 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Deep Learning and String Kernels for the Localization of Swiss German Tweets
Paper and Code
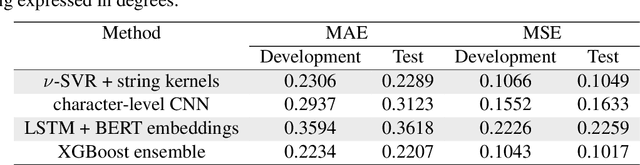
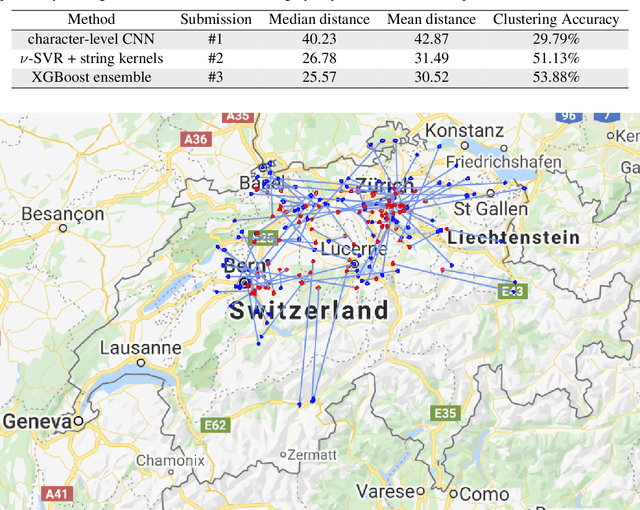
In this work, we introduce the methods proposed by the UnibucKernel team in solving the Social Media Variety Geolocation task featured in the 2020 VarDial Evaluation Campaign. We address only the second subtask, which targets a data set composed of nearly 30 thousand Swiss German Jodels. The dialect identification task is about accurately predicting the latitude and longitude of test samples. We frame the task as a double regression problem, employing a variety of machine learning approaches to predict both latitude and longitude. From simple models for regression, such as Support Vector Regression, to deep neural networks, such as Long Short-Term Memory networks and character-level convolutional neural networks, and, finally, to ensemble models based on meta-learners, such as XGBoost, our interest is focused on approaching the problem from a few different perspectives, in an attempt to minimize the prediction error. With the same goal in mind, we also considered many types of features, from high-level features, such as BERT embeddings, to low-level features, such as characters n-grams, which are known to provide good results in dialect identification. Our empirical results indicate that the handcrafted model based on string kernels outperforms the deep learning approaches. Nevertheless, our best performance is given by the ensemble model that combines both handcrafted and deep learning models.