 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoMalDesc: Large-Scale Script Analysis for Cyber Threat Research
Nov 17, 2025Generating thorough natural language explanations for threat detections remains an open problem in cybersecurity research, despite significant advances in automated malware detection systems. In this work, we present AutoMalDesc, an automated static analysis summarization framework that, following initial training on a small set of expert-curated examples, operates independently at scale. This approach leverages an iterative self-paced learning pipeline to progressively enhance output quality through synthetic data generation and validation cycles, eliminating the need for extensive manual data annotation. Evaluation across 3,600 diverse samples in five scripting languages demonstrates statistically significant improvements between iterations, showing consistent gains in both summary quality and classification accuracy. Our comprehensive validation approach combines quantitative metrics based on established malware labels with qualitative assessment from both human experts and LLM-based judges, confirming both technical precision and linguistic coherence of generated summaries. To facilitate reproducibility and advance research in this domain, we publish our complete dataset of more than 100K script samples, including annotated seed (0.9K) and test (3.6K) datasets, along with our methodology and evaluation framework.
EMBERSim: A Large-Scale Databank for Boosting Similarity Search in Malware Analysis
Oct 03, 2023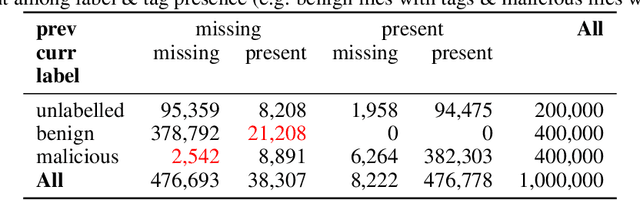
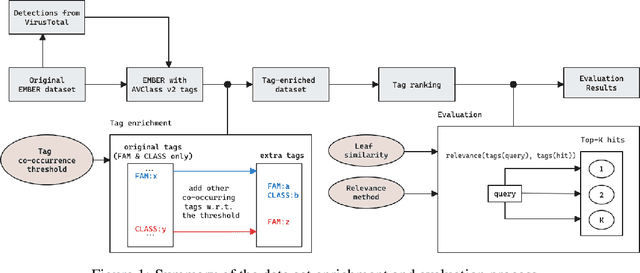
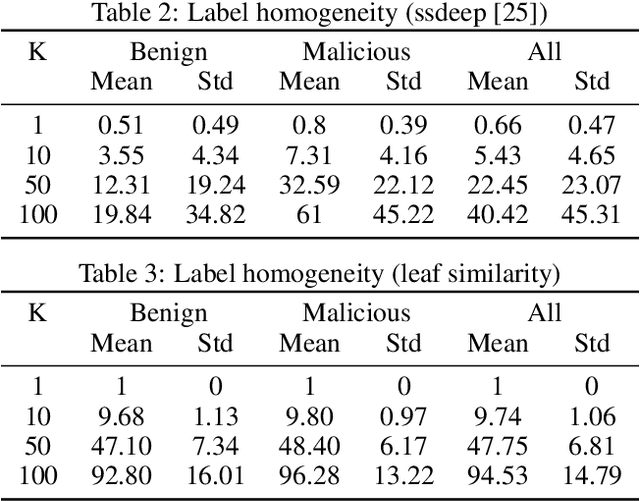
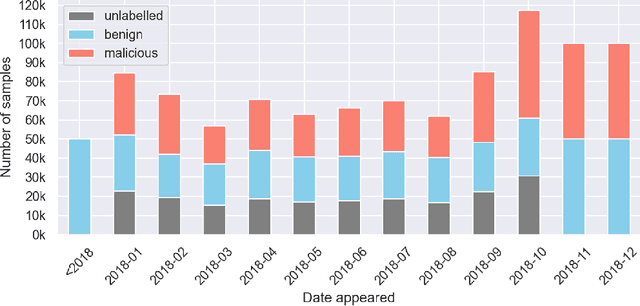
In recent years there has been a shift from heuristics-based malware detection towards machine learning, which proves to be more robust in the current heavily adversarial threat landscape. While we acknowledge machine learning to be better equipped to mine for patterns in the increasingly high amounts of similar-looking files, we also note a remarkable scarcity of the data available for similarity-targeted research. Moreover, we observe that the focus in the few related works falls on quantifying similarity in malware, often overlooking the clean data. This one-sided quantification is especially dangerous in the context of detection bypass. We propose to address the deficiencies in the space of similarity research on binary files, starting from EMBER - one of the largest malware classification data sets. We enhance EMBER with similarity information as well as malware class tags, to enable further research in the similarity space. Our contribution is threefold: (1) we publish EMBERSim, an augmented version of EMBER, that includes similarity-informed tags; (2) we enrich EMBERSim with automatically determined malware class tags using the open-source tool AVClass on VirusTotal data and (3) we describe and share the implementation for our class scoring technique and leaf similarity method.
