topic in information retrieval, to the best of our knowledge, there is no prior study that analyzes the difficulty of queries (prompts) in text-to-image generation, based on human judgments. To this end, we introduce the first dataset of prompts which are manually annotated in terms of image generation performance. In order to determine the difficulty of the same prompts in image retrieval, we also collect manual annotations that represent retrieval performance. We thus propose the first benchmark for joint text-to-image prompt and query performance prediction, comprising 10K queries. Our benchmark enables: (i) the comparative assessment of the difficulty of prompts/queries in image generation and image retrieval, and (ii) the evaluation of prompt/query performance predictors addressing both generation and retrieval. We present results with several pre-generation/retrieval and post-generation/retrieval performance predictors, thus providing competitive baselines for future research. Our benchmark and code is publicly available under the CC BY 4.0 license at https://github.com/Eduard6421/PQPP.
Linguistic features for sentence difficulty prediction in ABSA
Feb 05, 2024One of the challenges of natural language understanding is to deal with the subjectivity of sentences, which may express opinions and emotions that add layers of complexity and nuance. Sentiment analysis is a field that aims to extract and analyze these subjective elements from text, and it can be applied at different levels of granularity, such as document, paragraph, sentence, or aspect. Aspect-based sentiment analysis is a well-studied topic with many available data sets and models. However, there is no clear definition of what makes a sentence difficult for aspect-based sentiment analysis. In this paper, we explore this question by conducting an experiment with three data sets: "Laptops", "Restaurants", and "MTSC" (Multi-Target-dependent Sentiment Classification), and a merged version of these three datasets. We study the impact of domain diversity and syntactic diversity on difficulty. We use a combination of classifiers to identify the most difficult sentences and analyze their characteristics. We employ two ways of defining sentence difficulty. The first one is binary and labels a sentence as difficult if the classifiers fail to correctly predict the sentiment polarity. The second one is a six-level scale based on how many of the top five best-performing classifiers can correctly predict the sentiment polarity. We also define 9 linguistic features that, combined, aim at estimating the difficulty at sentence level.
FreCDo: A Large Corpus for French Cross-Domain Dialect Identification
Dec 15, 2022
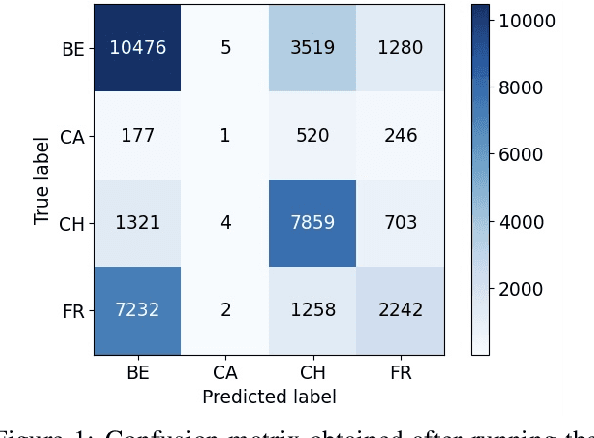

We present a novel corpus for French dialect identification comprising 413,522 French text samples collected from public news websites in Belgium, Canada, France and Switzerland. To ensure an accurate estimation of the dialect identification performance of models, we designed the corpus to eliminate potential biases related to topic, writing style, and publication source. More precisely, the training, validation and test splits are collected from different news websites, while searching for different keywords (topics). This leads to a French cross-domain (FreCDo) dialect identification task. We conduct experiments with four competitive baselines, a fine-tuned CamemBERT model, an XGBoost based on fine-tuned CamemBERT features, a Support Vector Machines (SVM) classifier based on fine-tuned CamemBERT features, and an SVM based on word n-grams. Aside from presenting quantitative results, we also make an analysis of the most discriminative features learned by CamemBERT. Our corpus is available at https://github.com/MihaelaGaman/FreCDo.