FreCDo: A Large Corpus for French Cross-Domain Dialect Identification
Dec 15, 2022

We present a novel corpus for French dialect identification comprising 413,522 French text samples collected from public news websites in Belgium, Canada, France and Switzerland. To ensure an accurate estimation of the dialect identification performance of models, we designed the corpus to eliminate potential biases related to topic, writing style, and publication source. More precisely, the training, validation and test splits are collected from different news websites, while searching for different keywords (topics). This leads to a French cross-domain (FreCDo) dialect identification task. We conduct experiments with four competitive baselines, a fine-tuned CamemBERT model, an XGBoost based on fine-tuned CamemBERT features, a Support Vector Machines (SVM) classifier based on fine-tuned CamemBERT features, and an SVM based on word n-grams. Aside from presenting quantitative results, we also make an analysis of the most discriminative features learned by CamemBERT. Our corpus is available at https://github.com/MihaelaGaman/FreCDo.
Self-paced learning to improve text row detection in historical documents with missing labels
Feb 02, 2022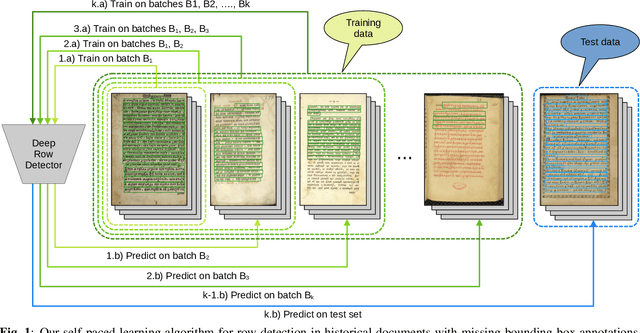
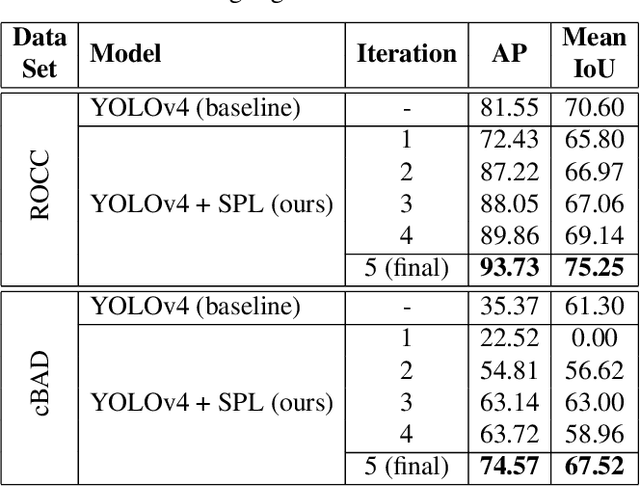

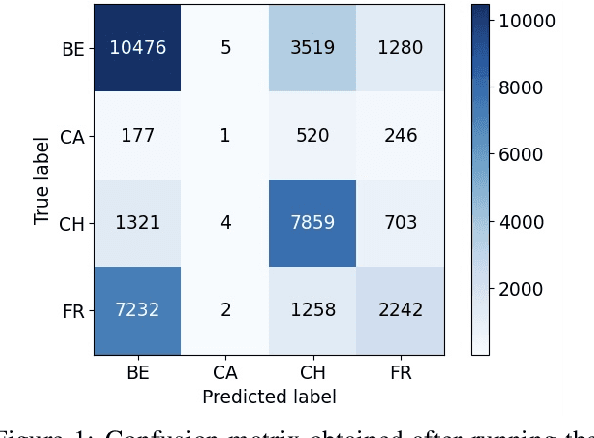
An important preliminary step of optical character recognition systems is the detection of text rows. To address this task in the context of historical data with missing labels, we propose a self-paced learning algorithm capable of improving the row detection performance. We conjecture that pages with more ground-truth bounding boxes are less likely to have missing annotations. Based on this hypothesis, we sort the training examples in descending order with respect to the number of ground-truth bounding boxes, and organize them into k batches. Using our self-paced learning method, we train a row detector over k iterations, progressively adding batches with less ground-truth annotations. At each iteration, we combine the ground-truth bounding boxes with pseudo-bounding boxes (bounding boxes predicted by the model itself) using non-maximum suppression, and we include the resulting annotations at the next training iteration. We demonstrate that our self-paced learning strategy brings significant performance gains on two data sets of historical documents, improving the average precision of YOLOv4 with more than 12% on one data set and 39% on the other.
SaRoCo: Detecting Satire in a Novel Romanian Corpus of News Articles
May 14, 2021


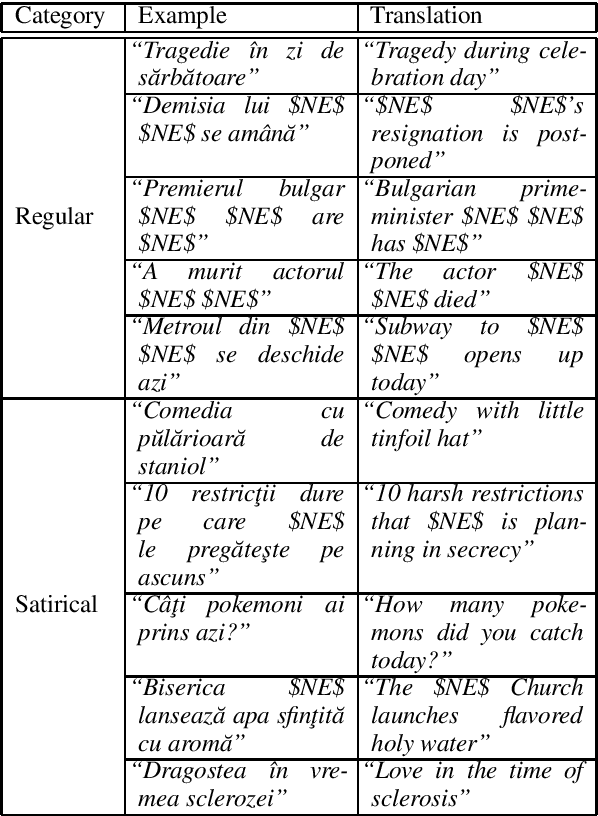
In this work, we introduce a corpus for satire detection in Romanian news. We gathered 55,608 public news articles from multiple real and satirical news sources, composing one of the largest corpora for satire detection regardless of language and the only one for the Romanian language. We provide an official split of the text samples, such that training news articles belong to different sources than test news articles, thus ensuring that models do not achieve high performance simply due to overfitting. We conduct experiments with two state-of-the-art deep neural models, resulting in a set of strong baselines for our novel corpus. Our results show that the machine-level accuracy for satire detection in Romanian is quite low (under 73% on the test set) compared to the human-level accuracy (87%), leaving enough room for improvement in future research.
UnibucKernel: Geolocating Swiss German Jodels Using Ensemble Learning
Feb 26, 2021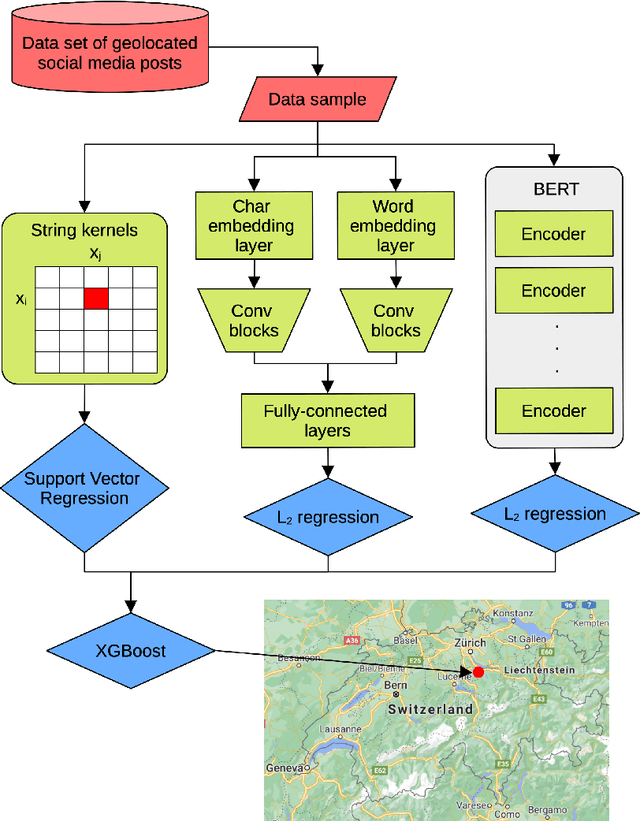
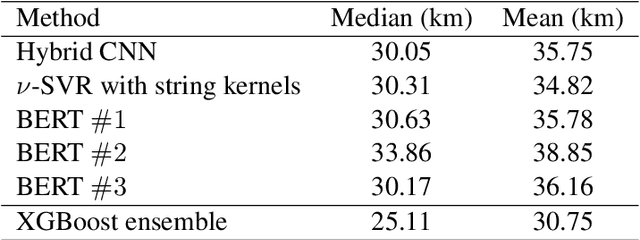
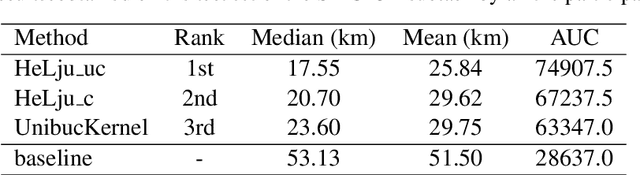
In this work, we describe our approach addressing the Social Media Variety Geolocation task featured in the 2021 VarDial Evaluation Campaign. We focus on the second subtask, which is based on a data set formed of approximately 30 thousand Swiss German Jodels. The dialect identification task is about accurately predicting the latitude and longitude of test samples. We frame the task as a double regression problem, employing an XGBoost meta-learner with the combined power of a variety of machine learning approaches to predict both latitude and longitude. The models included in our ensemble range from simple regression techniques, such as Support Vector Regression, to deep neural models, such as a hybrid neural network and a neural transformer. To minimize the prediction error, we approach the problem from a few different perspectives and consider various types of features, from low-level character n-grams to high-level BERT embeddings. The XGBoost ensemble resulted from combining the power of the aforementioned methods achieves a median distance of 23.6 km on the test data, which places us on the third place in the ranking, at a difference of 6.05 km and 2.9 km from the submissions on the first and second places, respectively.
Clustering Word Embeddings with Self-Organizing Maps. Application on LaRoSeDa -- A Large Romanian Sentiment Data Set
Jan 11, 2021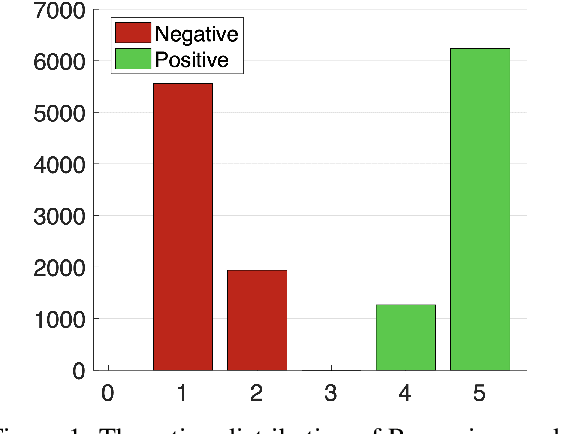
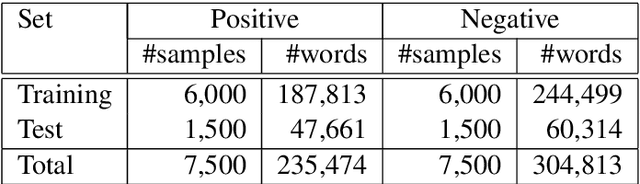
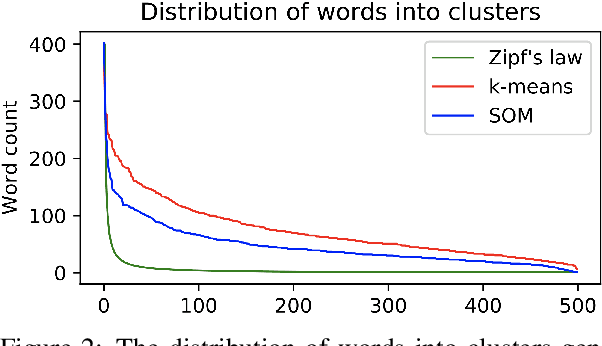
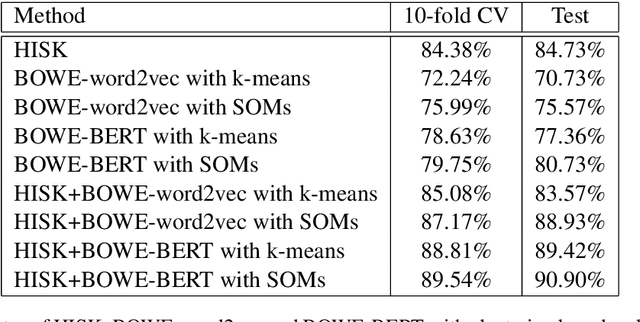
Romanian is one of the understudied languages in computational linguistics, with few resources available for the development of natural language processing tools. In this paper, we introduce LaRoSeDa, a Large Romanian Sentiment Data Set, which is composed of 15,000 positive and negative reviews collected from one of the largest Romanian e-commerce platforms. We employ two sentiment classification methods as baselines for our new data set, one based on low-level features (character n-grams) and one based on high-level features (bag-of-word-embeddings generated by clustering word embeddings with k-means). As an additional contribution, we replace the k-means clustering algorithm with self-organizing maps (SOMs), obtaining better results because the generated clusters of word embeddings are closer to the Zipf's law distribution, which is known to govern natural language. We also demonstrate the generalization capacity of using SOMs for the clustering of word embeddings on another recently-introduced Romanian data set, for text categorization by topic.
Combining Deep Learning and String Kernels for the Localization of Swiss German Tweets
Oct 07, 2020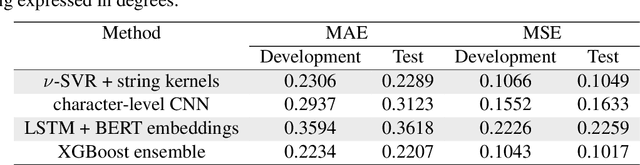
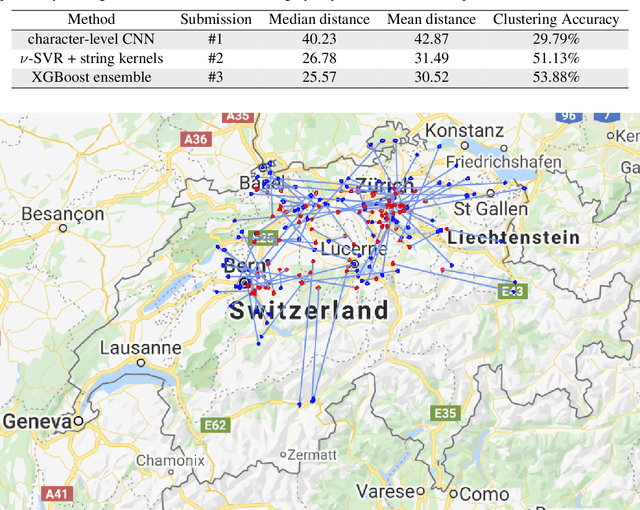
In this work, we introduce the methods proposed by the UnibucKernel team in solving the Social Media Variety Geolocation task featured in the 2020 VarDial Evaluation Campaign. We address only the second subtask, which targets a data set composed of nearly 30 thousand Swiss German Jodels. The dialect identification task is about accurately predicting the latitude and longitude of test samples. We frame the task as a double regression problem, employing a variety of machine learning approaches to predict both latitude and longitude. From simple models for regression, such as Support Vector Regression, to deep neural networks, such as Long Short-Term Memory networks and character-level convolutional neural networks, and, finally, to ensemble models based on meta-learners, such as XGBoost, our interest is focused on approaching the problem from a few different perspectives, in an attempt to minimize the prediction error. With the same goal in mind, we also considered many types of features, from high-level features, such as BERT embeddings, to low-level features, such as characters n-grams, which are known to provide good results in dialect identification. Our empirical results indicate that the handcrafted model based on string kernels outperforms the deep learning approaches. Nevertheless, our best performance is given by the ensemble model that combines both handcrafted and deep learning models.
Automatically Identifying Complaints in Social Media
Jun 10, 2019

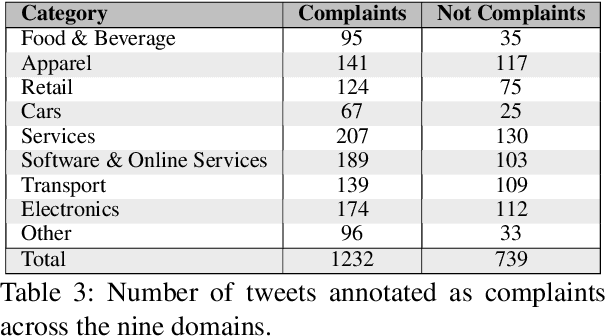
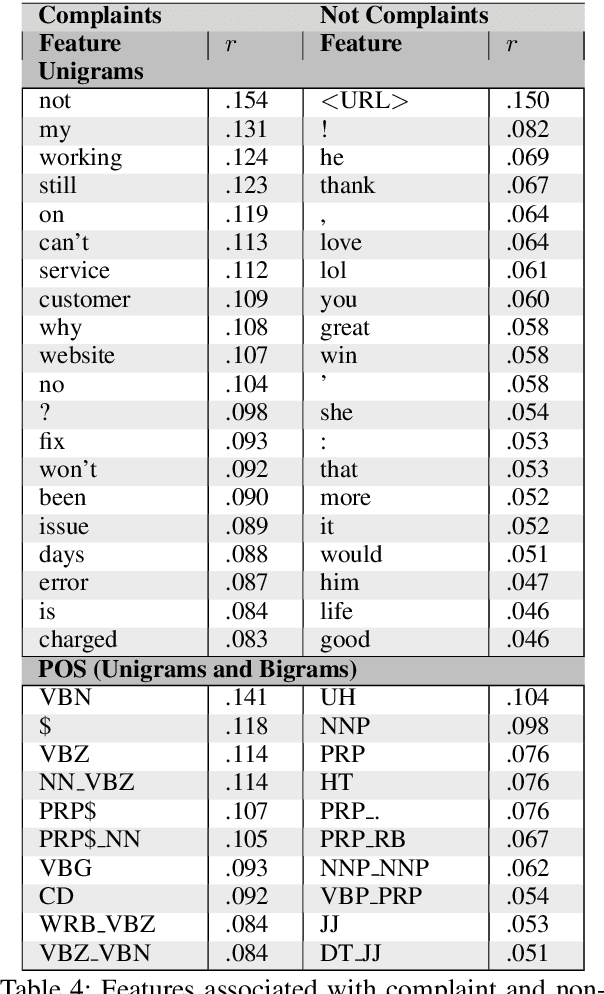
Complaining is a basic speech act regularly used in human and computer mediated communication to express a negative mismatch between reality and expectations in a particular situation. Automatically identifying complaints in social media is of utmost importance for organizations or brands to improve the customer experience or in developing dialogue systems for handling and responding to complaints. In this paper, we introduce the first systematic analysis of complaints in computational linguistics. We collect a new annotated data set of written complaints expressed in English on Twitter.\footnote{Data and code is available here: \url{https://github.com/danielpreotiuc/complaints-social-media}} We present an extensive linguistic analysis of complaining as a speech act in social media and train strong feature-based and neural models of complaints across nine domains achieving a predictive performance of up to 79 F1 using distant supervision.